En este artículo, cubriremos datos de inserción masiva desde un archivo csv usando el comando T-SQL en el servidor SQL. Y también cubrirá la forma en que es más útil y más conveniente para realizar este tipo de operaciones. Discutámoslo uno por uno.
Introducción:
a veces hay un escenario en el que tenemos que realizar una inserción masiva de datos de archivos .csv en la base de datos de SQL Server. Podemos usar la interfaz GUI en SSMS (SQL Server Management Studio) para importar datos de archivos Excel, CSV, etc. ¿Qué sucede si tenemos millones de datos para importar? Lo anterior será una tarea que llevará mucho tiempo, por lo que ahora verá cómo puede manejar este tipo de operaciones.
Nota:
Requiere los permisos INSERTAR y ADMINISTRAR OPERACIONES A GRANEL.
Enfoque alternativo:
aquí, en este artículo, proporcionaremos una alternativa más rápida a la anterior a través de unas pocas líneas del comando T-SQL.
BULK INSERT <DATABASE NAME>.<SCHEMA NAME>.<TABLE_NAME>
FROM '<FILE_PATH>'
WITH
(
-- input file format options
[ [ , ] FORMAT = 'CSV' ]
[ [ , ] FIELDQUOTE = 'quote_characters']
[ [ , ] FORMATFILE = 'format_file_path' ]
[ [ , ] FIELDTERMINATOR = 'field_terminator' ]
[ [ , ] ROWTERMINATOR = 'row_terminator' ]
)]
)
Los parámetros de entrada más utilizados son los siguientes.
- FIELDTERMINATOR: ‘
field_terminator’ se utiliza como separador entre campos. El terminador de campo predeterminado es \t (carácter de tabulación).
- ROWTERMINATOR:
‘row_terminator’ se usa para especificar el final de la fila. El terminador de fila predeterminado es \r\n (carácter de nueva línea).
Importación de un archivo CSV a una tabla SQL:
aquí, analizaremos la importación de un archivo CSV a una tabla en el servidor SQL. Considere el siguiente archivo CSV o puede usar su propio archivo csv para realizar esta operación. Intentemos importar un archivo csv en nuestra tabla SQL en SQL Server.
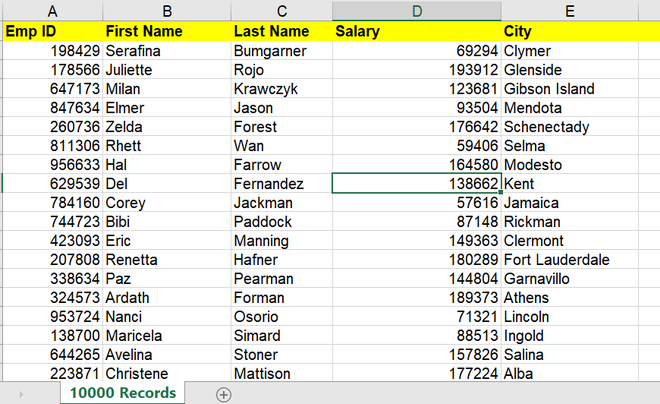
Ahora, creemos la tabla SQL para almacenar los datos anteriores.
Creando tabla –
Aquí. Crearemos el esquema de la tabla según los registros del archivo csv.
USE [Test]--Database name CREATE TABLE [dbo].[Employee]( [Emp ID] bigint primary key, [First Name] [varchar](50) NULL, [Last Name] [varchar](50) NULL, [Salary] bigint, [City] [varchar](50) )
Inserción masiva:
ahora insertemos el archivo de forma masiva en la tabla SQL del empleado:
BULK INSERT [Test].[dbo].[Employee]
FROM 'C:\data\employee_data.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
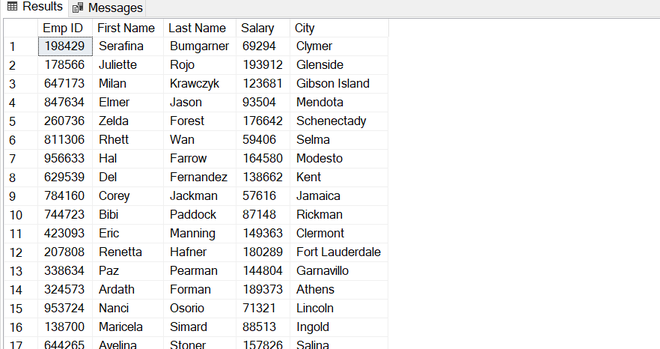
Salida:
después de ejecutar la operación anterior, podemos ver que los registros se han insertado con unas pocas líneas de código en la tabla de empleados, como se muestra a continuación.
Referencias:
para obtener más información sobre las opciones de formato de entrada, visite https://docs.microsoft.com/en-us/sql/t-sql/statements/bulk-insert-transact-sql?view=sql-server-2017 #opciones-de-formato-de-archivo-de-entrada.