La ciencia de datos es un campo interdisciplinario que se enfoca en extraer conocimiento de conjuntos de datos que suelen ser enormes en cantidad. El campo abarca el análisis, la preparación de datos para el análisis y la presentación de hallazgos para informar decisiones de alto nivel en una organización. Como tal, incorpora habilidades de informática, matemáticas, estática, visualización de información, gráficos y negocios.
En palabras simples, una canalización en ciencia de datos es “ un conjunto de acciones que cambia los datos sin procesar (y confusos) de varias fuentes (encuestas, comentarios, lista de compras, votos , etc.), a un formato comprensible para que podamos guárdelo y utilícelo para el análisis”.
Pero además del almacenamiento y el análisis, es importante formular las preguntas que resolveremos usando nuestros datos. Y estas preguntas arrojarían la información oculta que nos dará el poder de predecir resultados, como un mago . Por ejemplo:
- ¿Qué tipo de ventas reducirá los riesgos?
- ¿Qué producto se venderá más durante una crisis?
- ¿Qué práctica puede generar más negocios?
Después de responder a nuestras preguntas, ahora estamos listos para ver qué hay dentro de la tubería de ciencia de datos. Cuando los datos sin procesar ingresan a una canalización, no está seguro de cuánto potencial contiene. Somos nosotros, los científicos de datos, que esperamos ansiosamente dentro de la tubería, quienes sacamos a relucir su valor limpiándolo, explorándolo y finalmente utilizándolo de la mejor manera posible. Entonces, para comprender su viaje, saltemos a la tubería.
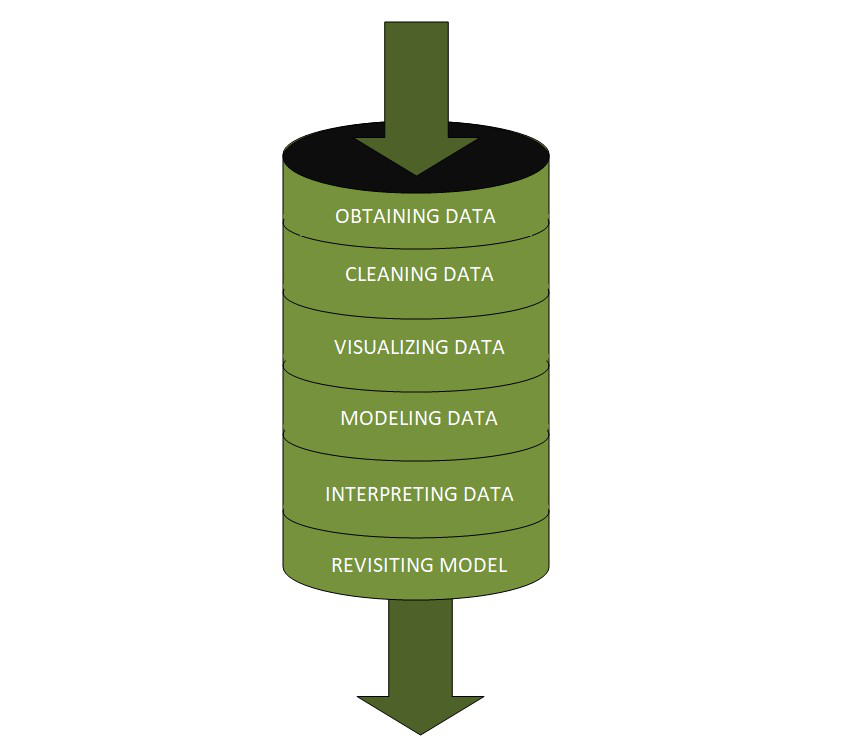
Los datos sin procesar pasan por diferentes etapas dentro de una tubería que son:
Esta etapa implica la identificación de datos de Internet o bases de datos internas/externas y extractos en formatos útiles. Habilidades previas:
- Almacenamiento distribuido: Hadoop, Apache Spark/Flink.
- Manejo de base de datos: MySQL, PostgresSQL, MongoDB.
- Consulta de bases de datos relacionales.
- Recuperación de datos no estructurados: texto, videos, archivos de audio, documentos.
Esta es la etapa que consume más tiempo y requiere más esfuerzo. Se divide además en dos etapas:
- Examen de datos:
- identificar errores
- identificando valores perdidos
- identificar registros corruptos
- Limpieza de datos:
- reemplazar o completar valores faltantes/errores
Habilidades previas:
- Lenguaje de codificación: Python, R.
- Herramientas de modificación de datos: Python libs, Numpy, Pandas, R.
- Procesamiento Distribuido: Hadoop, Map Reduce/Spark.
3) Análisis de datos exploratorios
Cuando los datos llegan a esta etapa de la tubería, están libres de errores y valores faltantes y, por lo tanto, son adecuados para encontrar patrones utilizando visualizaciones y gráficos.
Habilidades previas:
- Python : NumPy, Matplotlib, Pandas, SciPy.
- R : GGplot2, Dplyr.
- Estadística : Muestreo aleatorio, Inferencial.
- Visualización de datos : Tableau.
4) Modelado de los datos
Esta es la etapa de la canalización de la ciencia de datos en la que entra en juego el aprendizaje automático. Con la ayuda del aprendizaje automático, creamos modelos de datos. Los modelos de datos no son más que reglas generales en un sentido estadístico, que se utilizan como una herramienta predictiva para mejorar nuestra toma de decisiones comerciales.
Habilidades previas:
- Aprendizaje automático : algoritmos supervisados/no supervisados.
- Métodos de evaluación.
- Bibliotecas de aprendizaje automático : Python (Sci-kit Learn, NumPy).
- Álgebra lineal y cálculo multivariado.
5) Interpretación de los datos
Similar a parafrasear su modelo de ciencia de datos. Recuerda siempre, si no puedes explicárselo a un niño de seis años, no lo entiendes tú mismo. Entonces, ¡la comunicación se convierte en la clave! Esta es la etapa más crucial de la tubería, con el uso de técnicas psicológicas, el conocimiento correcto del dominio comercial y sus inmensas habilidades para contar historias, puede explicar su modelo a la audiencia no técnica.
Habilidades previas:
- Conocimiento del dominio empresarial.
- Herramientas de visualización de datos : Tableau, D3.js, Matplotlib, ggplot2, Seaborn.
- Comunicación : Presentar/hablar e informar/escribir.
6) Revisión
A medida que cambia la naturaleza del negocio, se introducen nuevas características que pueden degradar sus modelos existentes. Por lo tanto, las revisiones y actualizaciones periódicas son muy importantes tanto desde el punto de vista empresarial como del científico de datos.
Conclusión
La ciencia de datos no se trata de grandes algoritmos de aprendizaje automático, sino de las soluciones que proporciona con el uso de esos algoritmos. También es muy importante asegurarse de que su tubería se mantenga sólida de principio a fin, e identifique los problemas comerciales precisos para poder generar soluciones precisas.
Publicación traducida automáticamente
Artículo escrito por mprerna802 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA