En este artículo, discutiremos cómo manejar valores duplicados en un marco de datos pyspark. Un conjunto de datos puede contener filas repetidas o puntos de datos repetidos que no son útiles para nuestra tarea. Estos valores repetidos en nuestro marco de datos se denominan valores duplicados.
Para manejar valores duplicados, podemos usar una estrategia en la que mantenemos la primera aparición de los valores y descartamos el resto.
dropduplicates(): el marco de datos de Pyspark proporciona la función dropduplicates() que se usa para eliminar ocurrencias duplicadas de datos dentro de un marco de datos.
Sintaxis: dataframe_name.dropDuplicates(Column_name)
La función toma los nombres de las columnas como parámetros con respecto a los cuales se deben eliminar los valores duplicados.
Creando Dataframe para demostración:
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField,
StringType, IntegerType, FloatType
# Start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# Initialize our data
data2 = [("Pulkit", 12, "CS32", 82, "Programming"),
("Ritika", 20, "CS32", 94, "Writing"),
("Ritika", 20, "CS32", 84, "Writing"),
("Atirikt", 4, "BB21", 58, "Doctor"),
("Atirikt", 4, "BB21", 78, "Doctor"),
("Ghanshyam", 4, "DD11", 38, "Lawyer"),
("Reshav", 18, "EE43", 56, "Timepass")
]
# Define schema
schema = StructType([
StructField("Name", StringType(), True),
StructField("Roll Number", IntegerType(), True),
StructField("Class ID", StringType(), True),
StructField("Marks", IntegerType(), True),
StructField("Extracurricular", StringType(), True)
])
# read the dataframe
df = spark.createDataFrame(data=data2, schema=schema)
df.show()
Producción:
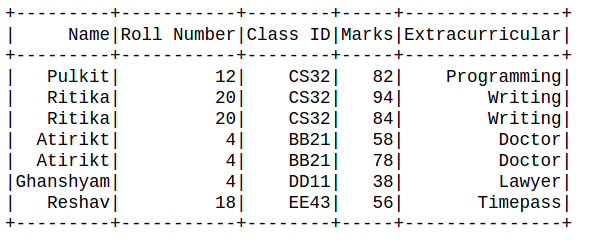
Ejemplos 1: Este ejemplo ilustra el funcionamiento de la función dropDuplicates() sobre un parámetro de una sola columna. El conjunto de datos está hecho a medida, por lo que definimos el esquema y usamos la función spark.createDataFrame() para crear el marco de datos.
Python3
# drop duplicates df.dropDuplicates(['Roll Number']).show() # stop Session spark.stop()
Producción:
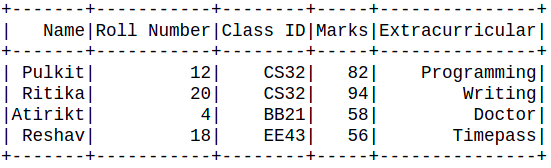
De la observación anterior, está claro que las filas con número de rollo duplicado se eliminaron y solo se mantuvo la primera aparición en el marco de datos.
Ejemplo 2: este ejemplo ilustra el funcionamiento de la función dropDuplicates() en varios parámetros de columna. El conjunto de datos está personalizado, por lo que definimos el esquema y usamos la función spark.createDataFrame() para crear el marco de datos.
Python3
# drop duplicates df.dropDuplicates(['Roll Number',"Name"]).show() # stop the session spark.stop()
Producción:
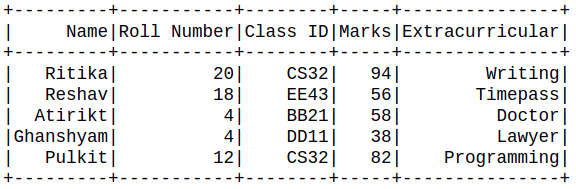
De la observación anterior, está claro que los puntos de datos con Números de rollo y Nombres duplicados se eliminaron y solo se mantuvo la primera aparición en el marco de datos.
Nota: Los datos que tenían ambos parámetros como un duplicado solo se eliminaron. En el ejemplo anterior, el Nombre de columna de «Ghanshyam» tenía un valor duplicado de Número de rollo, pero el Nombre era único, por lo que no se eliminó del marco de datos. Por lo tanto, la función considera todos los parámetros, no solo uno de ellos.
Publicación traducida automáticamente
Artículo escrito por pulkit12dhingra y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA