Para eliminar los registros duplicados, primero debemos encontrar todos los registros distintos. En los registros duplicados, todos los datos son iguales excepto id_fila porque id_fila es la dirección física que ocupa el registro. Entonces, encontramos la identificación de fila distinta donde los datos son distintos en cada columna y luego eliminamos todas las filas con row_id que no están en la consulta anterior.
Aquí veremos cómo eliminar registros duplicados en Oracle. Para este propósito de demostración, crearemos una demostración de tabla.
Crear base de datos:
En primer lugar, creamos una tabla y completamos los datos en ella, con algunos registros duplicados usando:
Consulta:
CREATE TABLE Demo( PersonID int, LastName varchar(255), FirstName varchar(255)); INSERT INTO Demo VALUES (1, 'Geek1', 'Geeksforgeeks'); INSERT INTO Demo VALUES (2, 'Geek2', 'Geeksforgeeks'); INSERT INTO Demo VALUES (3, 'Geek3', 'Geeksforgeeks'); INSERT INTO Demo VALUES (1, 'Geek1', 'Geeksforgeeks'); INSERT INTO Demo VALUES (2, 'Geek2', 'Geeksforgeeks'); INSERT INTO Demo VALUES (2, 'Geek2', 'Geeksforgeeks');
Producción:
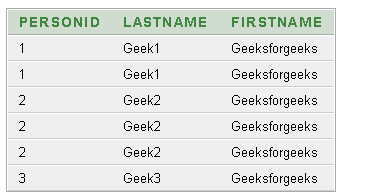
Ahora, encontraremos todos los registros distintos que no tengan una fila duplicada usando:
Consulta:
SELECT * FROM Demo WHERE rowid IN ( SELECT MAX(rowid) FROM Demo GROUP BY PersonID, LastName, FirstName);
Producción:
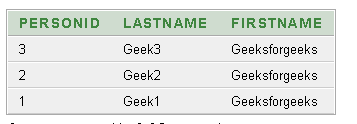
Ahora. elimine todas las filas con ID de fila que no están en la consulta anterior usando:
Consulta:
DELETE Demo WHERE rowid NOT IN (SELECT MAX(rowid) FROM Demo GROUP BY PersonID, LastName, FirstName);
Producción:
La tabla final con los duplicados eliminados es la siguiente:
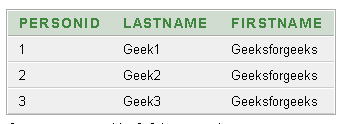
Publicación traducida automáticamente
Artículo escrito por mishrapriyank17 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA