En este artículo, veremos cómo nombrar columnas agregadas en el marco de datos de Pyspark.
Podemos hacer esto usando un alias después de groupBy(). groupBy() se usa para unir dos columnas y se usa para agregar las columnas, el alias se usa para cambiar el nombre de la nueva columna que se forma al agrupar datos en columnas.
Sintaxis : dataframe.groupBy(“nombre_columna1”) .agg(función_agregada(“nombre_columna2”).alias(“nombre_nueva_columna”))
Dónde
- dataframe es el dataframe de entrada
- La función agregada se usa para agrupar la columna como sum(),avg(),count()
- new_column_name es el nombre de la nueva dcolumn agregada
- alias es la palabra clave utilizada para obtener el nuevo nombre de columna
Creando Dataframe para demostración:
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data with 10 row values
data =[["1","sravan","IT",45000],
["2","ojaswi","IT",30000],
["3","bobby","business",45000],
["4","rohith","IT",45000],
["5","gnanesh","business",120000],
["6","siva nagulu","sales",23000],
["7","bhanu","sales",34000],
["8","sireesha","business",456798],
["9","ravi","IT",230000],
["10","devi","business",100000],
]
# specify column names
columns=['ID','NAME','sector','salary']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data,columns)
# display dataframe
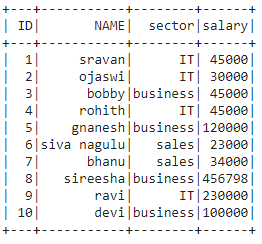
dataframe.show()
Producción:
Ejemplo 1: programa Python para agrupar el salario entre diferentes sectores y nombrar como Employee_salary por agregación de suma. La función sum() está disponible en el paquete pyspark.sql.functions, por lo que debemos importarla.
Python3
# importing sum function
from pyspark.sql.functions import sum
# group the salary among different sectors
# and name as Employee_salary by sum aggregation
dataframe.groupBy(
"sector").agg(sum("salary").alias("Employee_salary")).show()
Producción:

Ejemplo 2: programa de Python para agrupar el salario entre diferentes sectores y nombrar como Average_Employee_salary por agregación promedio
Sintaxis : avg(“nombre_columna”)
Python3
# importing avg function
from pyspark.sql.functions import avg
# group the salary among different sectors
# and name as Average_Employee_salary
# by average aggregation
dataframe.groupBy("sector")
.agg(avg(
"salary").alias("Average_Employee_salary")).show()
Producción:
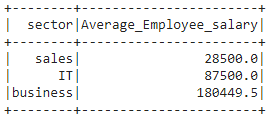
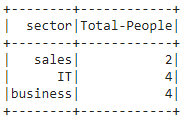
Ejemplo 3: Agrupe el salario entre diferentes sectores y nombre como Total-Personas por agregación de conteo
Python3
# importing count function
from pyspark.sql.functions import count
# group the salary among different
# sectors and name as Total-People
# by count aggregation
dataframe.groupBy("sector")
.agg(count(
"salary").alias("Total-People")).show()
Producción:
Publicación traducida automáticamente
Artículo escrito por sravankumar8128 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA