En este artículo veremos cómo filtrar un DataFrame de Pandas por la suma de filas o columnas. Esto puede ser útil en algunas condiciones. Supongamos que tiene un marco de datos que consta de clientes y sus frutas compradas. Las filas constan de diferentes clientes y las columnas contienen diferentes tipos de frutas. Desea filtrar el marco de datos en función de sus compras. Para obtener más información sobre cómo filtrar Pandas DataFrame por valores de columna y filas según las condiciones, consulte los enlaces del artículo. Se ha utilizado la función pandas dataframe.sum() para devolver la suma de los valores.
Pasos necesarios:
- Crear o importar el marco de datos
- Suma las filas: Esto se puede hacer usando la función .sum() y pasando el parámetro axis=1
- Sume las columnas: Usando la función .sum() y pasando el parámetro axis=0
- Filtrado en base a las condiciones requeridas
Filtrado en base a la suma de filas y columnas
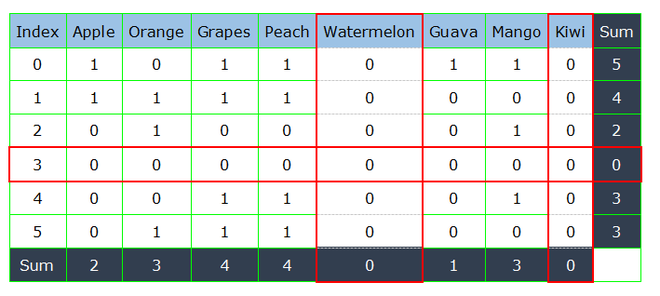
Si desea eliminar los clientes que no compraron ninguna fruta o alguna fruta en particular que no fue comprada por ningún cliente. En este caso, debemos filtrar en función de los valores de la suma de filas o columnas. A continuación se muestra la implementación del código del enfoque propuesto anteriormente.
Python3
# importing pandas library
import pandas as pd
# creating dataframe
df = pd.DataFrame({'Apple': [1, 1, 0, 0, 0, 0],
'Orange': [0, 1, 1, 0, 0, 1],
'Grapes': [1, 1, 0, 0, 1, 1],
'Peach': [1, 1, 0, 0, 1, 1],
'Watermelon': [0, 0, 0, 0, 0, 0],
'Guava': [1, 0, 0, 0, 0, 0],
'Mango': [1, 0, 1, 0, 1, 0],
'Kiwi': [0, 0, 0, 0, 0, 0]})
print("Dataframe before filtering\n")
print(df)
# filtering on the basis of rows
df = df[df.sum(axis=1) > 0]
# filtering on the basis of columns
df = df.loc[:, df.sum(axis=0) > 0]
print("\nDataframe after filtering\n")
print(df)
Producción:
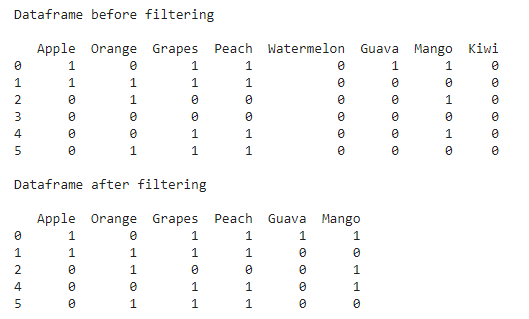
Filtrado de filas sobre la base de la suma de algunas columnas
Ahora bien, si queremos filtrar aquellos clientes que no compraron ninguna de las frutas de una lista limitada, por ejemplo, los clientes que no compraron uva, guayaba o durazno deben eliminarse del marco de datos. Aquí, filtramos las filas sobre la base de ciertas columnas que son uva, melocotón y guayaba en este caso.
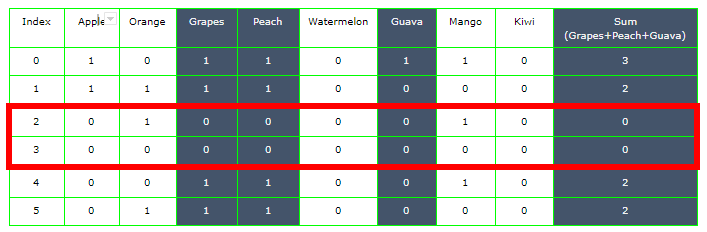
Al calcular la suma de todas las filas de estas tres columnas, encontramos que la suma es cero para los índices 2 y 3.
Python3
# importing pandas library
import pandas as pd
# creating dataframe
df = pd.DataFrame({'Apple': [1, 1, 0, 0, 0, 0],
'Orange': [0, 1, 1, 0, 0, 1],
'Grapes': [1, 1, 0, 0, 1, 1],
'Peach': [1, 1, 0, 0, 1, 1],
'Watermelon': [0, 0, 0, 0, 0, 0],
'Guava': [1, 0, 0, 0, 0, 0],
'Mango': [1, 0, 1, 0, 1, 0],
'Kiwi': [0, 0, 0, 0, 0, 0]})
print("Dataframe before filtering\n")
print(df)
# list of columns to be considered
columns = ['Grapes', 'Guava', 'Peach']
# filtering rows on basis of certain columns
df = df[df[columns].sum(axis=1) > 0]
print("\nDataframe after filtering\n")
print(df)
Producción:
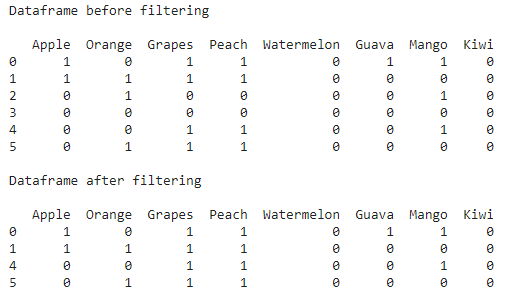
Filtrado de algunas columnas de todo el conjunto de datos en función de su suma
Si desea eliminar cualquiera de las columnas de una lista de columnas que tiene una suma igual a cero. Solo sumamos esas columnas y les aplicamos la condición.
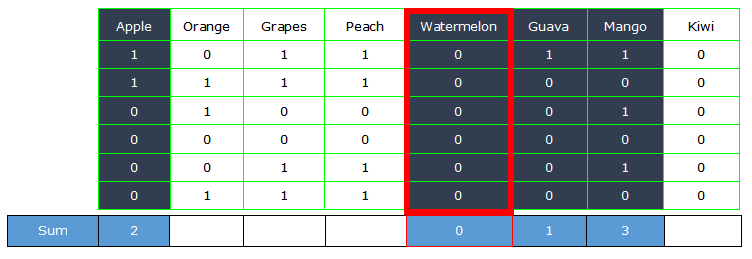
Python3
# importing pandas library
import pandas as pd
# creating dataframe
df = pd.DataFrame({'Apple': [1, 1, 0, 0, 0, 0],
'Orange': [0, 1, 1, 0, 0, 1],
'Grapes': [1, 1, 0, 0, 1, 1],
'Peach': [1, 1, 0, 0, 1, 1],
'Watermelon': [0, 0, 0, 0, 0, 0],
'Guava': [1, 0, 0, 0, 0, 0],
'Mango': [1, 0, 1, 0, 1, 0],
'Kiwi': [0, 0, 0, 0, 0, 0]})
print("Dataframe before filtering\n")
print(df)
# list of columns to be considered
columns = ['Apple', 'Mango', 'Guava', 'Watermelon']
# iterating through the columns and dropping
# columns with sum less than equals to 0
for column in columns:
if (df[column].sum() <= 0):
df.drop(column, inplace=True, axis=1)
print("\nDataframe after filtering\n")
print(df)
Producción:
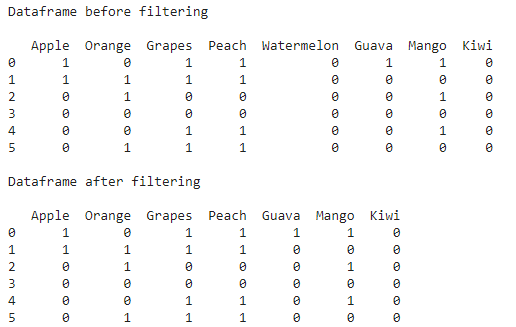
De esta forma, podemos modificar nuestro marco de datos en Pandas según algunas situaciones aplicando algunas condiciones en filas y columnas.