Con el aumento de la velocidad de los datos, el tamaño de los datos supera fácilmente el límite de almacenamiento de una máquina. Una solución sería almacenar los datos en una red de máquinas. Estos sistemas de archivos se denominan sistemas de archivos distribuidos . Dado que los datos se almacenan en una red, entran todas las complicaciones de una red.
Aquí es donde entra Hadoop. Proporciona uno de los sistemas de archivos más confiables. HDFS (Sistema de archivos distribuidos de Hadoop) es un diseño único que proporciona almacenamiento para archivos extremadamente grandes con patrón de acceso a datos de transmisión y se ejecuta en hardware básico . Desarrollemos los términos:
- Archivos extremadamente grandes : aquí estamos hablando de datos en el rango de petabytes (1000 TB).
- Patrón de acceso a datos de transmisión : HDFS está diseñado según el principio de escribir una vez y leer varias veces . Una vez que se escriben los datos, se pueden procesar grandes porciones del conjunto de datos cualquier número de veces.
- Hardware básico: hardware económico y fácilmente disponible en el mercado. Esta es una de las características que distingue especialmente a HDFS de otros sistemas de archivos.
Nodes: los Nodes maestro-esclavo generalmente forman el clúster HDFS.
- NodeNombre(NodeMaestro):
- Administra todos los Nodes esclavos y les asigna trabajo.
- Ejecuta operaciones de espacio de nombres del sistema de archivos como abrir, cerrar, renombrar archivos y directorios.
- Debe implementarse en un hardware confiable que tenga una configuración alta. no en hardware básico.
- Node de datos (Node esclavo):
- Nodes de trabajadores reales, que realizan el trabajo real como leer, escribir, procesar, etc.
- También realizan la creación, la eliminación y la replicación siguiendo las instrucciones del maestro.
- Se pueden implementar en hardware básico.
Demonios HDFS: Los demonios son los procesos que se ejecutan en segundo plano.
- Nodes de nombre:
- Ejecutar en el Node maestro.
- Almacene metadatos (datos sobre datos) como la ruta del archivo, la cantidad de bloques, las identificaciones de los bloques. etc.
- Requiere una gran cantidad de RAM.
- Almacene metadatos en RAM para una recuperación rápida, es decir, para reducir el tiempo de búsqueda. Aunque se guarda una copia persistente en el disco.
- Nodes de datos:
- Ejecutar en Nodes esclavos.
- Requiere mucha memoria ya que los datos se almacenan aquí.
Almacenamiento de datos en HDFS: ahora veamos cómo se almacenan los datos de forma distribuida.
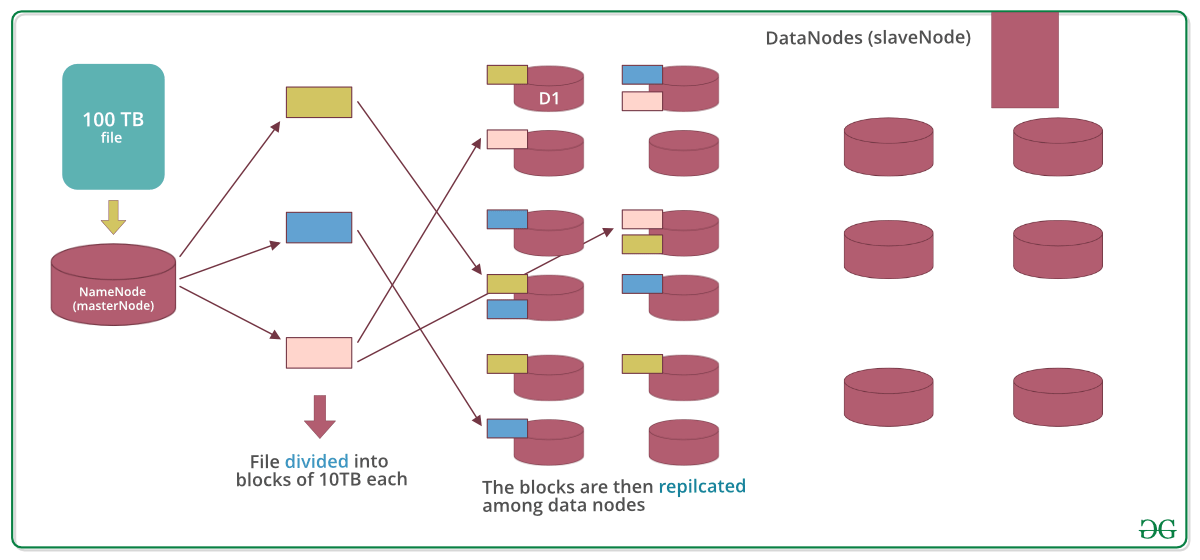
Supongamos que se inserta un archivo de 100 TB, luego masternode (namenode) primero dividirá el archivo en bloques de 10 TB (el tamaño predeterminado es 128 MB en Hadoop 2.x y superior). Luego, estos bloques se almacenan en diferentes Nodes de datos (Node esclavo). Los Nodes de datos (slavenode) replican los bloques entre ellos y la información de qué bloques contienen se envía al maestro. El factor de replicación predeterminado es 3 medios para que cada bloque se creen 3 réplicas (incluido él mismo). En hdfs.site.xml podemos aumentar o disminuir el factor de replicación, es decir, podemos editar su configuración aquí.
Nota: MasterNode tiene el registro de todo, conoce la ubicación y la información de todos y cada uno de los Nodes de datos y los bloques que contienen, es decir, no se hace nada sin el permiso de masternode.
¿Por qué dividir el archivo en bloques?
Respuesta: Supongamos que no dividimos, ahora es muy difícil almacenar un archivo de 100 TB en una sola máquina. Incluso si almacenamos, cada operación de lectura y escritura en todo el archivo requerirá un tiempo de búsqueda muy alto. Pero si tenemos varios bloques de un tamaño de 128 MB, es fácil realizar varias operaciones de lectura y escritura en él en comparación con hacerlo en un archivo completo a la vez. Entonces dividimos el archivo para tener un acceso más rápido a los datos, es decir, reducir el tiempo de búsqueda.
¿Por qué replicar los bloques en los Nodes de datos durante el almacenamiento?
Respuesta: supongamos que no replicamos y que solo hay un bloque amarillo en el Node de datos D1. Ahora, si el Node de datos D1 falla, perderemos el bloque y esto hará que los datos generales sean inconsistentes y defectuosos. Entonces replicamos los bloques para lograr tolerancia a fallas.
Términos relacionados con HDFS:
- HeartBeat : Es la señal que datanode envía continuamente a namenode. Si namenode no recibe el latido de un datanode, lo considerará muerto.
- Equilibrio : si un Node de datos se bloquea, los bloques presentes en él también desaparecerán y los bloques no se replicarán en comparación con los bloques restantes. Aquí el Node maestro (namenode) dará una señal a los Nodes de datos que contienen réplicas de esos bloques perdidos para que se repliquen, de modo que la distribución general de bloques esté equilibrada.
- Replicación: Se realiza mediante datanode.
Nota: No hay dos réplicas del mismo bloque presentes en el mismo Node de datos.
Características:
- Almacenamiento de datos distribuido.
- Los bloques reducen el tiempo de búsqueda.
- Los datos están altamente disponibles ya que el mismo bloque está presente en múltiples Nodes de datos.
- Incluso si varios Nodes de datos están inactivos, aún podemos hacer nuestro trabajo, lo que lo hace altamente confiable.
- Alta tolerancia a fallos.
Limitaciones: aunque HDFS proporciona muchas funciones, hay algunas áreas en las que no funciona bien.
- Acceso a datos de baja latencia : las aplicaciones que requieren acceso a datos de baja latencia, es decir, en el rango de milisegundos, no funcionarán bien con HDFS, porque HDFS está diseñado teniendo en cuenta que necesitamos un alto rendimiento de datos incluso a costa de la latencia.
- Problema de archivos pequeños: tener muchos archivos pequeños dará como resultado muchas búsquedas y muchos movimientos de un Node de datos a otro para recuperar cada archivo pequeño, todo este proceso es un patrón de acceso a datos muy ineficiente.