En este artículo, vamos a raspar Linkedln usando las bibliotecas Selenium y Beautiful Soup en Python.
En primer lugar, necesitamos instalar algunas bibliotecas. Ejecute los siguientes comandos en la terminal.
pip install selenium pip install beautifulsoup4
Para usar Selenium, también necesitamos un controlador web. Puede descargar el controlador web de Internet Explorer, Firefox o Chrome. En este artículo, utilizaremos el controlador web de Chrome.
Nota: Mientras sigue este artículo, si recibe un error, lo más probable es que haya 2 razones posibles para ello.
- La página web tardó demasiado en cargarse (probablemente debido a una conexión a Internet lenta). En este caso, use la función time.sleep()para proporcionar tiempo adicional para que se cargue la página web. Especifique el número de segundos para dormir según su necesidad.
- El HTML de la página web ha cambiado con respecto al que tenía cuando se escribió este artículo. Si es así, deberá seleccionar manualmente los elementos de la página web requeridos, en lugar de copiar los nombres de los elementos escritos a continuación. A continuación se explica cómo encontrar los nombres de los elementos. Además, no disminuya el alto y el ancho de la ventana desde el alto y el ancho predeterminados. También cambia el HTML de la página web.
Iniciar sesión en LinkedIn
Aquí escribiremos el código para iniciar sesión en Linkedin. Primero, debemos iniciar el controlador web usando selenium y enviar una solicitud de obtención a la URL e identificar el documento HTML y encontrar las etiquetas de entrada y las etiquetas de botón que aceptan nombre de usuario/correo electrónico, contraseña, y el botón de inicio de sesión.
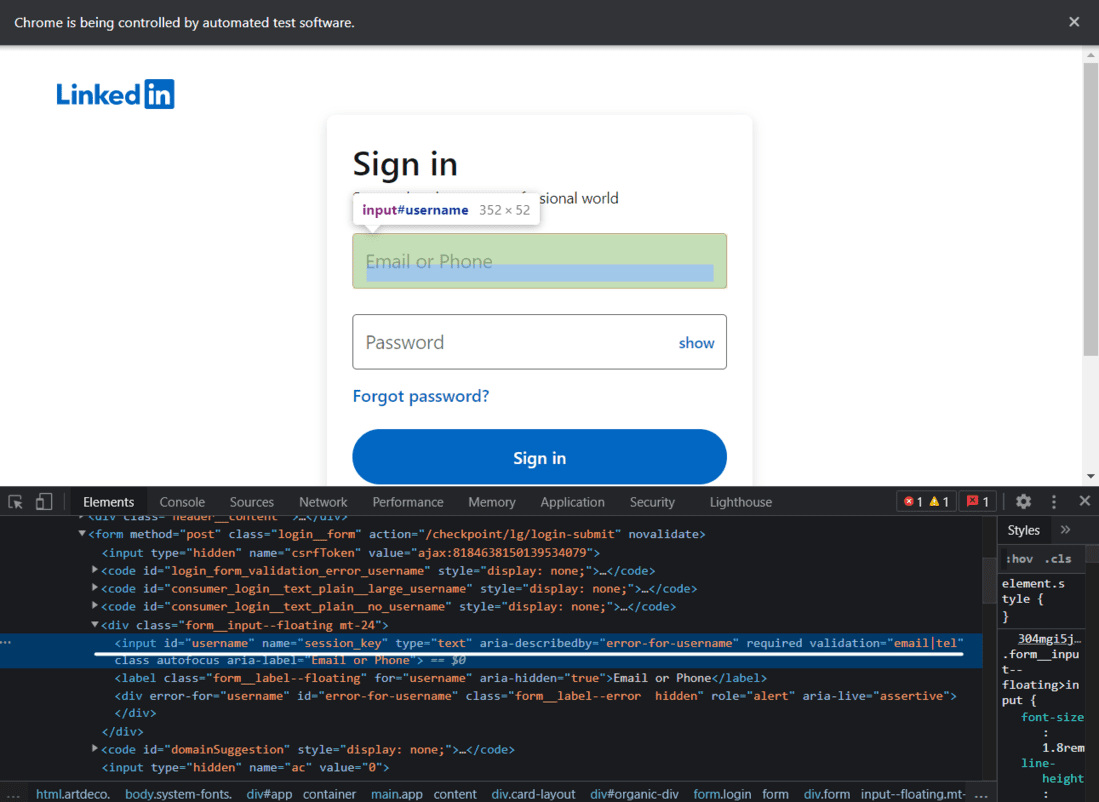
Página de inicio de sesión de LinkedIn
Código:
Python3
from selenium import webdriver
from bs4 import BeautifulSoup
import time
# Creating a webdriver instance
driver = webdriver.Chrome("Enter-Location-Of-Your-Web-Driver")
# This instance will be used to log into LinkedIn
# Opening linkedIn's login page
driver.get("https://linkedin.com/uas/login")
# waiting for the page to load
time.sleep(5)
# entering username
username = driver.find_element_by_id("username")
# In case of an error, try changing the element
# tag used here.
# Enter Your Email Address
username.send_keys("User_email")
# entering password
pword = driver.find_element_by_id("password")
# In case of an error, try changing the element
# tag used here.
# Enter Your Password
pword.send_keys("User_pass")
# Clicking on the log in button
# Format (syntax) of writing XPath -->
# //tagname[@attribute='value']
driver.find_element_by_xpath("//button[@type='submit']").click()
# In case of an error, try changing the
# XPath used here.
Después de ejecutar el comando anterior, iniciará sesión en su perfil de LinkedIn. Así es como se vería.
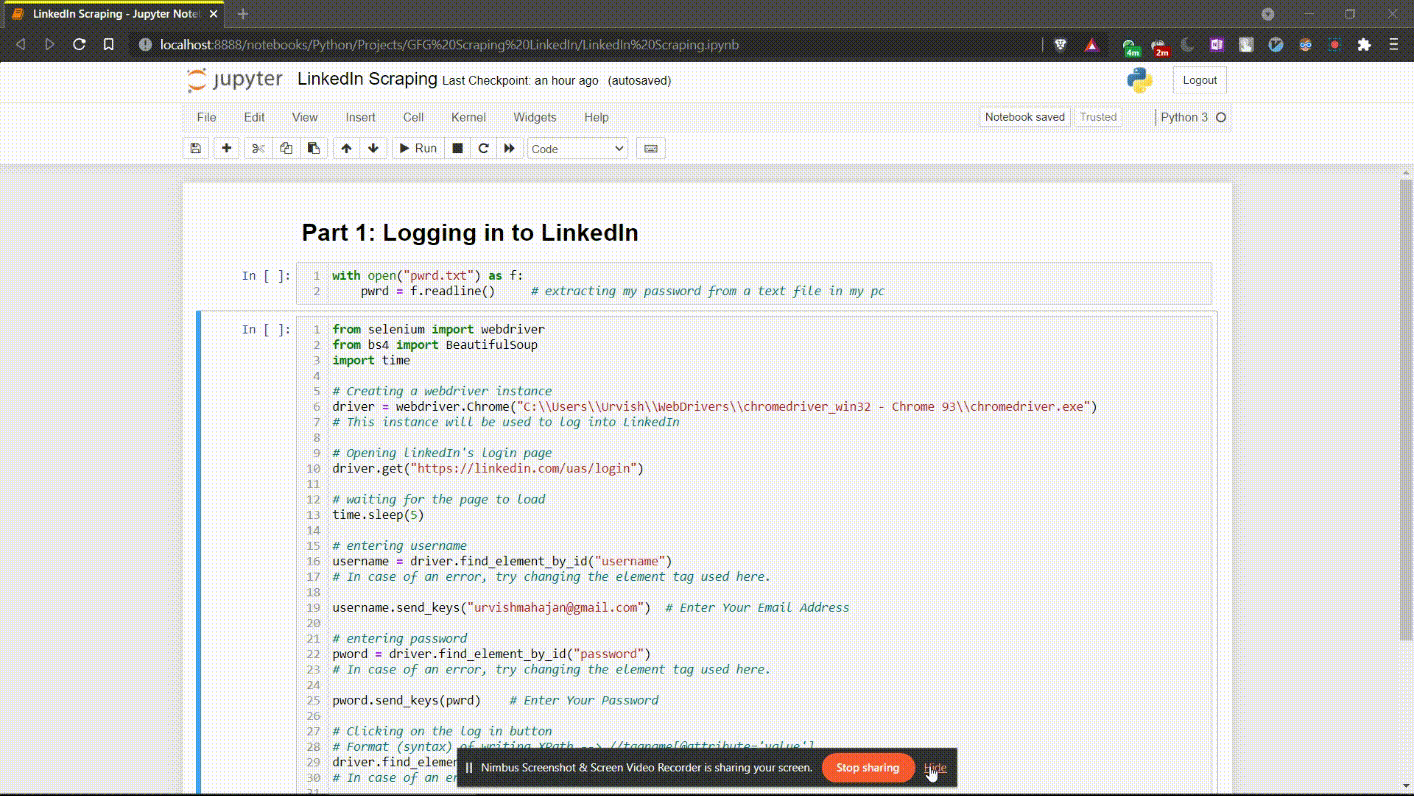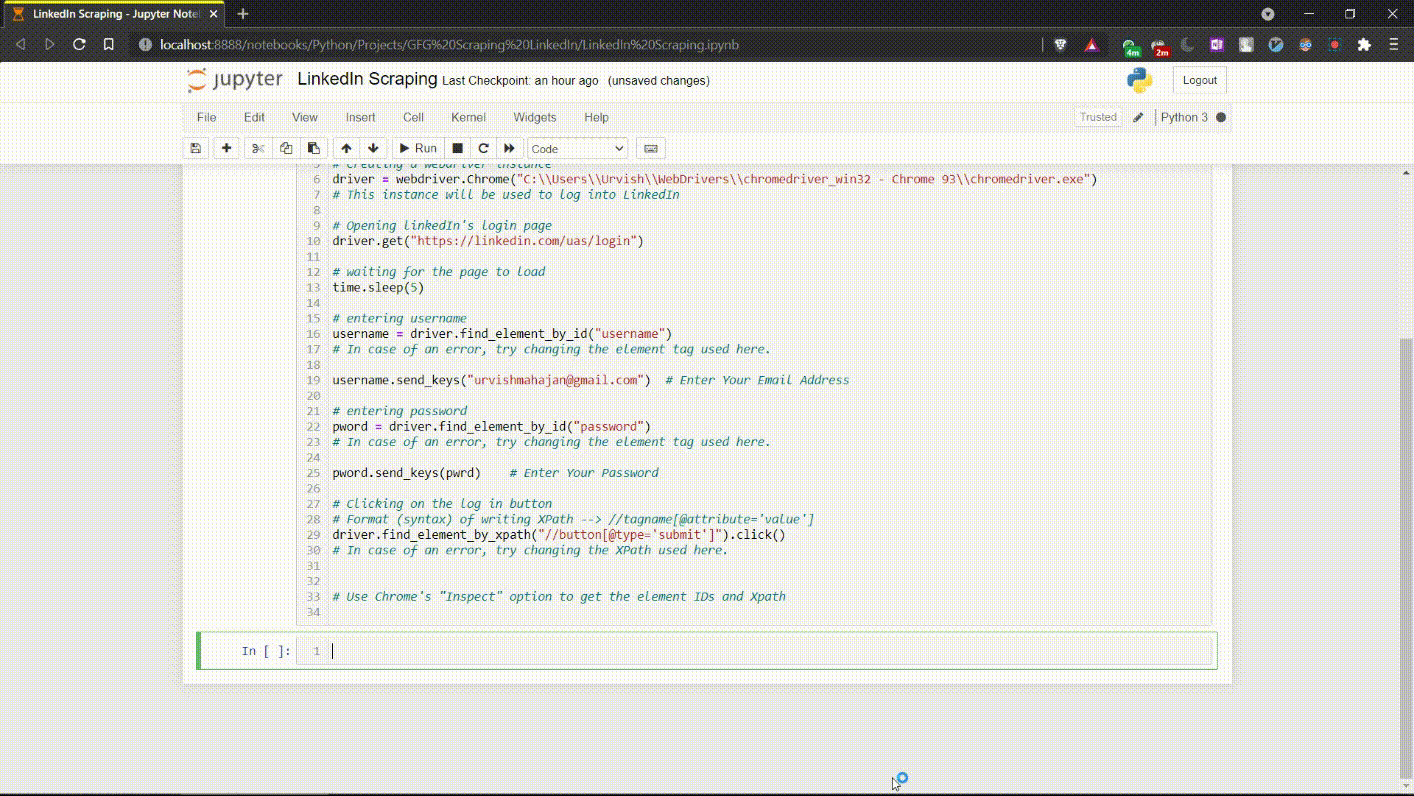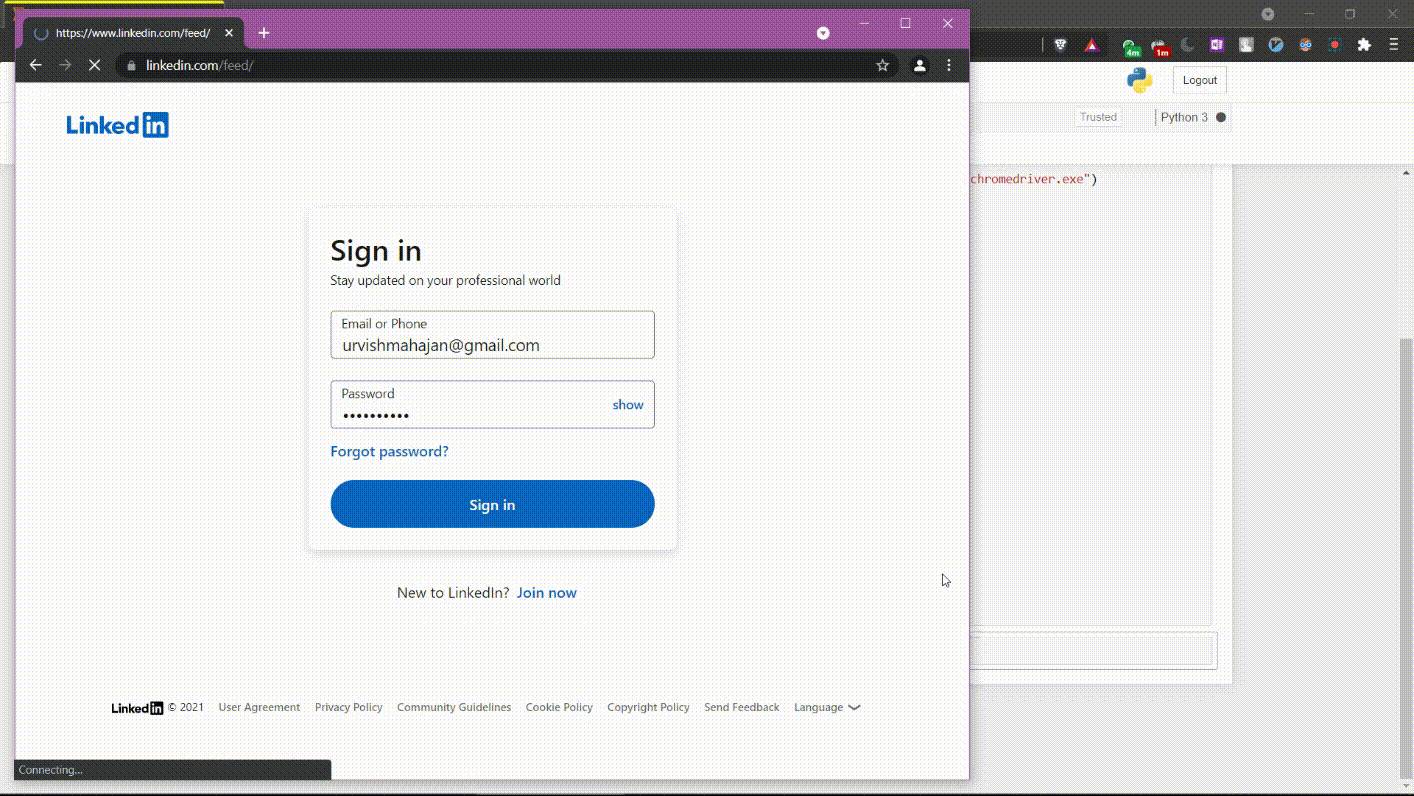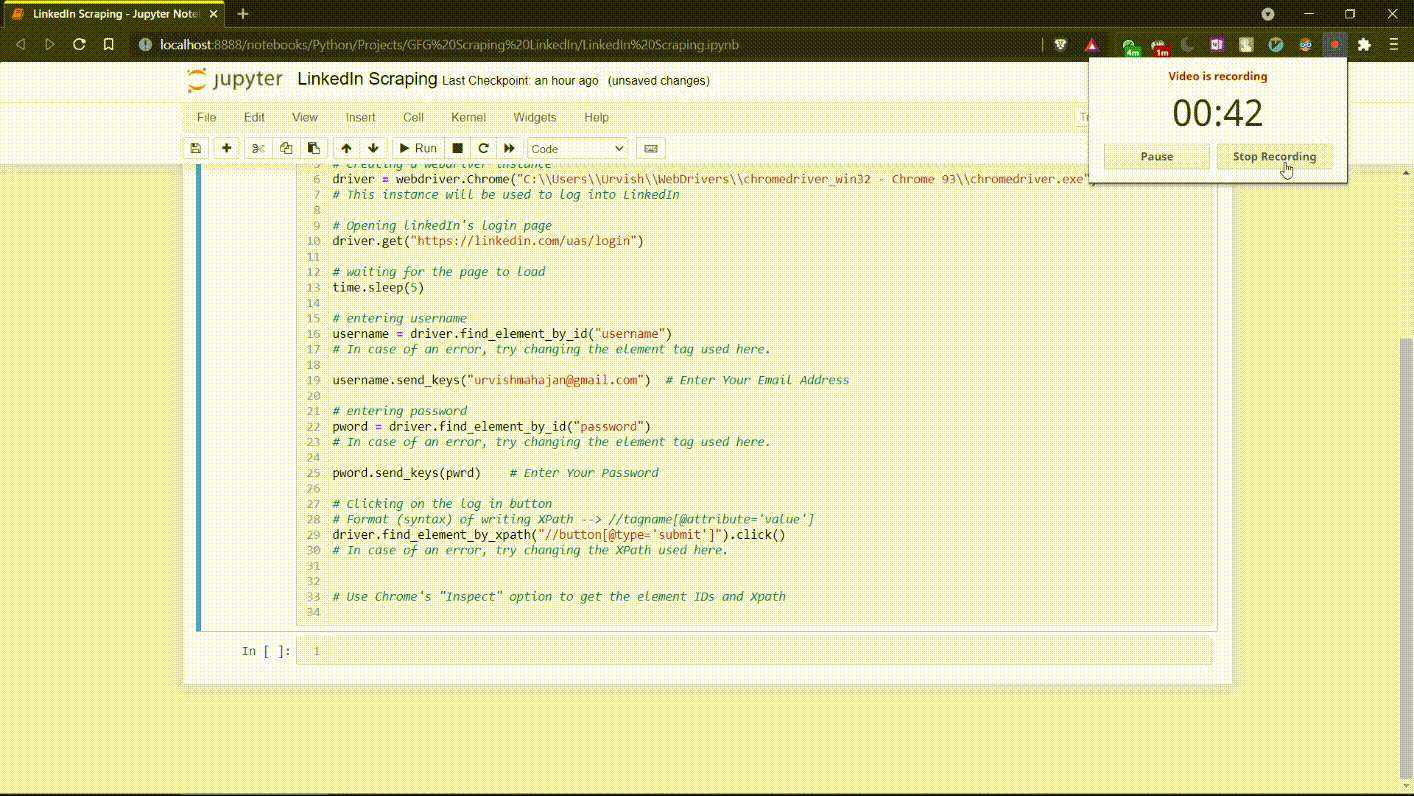
Ejecución de código de la parte 1
Extracción de datos de un perfil de LinkedIn
Aquí está el video de la ejecución del código completo.
Ejecución de código de la parte 2
2.A) Abrir un perfil y desplazarse hasta la parte inferior
Digamos que desea extraer datos del perfil de LinkedIn de Kunal Shah. En primer lugar, debemos abrir su perfil usando la URL de su perfil. Luego tenemos que desplazarnos hasta la parte inferior de la página web para que se carguen los datos completos.
Python3
from selenium import webdriver
from bs4 import BeautifulSoup
import time
# Creating an instance
driver = webdriver.Chrome("Enter-Location-Of-Your-Web-Driver")
# Logging into LinkedIn
driver.get("https://linkedin.com/uas/login")
time.sleep(5)
username = driver.find_element_by_id("username")
username.send_keys("") # Enter Your Email Address
pword = driver.find_element_by_id("password")
pword.send_keys("") # Enter Your Password
driver.find_element_by_xpath("//button[@type='submit']").click()
# Opening Kunal's Profile
# paste the URL of Kunal's profile here
profile_url = "https://www.linkedin.com/in/kunalshah1/"
driver.get(profile_url) # this will open the link
Producción:
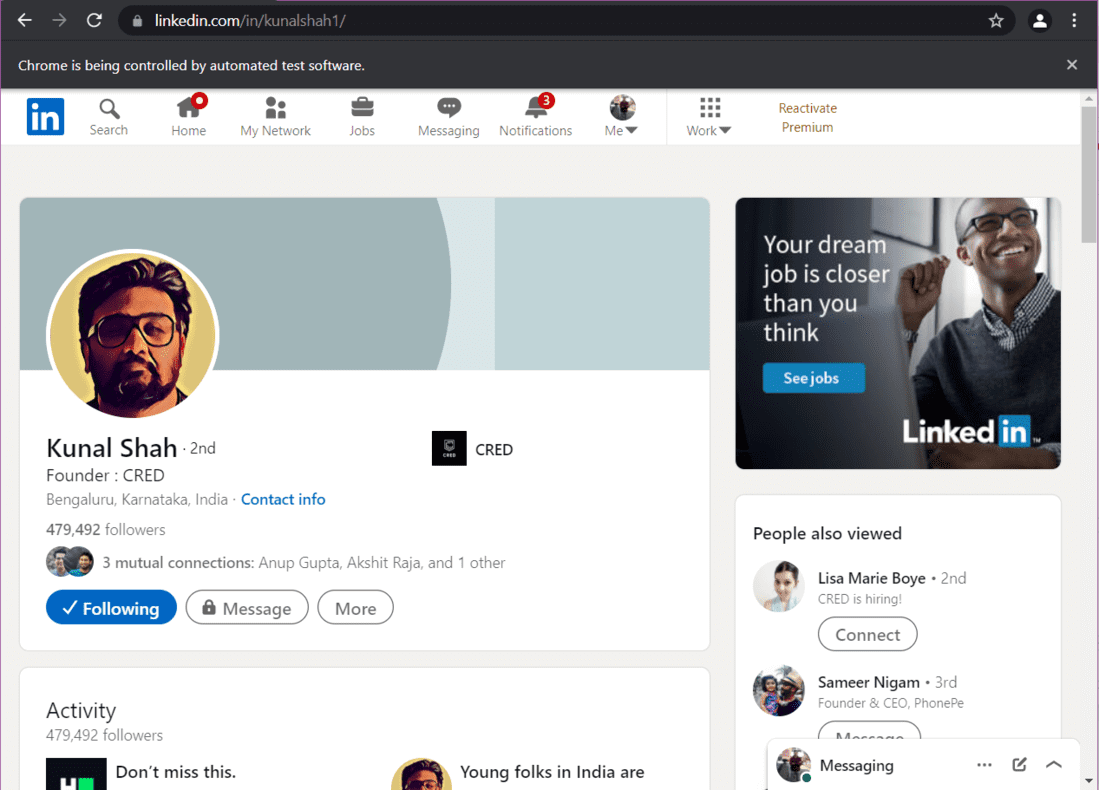
Kunal Shah – Perfil de LinkedIn
Ahora, tenemos que desplazarnos hasta la parte inferior. Aquí está el código para hacer eso:
Python3
start = time.time()
# will be used in the while loop
initialScroll = 0
finalScroll = 1000
while True:
driver.execute_script(f"window.scrollTo({initialScroll},
{finalScroll})
")
# this command scrolls the window starting from
# the pixel value stored in the initialScroll
# variable to the pixel value stored at the
# finalScroll variable
initialScroll = finalScroll
finalScroll += 1000
# we will stop the script for 3 seconds so that
# the data can load
time.sleep(3)
# You can change it as per your needs and internet speed
end = time.time()
# We will scroll for 20 seconds.
# You can change it as per your needs and internet speed
if round(end - start) > 20:
break
La página ahora se desplaza hacia abajo. Como la página está completamente cargada, rasparemos los datos que queremos.
Extracción de datos del perfil
Para extraer datos, en primer lugar, almacena el código fuente de la página web en una variable. Luego, use este código fuente para crear un objeto Beautiful Soup.
Python3
src = driver.page_source # Now using beautiful soup soup = BeautifulSoup(src, 'lxml')
Introducción al perfil de extracción:
Para extraer la introducción del perfil, es decir, el nombre, el nombre de la empresa y la ubicación, necesitamos encontrar el código fuente de cada elemento. Primero, encontraremos el código fuente de la etiqueta div que contiene la introducción del perfil.
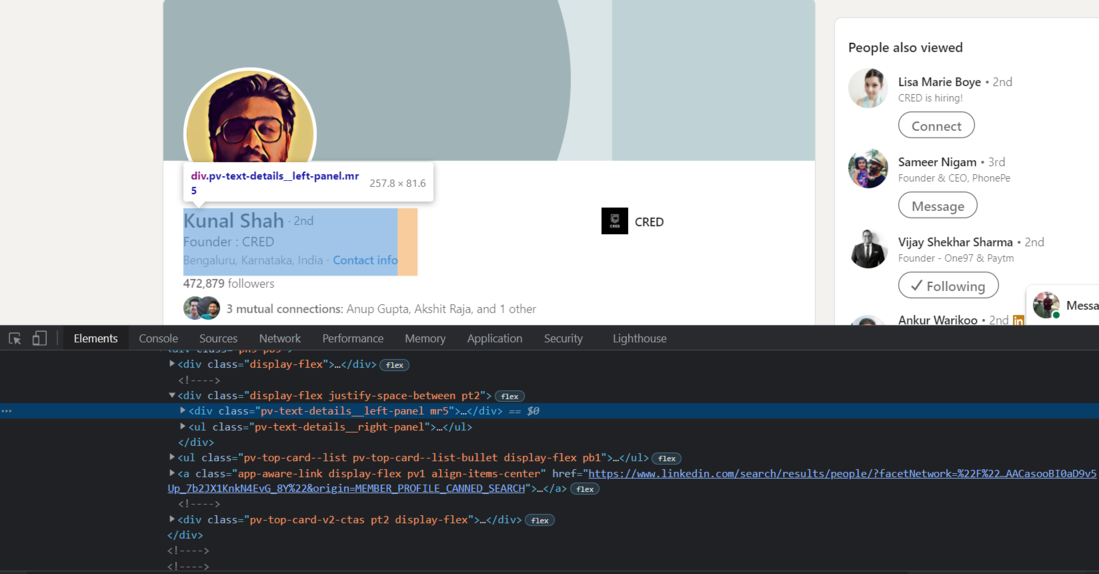
Chrome – Inspeccionar elementos
Ahora, usaremos Beautiful Soup para importar esta etiqueta div a python.
Python3
# Extracting the HTML of the complete introduction box
# that contains the name, company name, and the location
intro = soup.find('div', {'class': 'pv-text-details__left-panel'})
print(intro)
Producción:
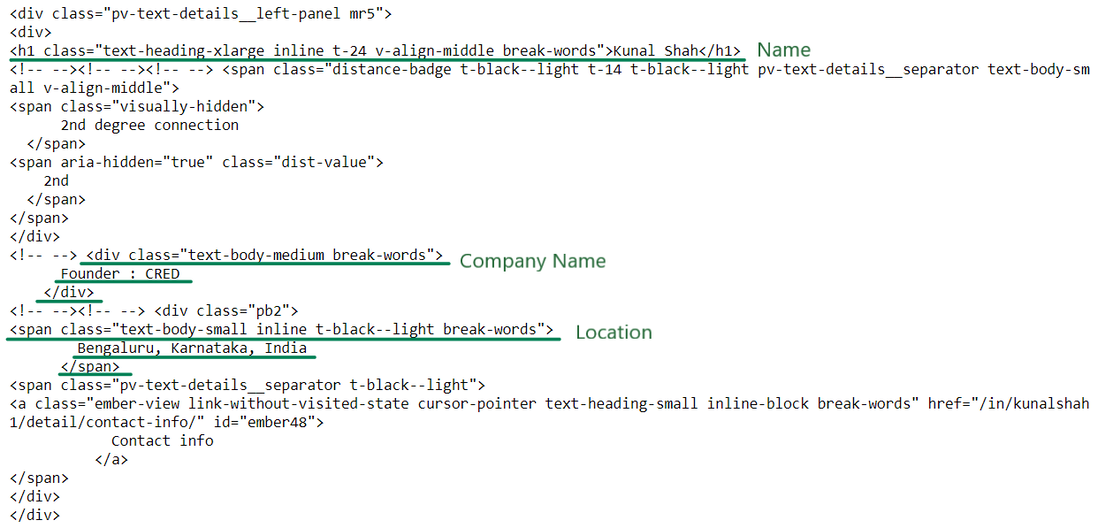
(Garabato) Introducción HTML
Ahora tenemos el código HTML necesario para extraer el nombre, el nombre de la empresa y la ubicación. Extraigamos ahora la información:
Python3
# In case of an error, try changing the tags used here.
name_loc = intro.find("h1")
# Extracting the Name
name = name_loc.get_text().strip()
# strip() is used to remove any extra blank spaces
works_at_loc = intro.find("div", {'class': 'text-body-medium'})
# this gives us the HTML of the tag in which the Company Name is present
# Extracting the Company Name
works_at = works_at_loc.get_text().strip()
location_loc = intro.find_all("span", {'class': 'text-body-small'})
# Ectracting the Location
# The 2nd element in the location_loc variable has the location
location = location_loc[1].get_text().strip()
print("Name -->", name,
"\nWorks At -->", works_at,
"\nLocation -->", location)
Producción:
Name --> Kunal Shah Works At --> Founder : CRED Location --> Bengaluru, Karnataka, India
Extracción de datos de la sección de experiencia
A continuación, extraeremos la Experiencia del perfil.
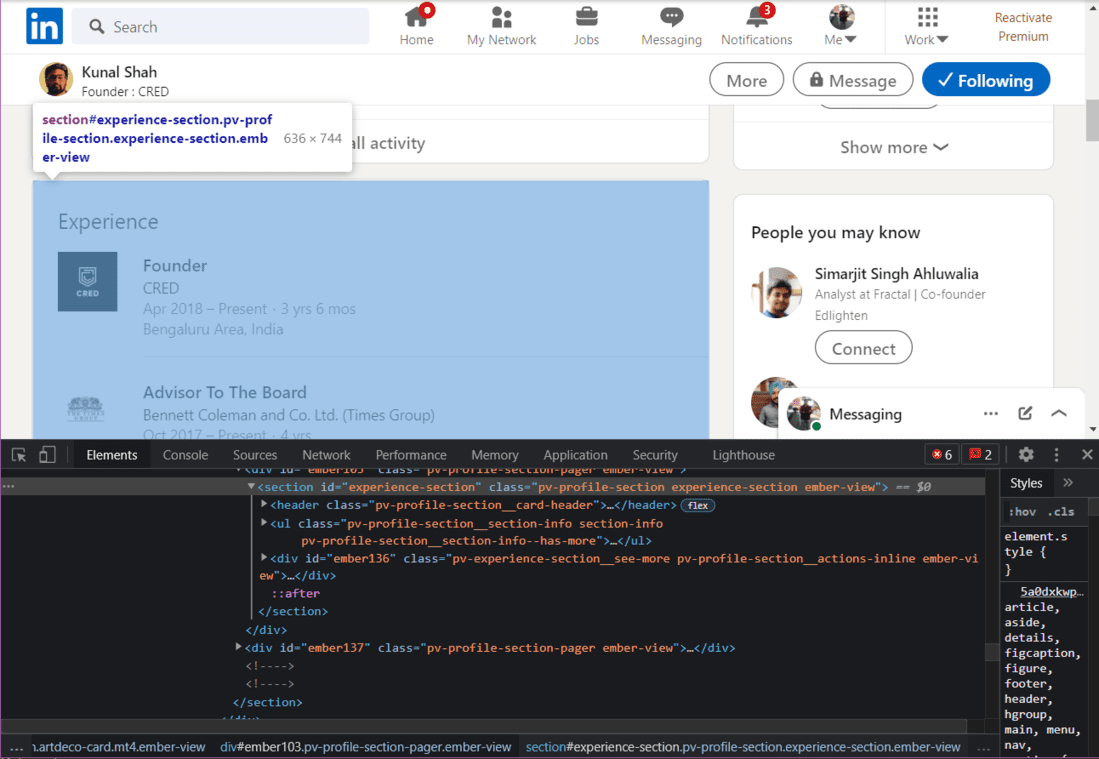
HTML de la sección Experiencia
Python3
# Getting the HTML of the Experience section in the profile
experience = soup.find("section", {"id": "experience-section"}).find('ul')
print(experience)
Producción:
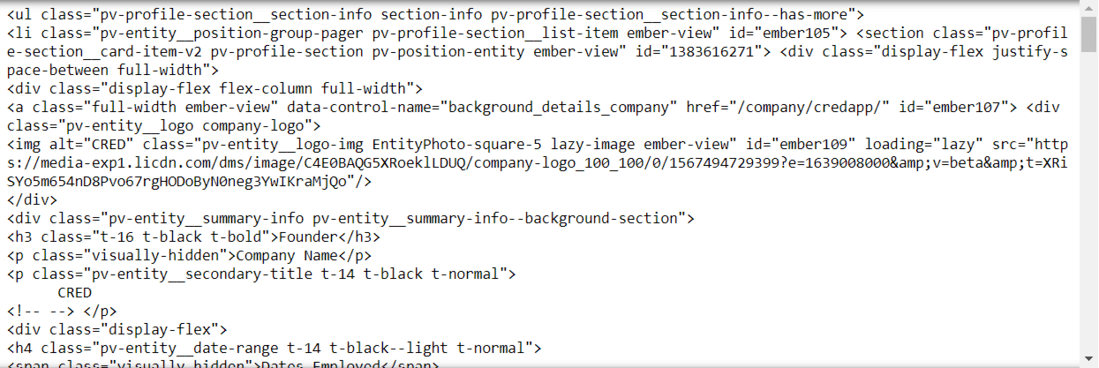
Experimente la salida HTML
Tenemos que ir dentro de las etiquetas HTML hasta que encontremos la información deseada. En la imagen de arriba, podemos ver el HTML para extraer el título del trabajo actual y el nombre de la empresa. Ahora necesitamos ir dentro de cada etiqueta para extraer los datos.
Raspe el título del trabajo, el nombre de la empresa y la experiencia :
Python3
# In case of an error, try changing the tags used here.
li_tags = experience.find('div')
a_tags = li_tags.find("a")
job_title = a_tags.find("h3").get_text().strip()
print(job_title)
company_name = a_tags.find_all("p")[1].get_text().strip()
print(company_name)
joining_date = a_tags.find_all("h4")[0].find_all("span")[1].get_text().strip()
employment_duration = a_tags.find_all("h4")[1].find_all(
"span")[1].get_text().strip()
print(joining_date + ", " + employment_duration)
Producción:
'Founder' 'CRED' Apr 2018 – Present, 3 yrs 6 mos
Extracción de datos de búsqueda de empleo
Usaremos selenium para abrir la página de trabajos.
Python3
jobs = driver.find_element_by_xpath("//a[@data-link-to='jobs']/span")
# In case of an error, try changing the XPath.
jobs.click()
Ahora que la página de trabajos está abierta, crearemos un objeto BeautifulSoup para raspar los datos.
Python3
job_src = driver.page_source soup = BeautifulSoup(job_src, 'lxml')
Raspe el título del trabajo:
En primer lugar, rasparemos los títulos de trabajo.
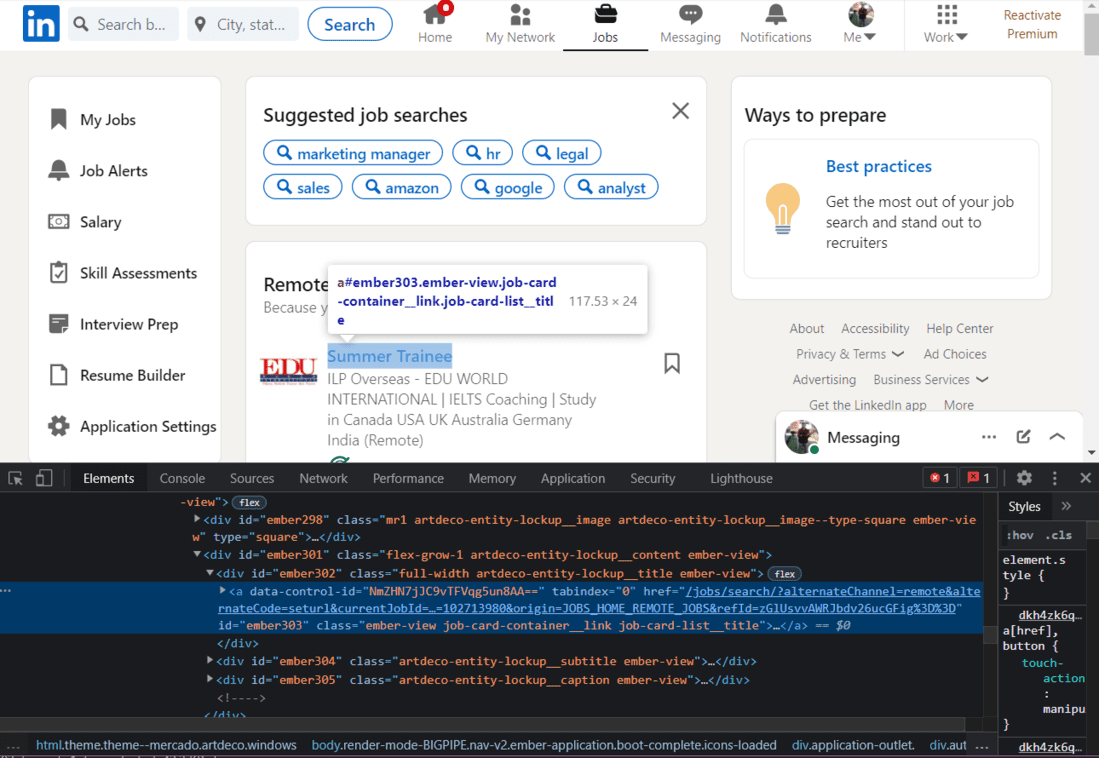
HTML del título del trabajo
Al hojear el HTML de esta página, encontraremos que cada Título de trabajo tiene el nombre de clase «job-card-list__title». Usaremos este nombre de clase para extraer los títulos de trabajo.
Python3
jobs_html = soup.find_all('a', {'class': 'job-card-list__title'})
# In case of an error, try changing the XPath.
job_titles = []
for title in jobs_html:
job_titles.append(title.text.strip())
print(job_titles)
Producción:

Lista de títulos de trabajo
Raspe el nombre de la empresa:
A continuación, extraeremos el Nombre de la empresa.
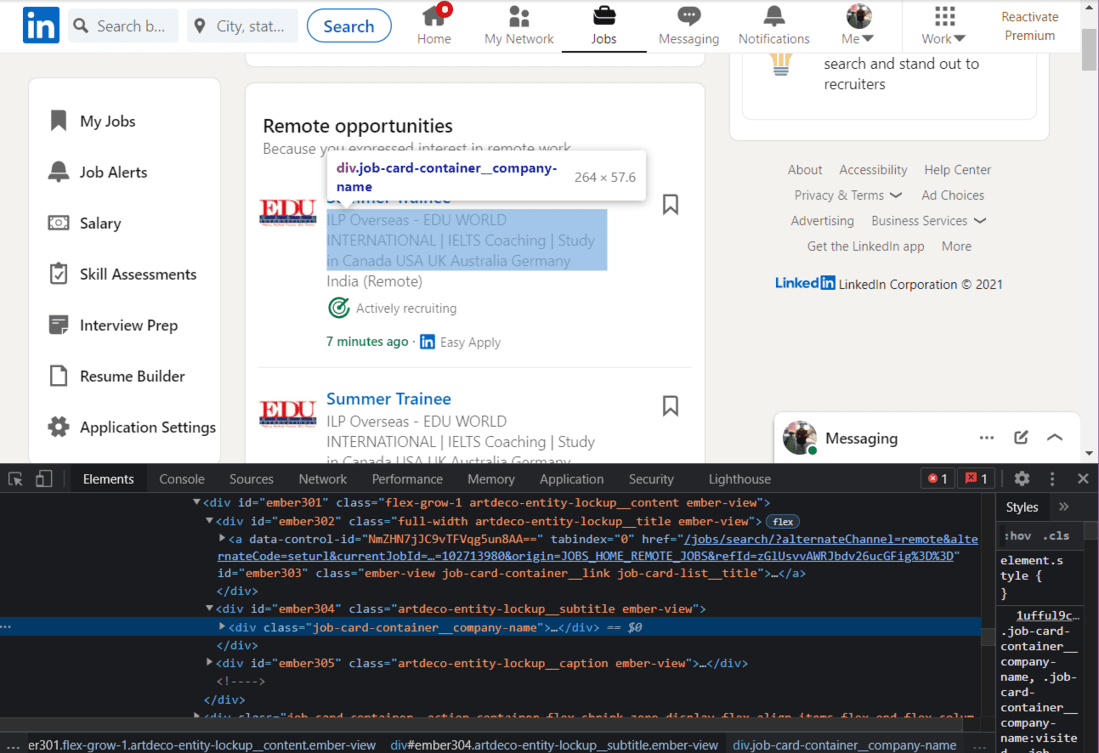
HTML del nombre de la empresa
Usaremos el nombre de la clase para extraer los nombres de las empresas:
Python3
company_name_html = soup.find_all(
'div', {'class': 'job-card-container__company-name'})
company_names = []
for name in company_name_html:
company_names.append(name.text.strip())
print(company_names)
Producción:

Lista de nombres de empresas
Raspe la ubicación del trabajo:
Finalmente, extraeremos la ubicación del trabajo.
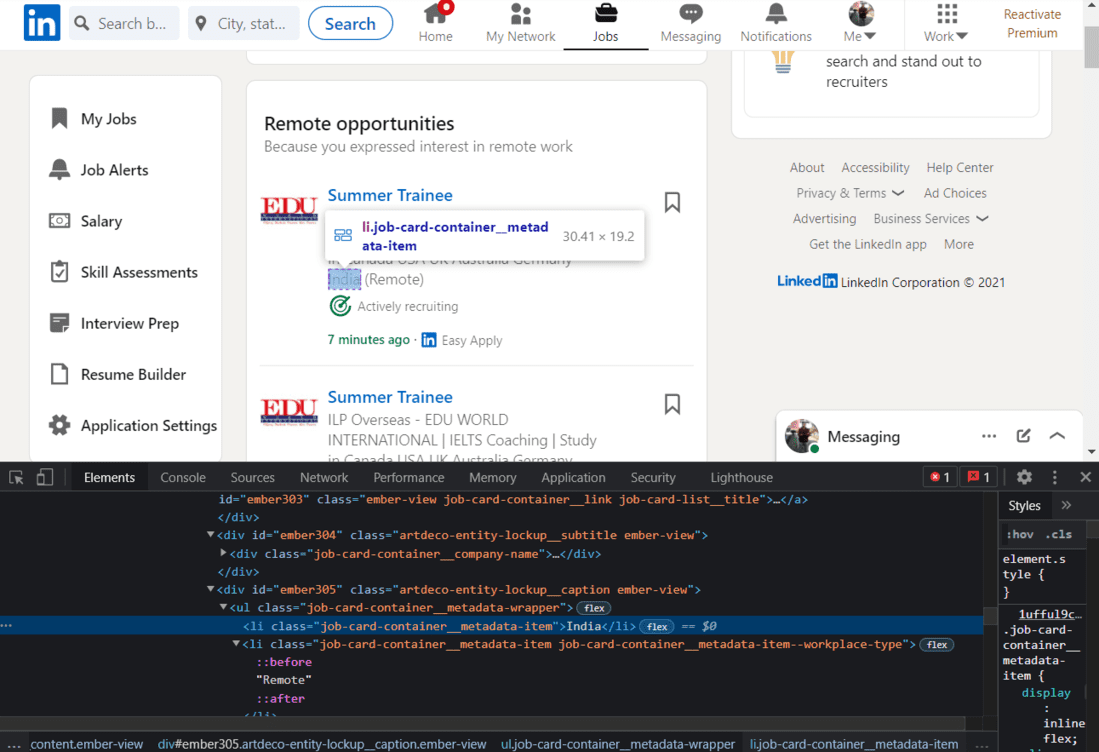
HTML de la ubicación del trabajo
Una vez más, usaremos el nombre de la clase para extraer la ubicación.
Python3
import re # for removing the extra blank spaces
location_html = soup.find_all(
'ul', {'class': 'job-card-container__metadata-wrapper'})
location_list = []
for loc in location_html:
res = re.sub('\n\n +', ' ', loc.text.strip())
location_list.append(res)
print(location_list)
Producción:

Lista de ubicaciones de trabajo
Publicación traducida automáticamente
Artículo escrito por urvishmahajan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA