En la indexación booleana, seleccionaremos subconjuntos de datos en función de los valores reales de los datos en el DataFrame y no en sus etiquetas de fila/columna o ubicaciones de enteros. En la indexación booleana, usamos un vector booleano para filtrar los datos.

La indexación booleana es un tipo de indexación que utiliza valores reales de los datos en el DataFrame. En la indexación booleana, podemos filtrar datos de cuatro maneras:
- Accediendo a un DataFrame con un índice booleano
- Aplicar una máscara booleana a un marco de datos
- Enmascaramiento de datos basado en el valor de la columna
- Enmascaramiento de datos basado en un valor de índice
Accediendo a un DataFrame con un índice booleano:
Para acceder a un marco de datos con un índice booleano, debemos crear un marco de datos en el que el índice del marco de datos contenga un valor booleano que sea «Verdadero» o «Falso».
Ejemplo
Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
df = pd.DataFrame(dict, index = [True, False, True, False])
print(df)
Producción:
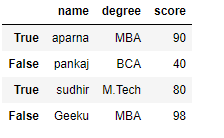
Ahora hemos creado un marco de datos con el índice booleano después de que el usuario pueda acceder a un marco de datos con la ayuda del índice booleano. El usuario puede acceder a un marco de datos usando tres funciones que son .loc[], .iloc[], .ix[]
Accediendo a un Dataframe con un índice booleano usando .loc[]
Para acceder a un marco de datos con un índice booleano usando .loc[], simplemente pasamos un valor booleano (Verdadero o Falso) en una función .loc[].
Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe with boolean index
df = pd.DataFrame(dict, index = [True, False, True, False])
# accessing a dataframe using .loc[] function
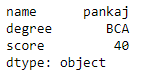
print(df.loc[True])
Producción:
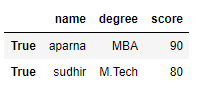
Accediendo a un Dataframe con un índice booleano usando .iloc[]
Para acceder a un marco de datos usando .iloc[], tenemos que pasar un valor booleano (Verdadero o Falso) pero la función iloc[] acepta solo números enteros como argumento, por lo que arrojará un error, por lo que solo podemos acceder a un marco de datos cuando pasar un entero en la función iloc[]
Código #1:
Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe with boolean index
df = pd.DataFrame(dict, index = [True, False, True, False])
# accessing a dataframe using .iloc[] function
print(df.iloc[True])
Producción:
TypeError
Código #2:
Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe with boolean index
df = pd.DataFrame(dict, index = [True, False, True, False])
# accessing a dataframe using .iloc[] function
print(df.iloc[1])
Producción:
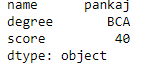
Accediendo a un Dataframe con un índice booleano usando .ix[]
Para acceder a un marco de datos usando .ix[], tenemos que pasar un valor booleano (Verdadero o Falso) y un valor entero a la función .ix[] porque, como sabemos, la función .ix[] es un híbrido de .loc[] y función .iloc[].
Código #1:
Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe with boolean index
df = pd.DataFrame(dict, index = [True, False, True, False])
# accessing a dataframe using .ix[] function
print(df.ix[True])
Producción:
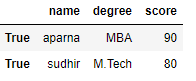
Código #2:
Python
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe with boolean index
df = pd.DataFrame(dict, index = [True, False, True, False])
# accessing a dataframe using .ix[] function
print(df.ix[1])
Producción:
Aplicar una máscara booleana a un marco de datos:
En un marco de datos, podemos aplicar una máscara booleana. Para hacer eso, podemos usar __getitems__ o [] accessor. Podemos aplicar una máscara booleana proporcionando una lista de Verdadero y Falso de la misma longitud que contiene un marco de datos. Cuando aplicamos una máscara booleana, imprimirá solo ese marco de datos en el que pasamos un valor booleano True. Para descargar el archivo CSV “ nba1.1 ”, haga clic aquí .
Código #1:
Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
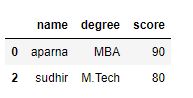
df = pd.DataFrame(dict, index = [0, 1, 2, 3])
print(df[[True, False, True, False]])
Producción:
Código #2:
Python3
# importing pandas package
import pandas as pd
# making data frame from csv file
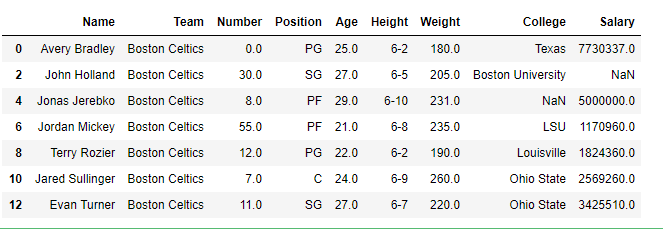
data = pd.read_csv("nba1.1.csv")
df = pd.DataFrame(data, index = [0, 1, 2, 3, 4, 5, 6,
7, 8, 9, 10, 11, 12])
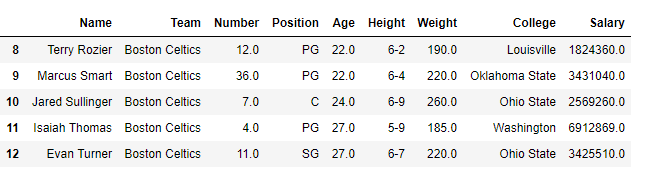
print(df[[True, False, True, False, True,
False, True, False, True, False,
True, False, True]])
Producción:
Enmascaramiento de datos basado en el valor de la columna:
En un marco de datos, podemos filtrar datos en función de un valor de columna. Para filtrar datos, podemos aplicar ciertas condiciones en el dataframe usando diferentes operadores como ==, >, <, <=, >=. Cuando aplicamos estos operadores al marco de datos, produce una Serie de Verdadero y Falso. Para descargar el CSV “nba.csv”, haga clic aquí .
Código #1:
Python
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["BCA", "BCA", "M.Tech", "BCA"],
'score':[90, 40, 80, 98]}
# creating a dataframe
df = pd.DataFrame(dict)
# using a comparison operator for filtering of data
print(df['degree'] == 'BCA')
Producción:

Código #2:
Python
# importing pandas package
import pandas as pd
# making data frame from csv file
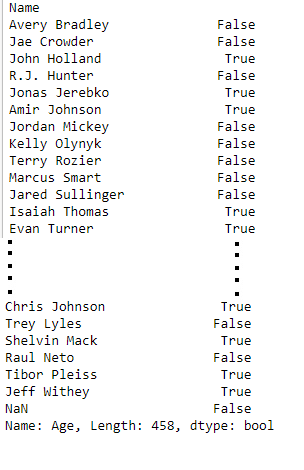
data = pd.read_csv("nba.csv", index_col ="Name")
# using greater than operator for filtering of data
print(data['Age'] > 25)
Producción:
Enmascaramiento de datos basado en el valor del índice:
En un marco de datos, podemos filtrar datos en función de un valor de columna. Para filtrar datos, podemos crear una máscara basada en los valores del índice usando diferentes operadores como ==, >, <, etc…. Para descargar el archivo CSV “ nba1.1 ”, haga clic aquí .
Código #1:
Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["BCA", "BCA", "M.Tech", "BCA"],
'score':[90, 40, 80, 98]}
df = pd.DataFrame(dict, index = [0, 1, 2, 3])
mask = df.index == 0
print(df[mask])
Producción:

Código #2:
Python3
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba1.1.csv")
# giving a index to a dataframe
df = pd.DataFrame(data, index = [0, 1, 2, 3, 4, 5, 6,
7, 8, 9, 10, 11, 12])
# filtering data on index value
mask = df.index > 7
print(df[mask])
Producción:
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA