A veces, al tratar con un marco de datos grande que consta de varias filas y columnas, tenemos que filtrar el marco de datos, o queremos el subconjunto del marco de datos para aplicar la operación de acuerdo con nuestra necesidad. Para obtener un subconjunto o filtrar los datos, a veces no es suficiente con una sola condición, muchas veces tenemos que pasar las múltiples condiciones para filtrar u obtener el subconjunto de ese marco de datos. Entonces, en este artículo, vamos a aprender cómo crear subconjuntos o filtrar en función de múltiples condiciones en el marco de datos de PySpark.
Para dividir en subconjuntos o filtrar los datos del marco de datos, usamos la función filter() . La función de filtro se utiliza para filtrar los datos del marco de datos en función de la condición dada, debe ser único o múltiple.
Sintaxis: df.filter(condición)
donde df es el marco de datos del que se subconjunto o filtran los datos.
Podemos pasar las múltiples condiciones a la función de dos maneras:
- Uso de comillas dobles («condiciones»)
- Usando la notación de puntos en condición
Vamos a crear un marco de datos.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Student_report.com") \
.getOrCreate()
return spk
def create_df(spark, data, schema):
df1 = spark.createDataFrame(data, schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
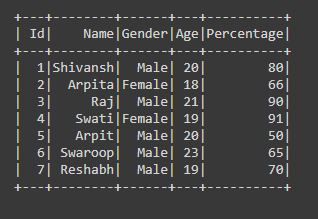
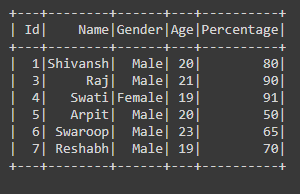
input_data = [(1, "Shivansh", "Male", 20, 80),
(2, "Arpita", "Female", 18, 66),
(3, "Raj", "Male", 21, 90),
(4, "Swati", "Female", 19, 91),
(5, "Arpit", "Male", 20, 50),
(6, "Swaroop", "Male", 23, 65),
(7, "Reshabh", "Male", 19, 70)]
schema = ["Id", "Name", "Gender", "Age", "Percentage"]
# calling function to create dataframe
df = create_df(spark, input_data, schema)
df.show()
Producción:
Apliquemos el filtro aquí:
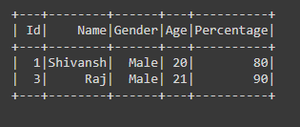
Ejemplo 1: Uso del operador ‘ y’ entre comillas dobles («»)
Python
# subset or filter the dataframe by
# passing Multiple condition
df = df.filter("Gender == 'Male' and Percentage>70")
df.show()
Producción:
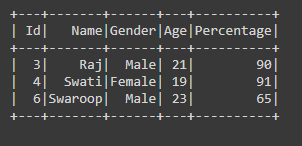
Ejemplo 2: Uso del operador ‘o ‘ entre comillas dobles («»)
Python
# subset or filter the data with
# multiple condition
df = df.filter("Age>20 or Percentage>80")
df.show()
Producción:
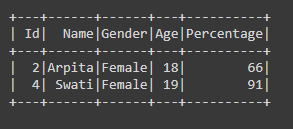
Ejemplo 3: Usar el operador ‘& ‘ con el operador (.)
Python
# subset or filter the dataframe by # passing Multiple condition df = df.filter((df.Gender=='Female') & (df.Age>=18)) df.show()
Producción:
Ejemplo 4: Usando el ‘| ‘ operador con el operador (.)
Python
# subset or filter the data with # multiple condition df = df.filter((df.Gender=='Male') | (df.Percentage>90)) df.show()
Producción:
Publicación traducida automáticamente
Artículo escrito por srishivansh5404 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA