Los demonios significan Proceso . Hadoop Daemons son un conjunto de procesos que se ejecutan en Hadoop. Hadoop es un marco escrito en Java , por lo que todos estos procesos son procesos Java.
Apache Hadoop 2 consta de los siguientes demonios:
- NodeNombre
- Node de datos
- Node de nombre secundario
- Administrador de recursos
- Administrador de Nodes
Namenode, NameNode secundario y Resource Manager funcionan en un sistema maestro, mientras que Node Manager y DataNode funcionan en la máquina esclava.
1. NodeNombre
NameNode funciona en el sistema maestro. El propósito principal de Namenode es administrar todos los metadatos. Los metadatos son la lista de archivos almacenados en HDFS (Sistema de archivos distribuidos de Hadoop). Como sabemos, los datos se almacenan en forma de bloques en un clúster de Hadoop. Entonces, el DataNode en el que o la ubicación en la que se almacena ese bloque del archivo se menciona en MetaData. Toda la información relacionada con los registros de las transacciones que ocurren en un clúster de Hadoop (cuándo o quién leyó/escribió los datos) se almacenará en MetaData. Los metadatos se almacenan en la memoria.
Características:
- Nunca almacena los datos que están presentes en el archivo.
- Como Namenode funciona en el sistema maestro, el sistema maestro debe tener una buena potencia de procesamiento y más RAM que los esclavos.
- Almacena la información de DataNode, como su ID de bloque y la cantidad de bloques.
¿Cómo iniciar el Node de nombre?
hadoop-daemon.sh start namenode
¿Cómo detener el Node de nombre?
hadoop-daemon.sh stop namenode

2. Node de datos
DataNode funciona en el sistema Slave. NameNode siempre instruye a DataNode para almacenar los datos. DataNode es un programa que se ejecuta en el sistema esclavo que atiende la solicitud de lectura/escritura del cliente. Como los datos se almacenan en este DataNode, deben poseer mucha memoria para almacenar más datos.
¿Cómo iniciar Node de datos?
hadoop-daemon.sh start datanode
¿Cómo detener el Node de datos?
hadoop-daemon.sh stop datanode

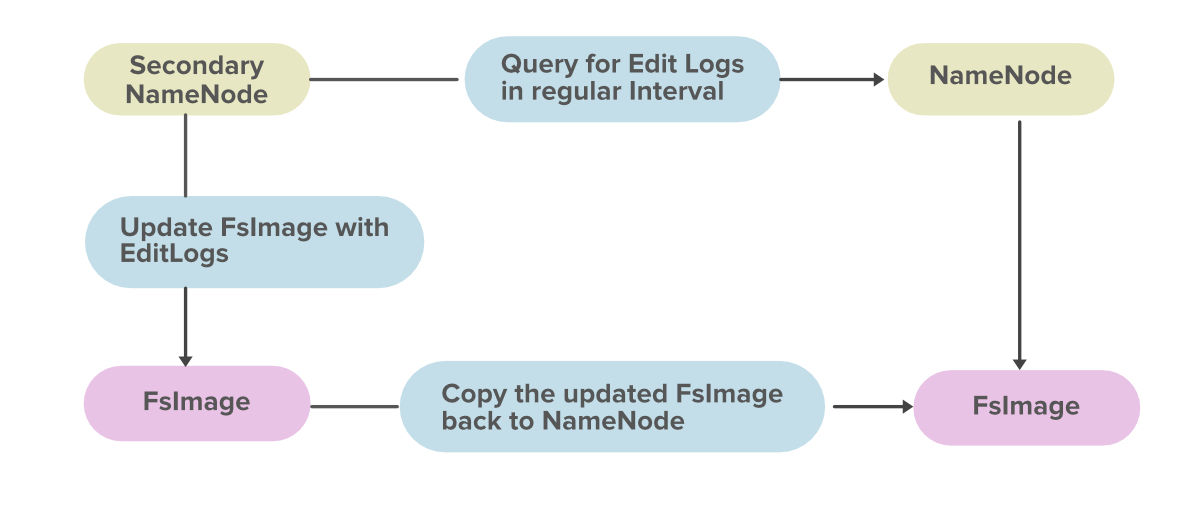
3. Node de nombre secundario
El NameNode secundario se utiliza para realizar copias de seguridad de los datos cada hora. En caso de que el clúster de Hadoop falle o se bloquee, el Namenode secundario tomará la copia de seguridad por hora o los puntos de control de esos datos y los almacenará en un archivo con el nombre fsimage . Este archivo luego se transfiere a un nuevo sistema. Se asigna un nuevo MetaData a ese nuevo sistema y se crea un nuevo Master con este MetaData, y el clúster se vuelve a ejecutar correctamente.
Este es el beneficio del Node de nombre secundario. Ahora en Hadoop2, tenemos funciones de alta disponibilidad y federación que minimizan la importancia de este Node de nombre secundario en Hadoop2.
Función principal del Node de nombre secundario:
- Agrupa los registros de edición y Fsimage de NameNode.
- Lee continuamente los metadatos de la RAM de NameNode y los escribe en el disco duro.
Como NameNode secundario realiza un seguimiento de los puntos de control en un sistema de archivos distribuido de Hadoop, también se conoce como el Node de punto de control.
| El demonio de Hadoop | Puerto |
|---|---|
| Node de nombre | 50070 |
| Node de datos | 50075 |
| Node de nombre secundario | 50090 |
Estos puertos se pueden configurar manualmente en los archivos hdfs-site.xml y mapred-site.xml .
4. Administrador de recursos
Resource Manager también se conoce como el demonio maestro global que funciona en el sistema maestro. El administrador de recursos administra los recursos para las aplicaciones que se ejecutan en un clúster de Hadoop. El Administrador de recursos consta principalmente de 2 cosas.
1. Administrador de aplicaciones
2. Programador
Un administrador de aplicaciones es responsable de aceptar la solicitud de un cliente y también crea un recurso de memoria en los esclavos en un clúster de Hadoop para alojar el maestro de aplicaciones . El programador se utiliza para proporcionar recursos para aplicaciones en un clúster de Hadoop y para monitorear esta aplicación.
¿Cómo iniciar ResourceManager?
yarn-daemon.sh start resourcemanager
¿Cómo detener ResourceManager?
stop:yarn-daemon.sh stop resoucemnager

5. Administrador de Nodes
El administrador de Nodes funciona en el sistema esclavo que administra el recurso de memoria dentro del Node y el disco de memoria. Cada Node esclavo en un clúster de Hadoop tiene un solo demonio NodeManager ejecutándose en él. También envía esta información de monitoreo al administrador de recursos.
¿Cómo iniciar el Administrador de Nodes?
yarn-daemon.sh start nodemanager
¿Cómo detener el Administrador de Nodes?
yarn-daemon.sh stop nodemanager

En un clúster de Hadoop, se puede realizar un seguimiento de Resource Manager y Node Manager con las URL específicas, del tipo http://:port_number
| El demonio de Hadoop | Puerto |
|---|---|
| Administrador de recursos | 8088 |
| Administrador de Nodes | 8042 |
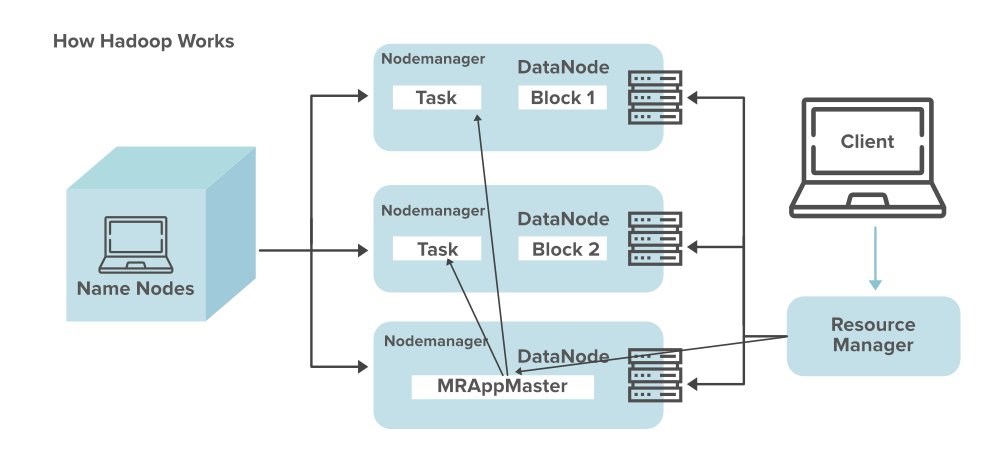
El siguiente diagrama muestra cómo funciona Hadoop.
Publicación traducida automáticamente
Artículo escrito por dikshantmalidev y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA