Los datos juegan un papel clave en la construcción del aprendizaje automático y el modelo de IA. En el mundo actual, donde los datos se generan a un ritmo astronómico por cada dispositivo informático y sensores, es importante manejar grandes volúmenes de datos correctamente. Una de las formas más comunes de almacenar datos es en forma de valores separados por comas (CSV) . La importación directa de una gran cantidad de datos conduce a un error de falta de memoria y la lectura del archivo completo a la vez provoca fallas en el sistema debido a una memoria RAM insuficiente.
Las siguientes son algunas formas de manejar con eficacia archivos de datos grandes en formato .csv. El conjunto de datos que vamos a utilizar es gender_voice_dataset .
Usando pandas.read_csv (tamaño de fragmento)
Una forma de procesar archivos grandes es leer las entradas en fragmentos de tamaño razonable, que se leen en la memoria y se procesan antes de leer el fragmento siguiente. Podemos usar el parámetro de tamaño de fragmento para especificar el tamaño del fragmento, que es el número de líneas. Esta función devuelve un iterador que se usa para iterar a través de estos fragmentos y luego los procesa. Dado que solo se lee una parte del archivo a la vez, la poca memoria es suficiente para el procesamiento.
El siguiente es el código para leer entradas en fragmentos.
chunk = pandas.read_csv(filename,chunksize=...)
El siguiente código muestra el tiempo necesario para leer un conjunto de datos sin usar fragmentos:
Python3
# import required modules
import pandas as pd
import numpy as np
import time
# time taken to read data
s_time = time.time()
df = pd.read_csv("gender_voice_dataset.csv")
e_time = time.time()
print("Read without chunks: ", (e_time-s_time), "seconds")
# data
df.sample(10)
Producción:
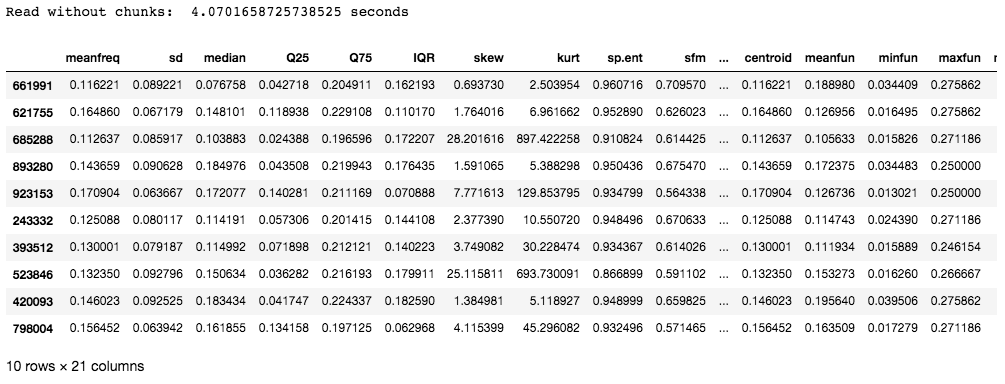
El conjunto de datos utilizado en este ejemplo contiene 986894 filas con 21 columnas. El tiempo necesario es de unos 4 segundos, que puede no ser tan largo, pero para las entradas que tienen millones de filas, el tiempo necesario para leer las entradas tiene un efecto directo en la eficiencia del modelo.
Ahora, usemos fragmentos para leer el archivo CSV:
Python3
# import required modules
import pandas as pd
import numpy as np
import time
# time taken to read data
s_time_chunk = time.time()
chunk = pd.read_csv('gender_voice_dataset.csv', chunksize=1000)
e_time_chunk = time.time()
print("With chunks: ", (e_time_chunk-s_time_chunk), "sec")
df = pd.concat(chunk)
# data
df.sample(10)
Producción:
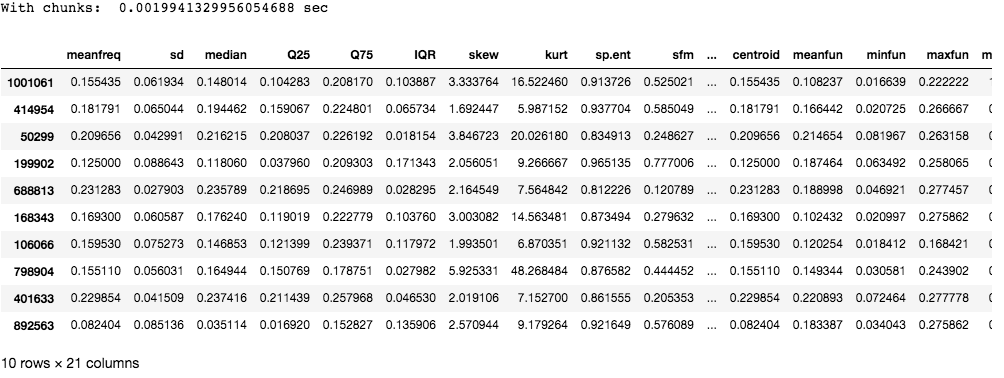
Como puede ver, fragmentar toma mucho menos tiempo en comparación con leer todo el archivo de una sola vez.
Usando Dask
Dask es una biblioteca de Python de código abierto que incluye características de paralelismo y escalabilidad en Python mediante el uso de bibliotecas existentes como pandas, NumPy o sklearn.
Instalar:
pip install dask
El siguiente es el código para leer archivos usando dask:
Python3
# import required modules
import pandas as pd
import numpy as np
import time
from dask import dataframe as df1
# time taken to read data
s_time_dask = time.time()
dask_df = df1.read_csv('gender_voice_dataset.csv')
e_time_dask = time.time()
print("Read with dask: ", (e_time_dask-s_time_dask), "seconds")
# data
dask_df.head(10)
Producción:
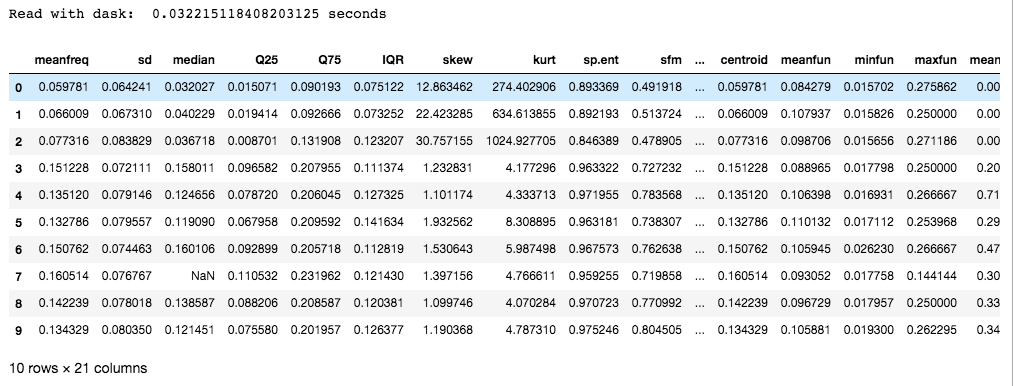
Dask es preferible a la fragmentación, ya que utiliza múltiples núcleos de CPU o grupos de máquinas (conocido como computación distribuida). Además de esto, también proporciona bibliotecas escaladas de NumPy, pandas y sci-kit para explotar el paralelismo.
Nota: El conjunto de datos en el enlace tiene alrededor de 3000 filas. Se agregaron datos adicionales por separado a los fines de este artículo, para aumentar el tamaño del archivo. No existe en el conjunto de datos original.
Publicación traducida automáticamente
Artículo escrito por shreyaraj1234 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA