En este artículo, veremos cómo recorrer cada fila de Dataframe en PySpark. Recorrer cada fila nos ayuda a realizar operaciones complejas en el RDD o Dataframe.
Creando Dataframe para demostración:
Python3
# importing necessary libraries
import pyspark
from pyspark.sql import SparkSession
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("employee_profile.com") \
.getOrCreate()
return spk
def create_df(spark, data, schema):
df1 = spark.createDataFrame(data, schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
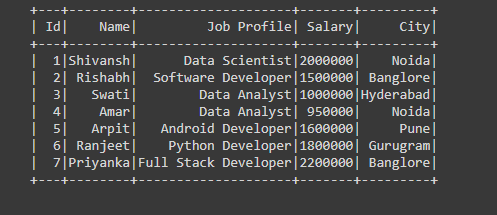
input_data = [(1, "Shivansh", "Data Scientist", "Noida"),
(2, "Rishabh", "Software Developer", "Banglore"),
(3, "Swati", "Data Analyst", "Hyderabad"),
(4, "Amar", "Data Analyst", "Noida"),
(5, "Arpit", "Android Developer", "Pune"),
(6, "Ranjeet", "Python Developer", "Gurugram"),
(7, "Priyanka", "Full Stack Developer", "Banglore")]
schema = ["Id", "Name", "Job Profile", "City"]
# calling function to create dataframe
df = create_df(spark, input_data, schema)
# retrieving all the elements of
# the dataframe using collect()
# Storing in the variable
data_collect = df.collect()
df.show()
Producción:
Método 1: usar recopilar()
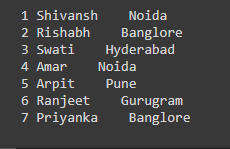
Podemos usar la operación de acción collect() para recuperar todos los elementos del conjunto de datos en la función del controlador y luego recorrerlo usando for loop.
Python3
# retrieving all the elements # of the dataframe using collect() # Storing in the variable data_collect = df.collect() # looping thorough each row of the dataframe for row in data_collect: # while looping through each # row printing the data of Id, Name and City print(row["Id"],row["Name"]," ",row["City"])
Producción:
Método 2: Usando toLocalIterator()
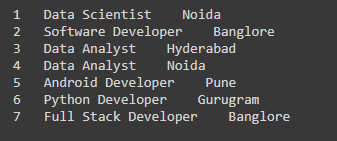
Podemos usar toLocalIterator(). Esto devuelve un iterador que contiene todas las filas en el DataFrame. Es similar a recopilar(). La única diferencia es que collect() devuelve la lista mientras que toLocalIterator() devuelve un iterador.
Python
data_itr = df.rdd.toLocalIterator() # looping thorough each row of the dataframe for row in data_itr: # while looping through each row printing # the data of Id, Job Profile and City print(row["Id"]," ",row["Job Profile"]," ",row["City"])
Producción:
Nota: Esta función es similar a la función de recopilación() que se usa en el ejemplo anterior, la única diferencia es que esta función devuelve el iterador, mientras que la función de recopilación() devuelve la lista.
Método 3: Usar iterrows()
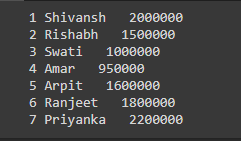
La función iterrows() para iterar a través de cada fila del Dataframe, es la función de la biblioteca pandas, por lo que primero, tenemos que convertir el PySpark Dataframe en Pandas Dataframe usando la función toPandas(). Luego recorrelo usando for loop.
Python
pd_df = df.toPandas() # looping through each row using iterrows() # used to iterate over dataframe rows as index, # series pair for index, row in pd_df.iterrows(): # while looping through each row # printing the Id, Name and Salary # by passing index instead of Name # of the column print(row[0],row[1]," ",row[3])
Producción:
Método 4: Usar mapa()
Función map() con función lambda para iterar a través de cada fila de Dataframe. Para recorrer cada fila usando map() primero, tenemos que convertir el marco de datos de PySpark en RDD porque map() se realiza solo en RDD, así que primero conviértalo en RDD y luego use map() en el cual, función lambda para iterar a través de cada fila y almacena el nuevo RDD en alguna variable y luego vuelve a convertir ese nuevo RDD en Dataframe usando toDF() pasándole el esquema.
Python
# importing necessary libraries
import pyspark
from pyspark.sql import SparkSession
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("employee_profile.com") \
.getOrCreate()
return spk
def create_df(spark,data,schema):
df1 = spark.createDataFrame(data,schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
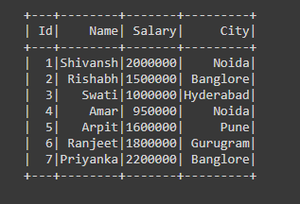
input_data = [(1,"Shivansh","Data Scientist",2000000,"Noida"),
(2,"Rishabh","Software Developer",1500000,"Banglore"),
(3,"Swati","Data Analyst",1000000,"Hyderabad"),
(4,"Amar","Data Analyst",950000,"Noida"),
(5,"Arpit","Android Developer",1600000,"Pune"),
(6,"Ranjeet","Python Developer",1800000,"Gurugram"),
(7,"Priyanka","Full Stack Developer",2200000,"Banglore")]
schema = ["Id","Name","Job Profile","Salary","City"]
# calling function to create dataframe
df = create_df(spark,input_data,schema)
# map() is only be performed on rdd
# so converting the dataframe into rdd using df.rdd
rdd = df.rdd.map(lambda loop: (
loop["Id"],loop["Name"],loop["Salary"],loop["City"])
)
# after looping the getting the data from each row
# converting back from RDD to Dataframe
df2 = rdd.toDF(["Id","Name","Salary","City"])
# showing the new Dataframe
df2.show()
Producción:
Método 5: Usar la comprensión de listas
Podemos usar la comprensión de listas para recorrer cada fila que discutiremos en el ejemplo.
Python
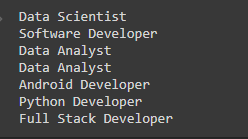
# using list comprehension for looping # through each row storing the list of # data in the variable table = [x["Job Profile"] for x in df.rdd.collect()] # looping the list for printing for row in table: print(row)
Producción:
Método 6: Usar select()
La función select() se utiliza para seleccionar el número de columnas. Después de seleccionar las columnas, usamos la función collect() que devuelve la lista de filas que contiene solo los datos de las columnas seleccionadas.
Python
# importing necessary libraries
import pyspark
from pyspark.sql import SparkSession
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("employee_profile.com") \
.getOrCreate()
return spk
def create_df(spark, data, schema):
df1 = spark.createDataFrame(data, schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [(1, "Shivansh", "Data Scientist", 2000000, "Noida"),
(2, "Rishabh", "Software Developer", 1500000, "Banglore"),
(3, "Swati", "Data Analyst", 1000000, "Hyderabad"),
(4, "Amar", "Data Analyst", 950000, "Noida"),
(5, "Arpit", "Android Developer", 1600000, "Pune"),
(6, "Ranjeet", "Python Developer", 1800000, "Gurugram"),
(7, "Priyanka", "Full Stack Developer", 2200000, "Banglore")]
schema = ["Id", "Name", "Job Profile", "Salary", "City"]
# calling function to create dataframe
df = create_df(spark, input_data, schema)
# getting each row of dataframe containing
# only selected columns Selected columns are
# 'Name' and 'Salary' getting the list of rows
# with selected column data using collect()
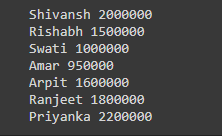
rows_looped = df.select("Name", "Salary").collect()
# printing the data of each row
for rows in rows_looped:
# here index 0 and 1 refers to the data
# of 'Name' column and 'Salary' column
print(rows[0], rows[1])
Producción:
Publicación traducida automáticamente
Artículo escrito por srishivansh5404 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA