En este artículo, discutiremos cómo contar distintos valores presentes en Pyspark DataFrame.
En Pyspark, hay dos formas de obtener el recuento de valores distintos. Podemos usar funciones distintivas() y conteo() de DataFrame para obtener el conteo distinto de PySpark DataFrame. Otra forma es usar la función SQL countDistinct() que proporcionará el recuento de valores distintos de todas las columnas seleccionadas. Comprendamos ambas formas de contar distintas de DataFrame con ejemplos.
Método 1: distinto().contar():
La distinción y el recuento son las dos funciones diferentes que se pueden aplicar a los marcos de datos. distingue() eliminará todos los valores o registros duplicados al verificar todas las columnas de una Fila de DataFrame y count() devolverá el recuento de registros en DataFrame. Al enstringr estas dos funciones una tras otra, podemos obtener el recuento distinto de PySpark DataFrame.
Ejemplo 1: Pyspark Count Distinct de DataFrame usando distint().count()
En este ejemplo, crearemos un DataFrame df que contiene detalles del Estudiante como Nombre, Curso y Marcas. El DataFrame también contiene algunos valores duplicados. Y aplicaremos el valor distinto(). Count() para descubrir todos los valores distintos que cuentan presentes en el DataFrame df.
Python3
# importing module
import pyspark
# importing sparksession from
# pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving
# app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# giving rows value for dataframe
data = [("Ram", "MCA", 80),
("Riya", "MBA", 85),
("Jiya", "B.E", 60),
("Maria", "B.Tech", 65),
("Shreya", "B.sc", 91),
("Ram", "MCA", 80),
("John", "M.E", 85),
("Shyam", "BA", 70),
("Kumar", "B.sc", 78),
("Maria", "B.Tech", 65)]
# giving column names of dataframe
columns = ["Name", "Course", "Marks"]
# creating a dataframe df
df = spark.createDataFrame(data, columns)
# show df
df.show()
# counting the total number of values
# in df
print("Total number of records in df:", df.count())
Producción:
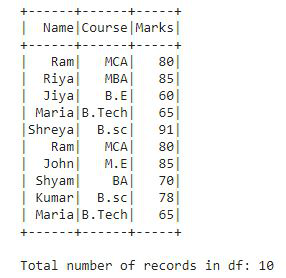
Este es el DataFrame df que hemos creado y contiene un total de 10 registros. Ahora, aplicamos distint().count() para averiguar el recuento total de valores distintos presente en el DataFrame df.
Python3
# applying distinct().count() on df
print('Distinct count in DataFrame df is :', df.distinct().count())
Producción:
Distinct count in DataFrame df is : 8
En esta salida, podemos ver que hay 8 valores distintos presentes en el DataFrame df.
Método 2: contarDistinto():
Esta función proporciona el conteo de distintos elementos presentes en un grupo de columnas seleccionadas. countDistinct() es una función SQL que proporcionará el recuento de valores distintos de todas las columnas seleccionadas.
Ejemplo 1: Pyspark Count Distinct de DataFrame usando countDistinct().
En este ejemplo, crearemos un DataFrame df que contiene detalles de empleados como Emp_name, Department y Salary. El DataFrame también contiene algunos valores duplicados. Y aplicaremos countDistinct() para descubrir todos los valores distintos que cuentan presentes en el DataFrame df.
Python3
# importing sparksession from
# pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving
# app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# giving rows value for dataframe
data = [("Ram", "IT", 80000),
("Shyam", "Sales", 70000),
("Jiya", "Sales", 60000),
("Maria", "Accounts", 65000),
("Ramesh", "IT", 80000),
("John", "Management", 80000),
("Shyam", "Sales", 70000),
("Kumar", "Sales", 78000),
("Maria", "Accounts", 65000)]
# giving column names of dataframe
columns = ["Emp_name", "Depart", "Salary"]
# creating a dataframe df
df = spark.createDataFrame(data, columns)
# show df
df.show()
# counting the total number of values in df
print("Total number of records in df:", df.count())
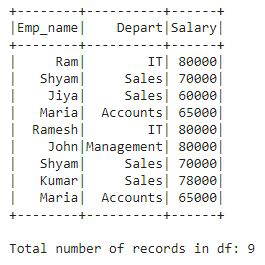
Este es el DataFrame df que hemos creado y contiene un total de 9 registros. Ahora, aplicaremos countDistinct() para averiguar el recuento total de valores distintos presente en el DataFrame df. Para aplicar esta función, importaremos la función desde el módulo pyspark.sql.functions.
Python3
# importing countDistinct from
# pyspark.sql.functions
from pyspark.sql.functions import countDistinct
# applying the function countDistinct()
# on df using select()
df2 = df.select(countDistinct("Emp_name", "Depart", "Salary"))
# show df2
df2.show()
Producción:
+----------------------------------------+ |count(DISTINCT Emp_name, Depart, Salary)| +----------------------------------------+ | 7| +----------------------------------------+
Hay 7 registros distintos presentes en DataFrame df. countDistinct() proporciona el valor de conteo distinto en el formato de columna como se muestra en el resultado, ya que es una función SQL.
Ahora, veamos el recuento de valores distintos en función de una columna en particular. Contaremos los distintos valores presentes en la columna Departamento de detalles de empleados df.
Python3
# importing countDistinct from
# pyspark.sql.functions
from pyspark.sql.functions import countDistinct
# applying the function countDistinct()
# on df using select()
df3 = df.select(countDistinct("Depart"))
# show df2
df3.show()
Producción:
+----------------------+ |count(DISTINCT Depart)| +----------------------+ | 4| +----------------------+
Hay 4 valores distintos presentes en la columna del departamento. En este ejemplo, hemos aplicado countDistinct() solo en la columna Salida.
Ejemplo 2: Pyspark Count Distinct from DataFrame mediante una consulta SQL.
En este ejemplo, hemos creado un marco de datos que contiene detalles del empleado como Emp_name, Depart, Age y Salary. Ahora, contaremos los distintos registros en el marco de datos utilizando una consulta SQL simple como la que usamos en SQL. Veamos el ejemplo y entendamos:
Python3
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# giving rows value for dataframe
data = [("Ram", "IT", 44, 80000),
("Shyam", "Sales", 45, 70000),
("Jiya", "Sales", 30, 60000),
("Maria", "Accounts", 29, 65000),
("Ram", "IT", 38, 80000),
("John", "Management", 35, 80000),
("Shyam", "Sales", 45, 70000),
("Kumar", "Sales", 27, 70000),
("Maria", "Accounts", 32, 65000),
("Ria", "Management", 32, 65000)]
# giving column names of dataframe
columns = ["Emp_name", "Depart", "Age", "Salary"]
# creating a dataframe df
df = spark.createDataFrame(data, columns)
# show df
df.show()
# counting the total number of values in df
print("Total number of records in df:", df.count())
Producción:
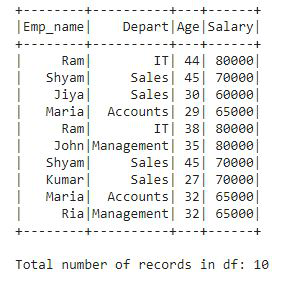
Este es el marco de datos que contiene un total de 10 registros junto con algunos registros duplicados también. Ahora, usaremos una consulta SQL y averiguaremos cuántos registros distintos se encuentran en este marco de datos. Es tan simple como lo hacemos en SQL.
Python3
# creating a temporary view of
# Dataframe and storing it into df2
df.createOrReplaceTempView("df2")
# using the SQL query to count all
# distinct records and display the
# count on the screen
spark.sql("select count(distinct(*)) from df2").show()
Producción:
+---------------------------------------------+ |count(DISTINCT Emp_name, Depart, Age, Salary)| +---------------------------------------------+ | 9| +---------------------------------------------+
Hay 9 registros distintos que se encuentran en todo el marco de datos df.
Ahora encontremos el recuento de valores distintos en dos columnas, es decir, Emp_name y Salary usando la siguiente consulta SQL.
Python3
# using the SQL query to count distinct
# records in 2 columns only display the
# count on the screen
spark.sql("select count(distinct(Emp_name, Salary)) from df2").show()
Producción:
+----------------------------------------------------------------+ |count(DISTINCT named_struct(Emp_name, Emp_name, Salary, Salary))| +----------------------------------------------------------------+ | 7| +----------------------------------------------------------------+
Hay 7 valores distintos que se encuentran en la columna Emp_name y Salary.
Como SQL proporciona la salida de todas las operaciones realizadas en los datos en formato tabular. Obtuvimos la respuesta en la columna que contiene dos filas, la primera fila tiene el encabezado y la segunda fila contiene un recuento distinto de registros. En el Ejemplo 2 también se obtuvo una salida en el mismo formato que countDistinct() también es una función SQL.
Publicación traducida automáticamente
Artículo escrito por neelutiwari y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA