Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
La función Pandas dataframe.std()devuelve la desviación estándar de la muestra sobre el eje solicitado. Por defecto, las desviaciones estándar están normalizadas por N-1. Es una medida que se utiliza para cuantificar la cantidad de variación o dispersión de un conjunto de valores de datos. Para más información haga clic aquí
Sintaxis: DataFrame.std(axis=Ninguno, skipna=Ninguno, level=Ninguno, ddof=1, numeric_only=Ninguno, **kwargs)
Parámetros:
eje: {índice (0), columnas (1)}
skipna: Excluir NA/valores nulos. Si toda una fila/columna es NA, el resultado será un
nivel NA: Si el eje es un Multiíndice (jerárquico), cuente a lo largo de un nivel particular, colapsando en una Serie
ddof: Delta Grados de libertad. El divisor utilizado en los cálculos es N – ddof, donde N representa el número de elementos.
numeric_only : incluye solo columnas flotantes, int y booleanas. Si es Ninguno, intentará usar todo, luego use solo datos numéricos. No implementado para Serie.Retorno: std: Serie o DataFrame (si se especifica el nivel)
Para obtener un enlace al archivo CSV utilizado en el código, haga clic aquí
Ejemplo #1: Use std()la función para encontrar la desviación estándar de los datos a lo largo del eje del índice.
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.read_csv("nba.csv")
# Print the dataframe
df
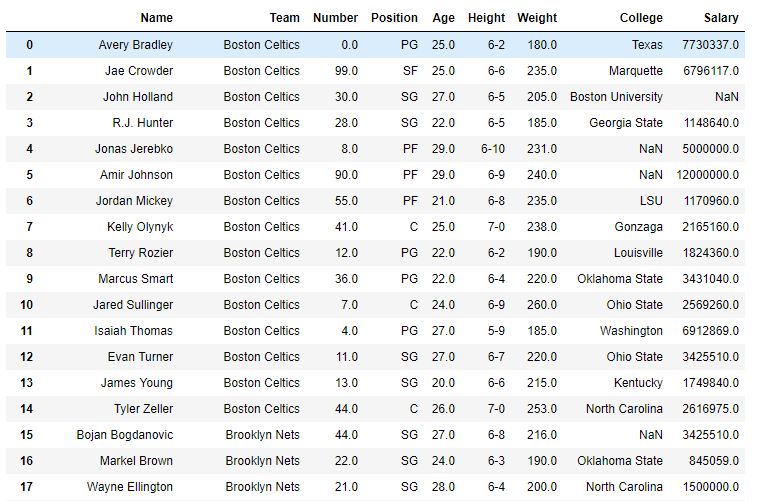
Ahora encuentre la desviación estándar de todas las columnas numéricas en el marco de datos. Vamos a omitir los NaNvalores en el cálculo de la desviación estándar.
# finding STD df.std(axis = 0, skipna = True)
Producción :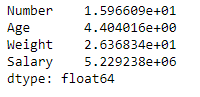
Ejemplo #2: Use std()la función para encontrar la desviación estándar sobre el eje de la columna.
Encuentre la desviación estándar a lo largo del eje de la columna. Vamos a hacer que skipna sea verdadero. Si no omitimos los NaNvalores, dará como resultado NaNvalores.
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.read_csv("nba.csv")
# STD over the column axis.
df.std(axis = 1, skipna = True)
Producción :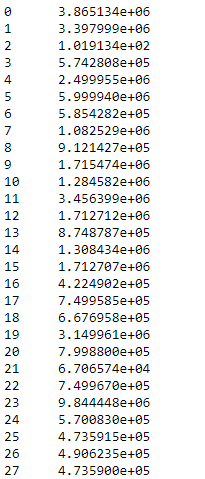
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA