Plotly es una biblioteca de Python que se utiliza para diseñar gráficos, especialmente gráficos interactivos. Puede trazar varios gráficos y cuadros como histograma, diagrama de barras, diagrama de caja, diagrama de dispersión y muchos más. Se utiliza principalmente en el análisis de datos, así como en el análisis financiero. plotly es una biblioteca de visualización interactiva.
diagrama de caja
Un diagrama de caja es una representación demográfica de datos numéricos a través de sus cuartiles. Los cuartiles final y superior se representan en un recuadro, mientras que la mediana (segundo cuartil) se destaca mediante una línea dentro del recuadro. Plotly.express es una interfaz conveniente y de alto rango para trazar que opera en una variedad de datos y produce una figura fácil de diseñar. Las cajas son muy beneficiosas para comparar los grupos de datos. Diagrama de caja dividir aprox. El 25% de los datos de la sección en conjuntos, lo que ayuda a identificar rápidamente los valores, la dispersión del conjunto de datos y los signos de asimetría.
Sintaxis: plotly.express.box(data_frame=Ninguno, x=Ninguno, y=Ninguno, color=Ninguno, facet_row=Ninguno, facet_col=Ninguno, facet_col_wrap=0, hover_name=Ninguno, hover_data=Ninguno, custom_data=Ninguno, animation_frame= Ninguno, animation_group=Ninguno, category_orders={}, etiquetas={}, color_discrete_sequence=Ninguno, color_discrete_map={}, orientación=Ninguno, boxmode=Ninguno, log_x=False, log_y=False, range_x=Ninguno, range_y=Ninguno, puntos =Ninguno, con muescas=Falso, título=Ninguno, plantilla=Ninguno, ancho=Ninguno, alto=Ninguno)
Parámetros:
| Nombre | Descripción |
|---|---|
| marco de datos | Este argumento debe pasarse para que se utilicen los nombres de las columnas (y no los nombres de las palabras clave). Array-like y dict se transforman internamente en un DataFrame de pandas. Opcional: si falta, un DataFrame se construye bajo el capó usando los otros argumentos. |
| X | Ya sea un nombre de una columna en data_frame, o una serie de pandas o un objeto similar a una array. Los valores de esta columna o array_like se utilizan para colocar marcas a lo largo del eje x en coordenadas cartesianas. Opcionalmente, x o y pueden ser una lista de referencias de columna o array_likes, en cuyo caso los datos se tratarán como si fueran ‘anchos’ en lugar de ‘largos’. |
| y | Ya sea un nombre de una columna en data_frame, o una serie de pandas o un objeto similar a una array. Los valores de esta columna o array_like se utilizan para colocar marcas a lo largo del eje y en coordenadas cartesianas. Opcionalmente, x o y pueden ser una lista de referencias de columna o array_likes, en cuyo caso los datos se tratarán como si fueran ‘anchos’ en lugar de ‘largos’. |
| color | Ya sea un nombre de una columna en data_frame, o una serie de pandas o un objeto similar a una array. Los valores de esta columna o array_like se utilizan para asignar color a las marcas. |
| faceta_fila | Ya sea un nombre de una columna en data_frame, o una serie de pandas o un objeto similar a una array. Los valores de esta columna o array_like se utilizan para asignar marcas a las subparcelas con facetas en la dirección vertical. |
| faceta_col | Ya sea un nombre de una columna en data_frame, o una serie de pandas o un objeto similar a una array. Los valores de esta columna o array_like se utilizan para asignar marcas a las subparcelas con facetas en la dirección horizontal. |
| facet_col_wrap | Número máximo de columnas de facetas. Envuelve la variable de columna con este ancho, de modo que las facetas de la columna abarquen varias filas. Se ignora si es 0 y se fuerza a 0 si se establece facet_row o un marginal. |
| hover_name | Ya sea un nombre de una columna en data_frame, o una serie de pandas o un objeto similar a una array. Los valores de esta columna o array_like aparecen en negrita en la información sobre herramientas flotante. |
| hover_data | Ya sea una lista de nombres de columnas en data_frame, o pandas Series, u array_like objects o un dict con nombres de columnas como claves, con valores True (para el formato predeterminado) False (para eliminar esta columna de la información flotante), o un formato string, por ejemplo, ‘:.3f’ o ‘|%a’ o datos similares a una lista para que aparezcan en la información sobre herramientas flotante o tuplas con un bool o string de formato como primer elemento, y datos similares a una lista para que aparezcan al pasar el mouse como segundo elemento Los valores de estas columnas aparecen como datos adicionales en la información sobre herramientas flotante. |
| datos_personalizados | Ya sea nombres de columnas en data_frame, o pandas Series, u objetos tipo array. Los valores de estas columnas son datos adicionales, para usarse en widgets o devoluciones de llamada de Dash, por ejemplo. Estos datos no son visibles para el usuario, pero se incluyen en los eventos emitidos por la figura (selección de lazo, etc.) |
| cuadro_animación | Ya sea un nombre de una columna en data_frame, o una serie de pandas o un objeto similar a una array. Los valores de esta columna o array_like se utilizan para asignar marcas a los cuadros de animación. |
| grupo_animacion | Ya sea un nombre de una columna en data_frame, o una serie de pandas o un objeto similar a una array. Los valores de esta columna o array_like se utilizan para proporcionar constancia de objetos en los fotogramas de animación: las filas con ‘animation_group’ coincidentes se tratarán como si describieran el mismo objeto en cada fotograma. |
| categorías_pedidos | De forma predeterminada, en Python 3.6+, el orden de los valores categóricos en ejes, leyendas y facetas depende del orden en que estos valores se encuentran por primera vez en data_frame (y no se garantiza ningún orden de forma predeterminada en Python anterior a 3.6). Este parámetro se utiliza para forzar un orden específico de valores por columna. Las claves de este dict deben corresponder a los nombres de las columnas, y los valores deben ser listas de strings correspondientes al orden de visualización específico deseado. |
| etiquetas | De forma predeterminada, los nombres de las columnas se utilizan en la figura para los títulos de los ejes, las entradas de la leyenda y los elementos flotantes. Este parámetro permite anular esto. Las claves de este dict deben corresponder a los nombres de las columnas, y los valores deben corresponder a la etiqueta que se desea mostrar. |
| color_discrete_sequence | Las strings deben definir colores CSS válidos. Cuando se establece color y los valores de la columna correspondiente no son numéricos, a los valores de esa columna se les asignan colores recorriendo color_discrete_sequence en el orden descrito en category_orders, a menos que el valor de color sea una clave en color_discrete_map. Varias secuencias de colores útiles están disponibles en los submódulos plotly.express.colors, específicamente plotly.express.colors.qualitative. |
| color_discrete_map | Los valores de string deben definir colores CSS válidos. Se utiliza para anular color_discrete_sequence para asignar colores específicos a las marcas correspondientes a valores específicos. Las claves en color_discrete_map deben ser valores en la columna indicada por color. Alternativamente, si los valores de color son colores válidos, se puede pasar la string ‘identity’ para que se usen directamente. |
| orientación | (‘v’ por defecto si se proporcionan x e y y ambos son continuos o ambos categóricos; de lo contrario, ‘v’`(‘h’) si `x`(`y) es categórico e y`(`x) es continuo; de lo contrario, ‘ v»(‘h’) si solo se proporciona `x`(`y)) |
| modo caja | Uno de ‘grupo’ o ‘superposición’ En el modo ‘superposición’, los cuadros se dibujan uno encima del otro. En el modo ‘grupo’, las cajas se colocan una al lado de la otra. |
| log_x | Si es Verdadero, el eje x se escala logarítmicamente en coordenadas cartesianas. |
| pesado | Si es Verdadero, el eje y se escala logarítmicamente en coordenadas cartesianas. |
| rango_x | Si se proporciona, anula el ajuste de escala automático en el eje x en coordenadas cartesianas. |
| rango_y | Si se proporciona, anula el ajuste de escala automático en el eje y en coordenadas cartesianas. |
| puntos | Uno de ‘valores atípicos’, ‘valores atípicos sospechosos’, ‘todos’ o Falso. Si son ‘valores atípicos’, solo se muestran los puntos de muestra que se encuentran fuera de los bigotes. Si se trata de ‘valores atípicos sospechosos’, se muestran todos los puntos de valores atípicos y los que tienen menos de 4*Q1-3*Q3 o más de 4*Q3-3*Q1 se resaltan con el ‘color de valor atípico’ del marcador. Si son ‘valores atípicos’, solo se muestran los puntos de muestra que se encuentran fuera de los bigotes. Si ‘todos’, se muestran todos los puntos de muestra. Si es Falso, no se muestran puntos de muestra y los bigotes se extienden a todo el rango de la muestra. |
| mellado | Si es True, los cuadros se dibujan con muescas. |
| título | El título de la figura. |
| modelo | El nombre de la plantilla de figura (debe ser una clave en plotly.io.templates) o definición. |
| ancho | El ancho de la figura en píxeles. |
| altura | La altura de la figura en píxeles. |
Ejemplo 1: Usar el conjunto de datos de Iris
Python3
import plotly.express as px df = px.data.iris() fig = px.box(df, x="sepal_width", y="sepal_length") fig.show()
Producción:
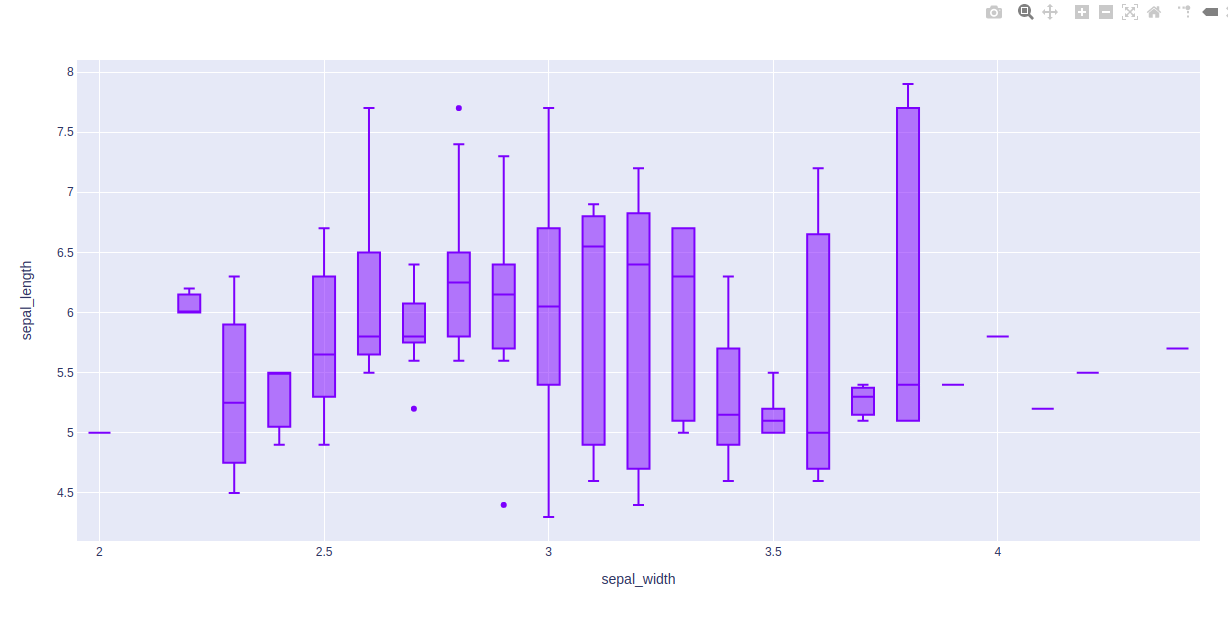
Ejemplo 2: uso del conjunto de datos de sugerencias
Python3
import plotly.express as px df = px.data.tips() fig = px.box(df, x = "sex", y="total_bill") fig.show()
Producción:
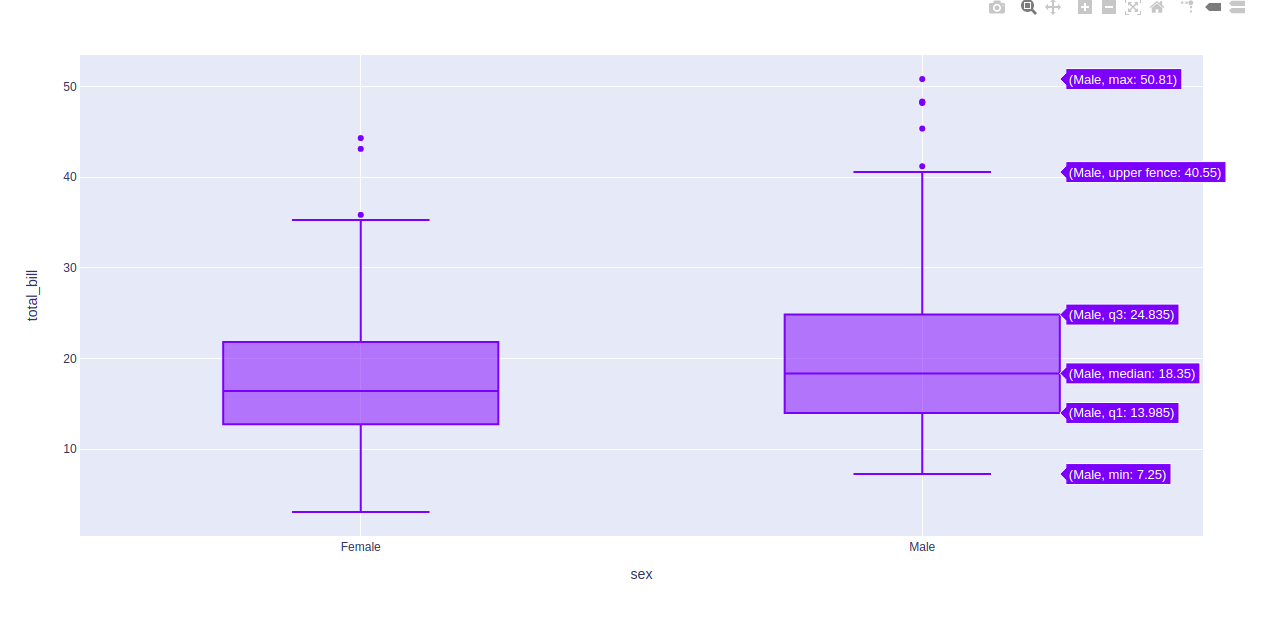
En los ejemplos anteriores, tomemos el primer diagrama de caja de la figura y entendamos estas cosas estadísticas:
- La línea horizontal inferior del diagrama de caja es el valor mínimo
- La primera línea horizontal de la forma de rectángulo del diagrama de caja es el primer cuartil o 25%
- La segunda línea horizontal de forma rectangular del diagrama de caja es el segundo cuartil o el 50% o la mediana.
- La tercera línea horizontal de forma rectangular del diagrama de caja es el tercer cuartil o 75%
- La línea horizontal superior de la forma de rectángulo del diagrama de caja es el valor máximo.
- La forma de diamante pequeño del gráfico de caja azul es un dato atípico o erróneo.
Cambio de algoritmo para cuartiles
El algoritmo para elegir cuartiles también se puede seleccionar en plotly. Se calcula utilizando un algoritmo lineal de forma predeterminada. Sin embargo, proporciona dos algoritmos más para hacer lo mismo, es decir, inclusivo y exclusivo.
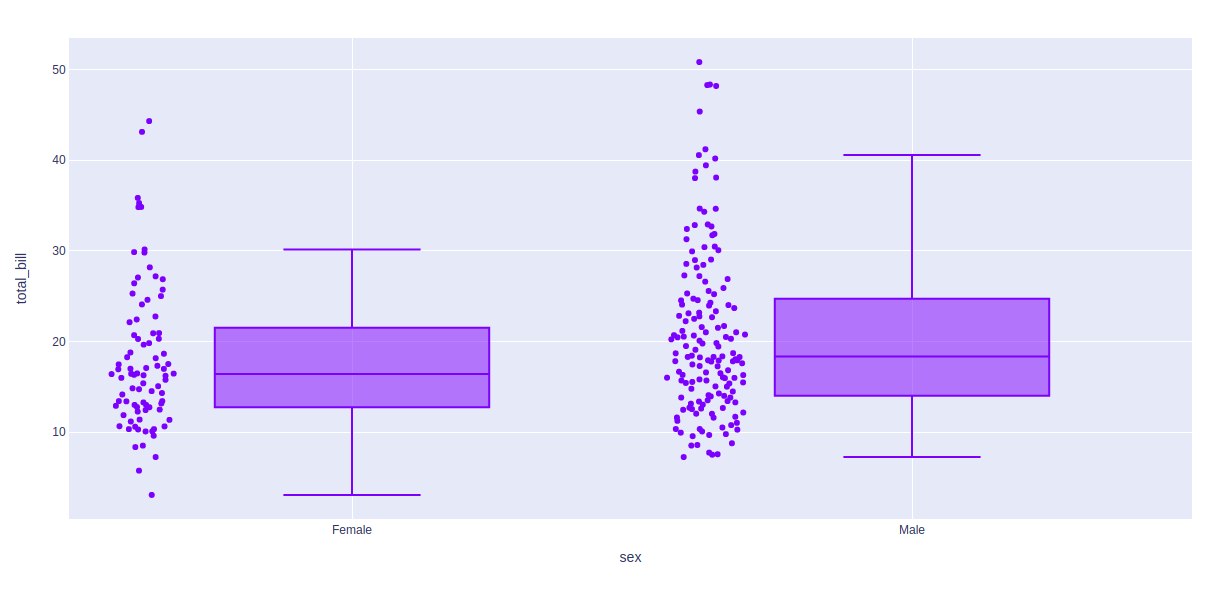
Ejemplo 1: Uso de algoritmo inclusivo
Python3
import plotly.express as px df = px.data.tips() fig = px.box(df, x = "sex", y="total_bill", points="all") fig.update_traces(quartilemethod="inclusive") fig.show()
Producción:
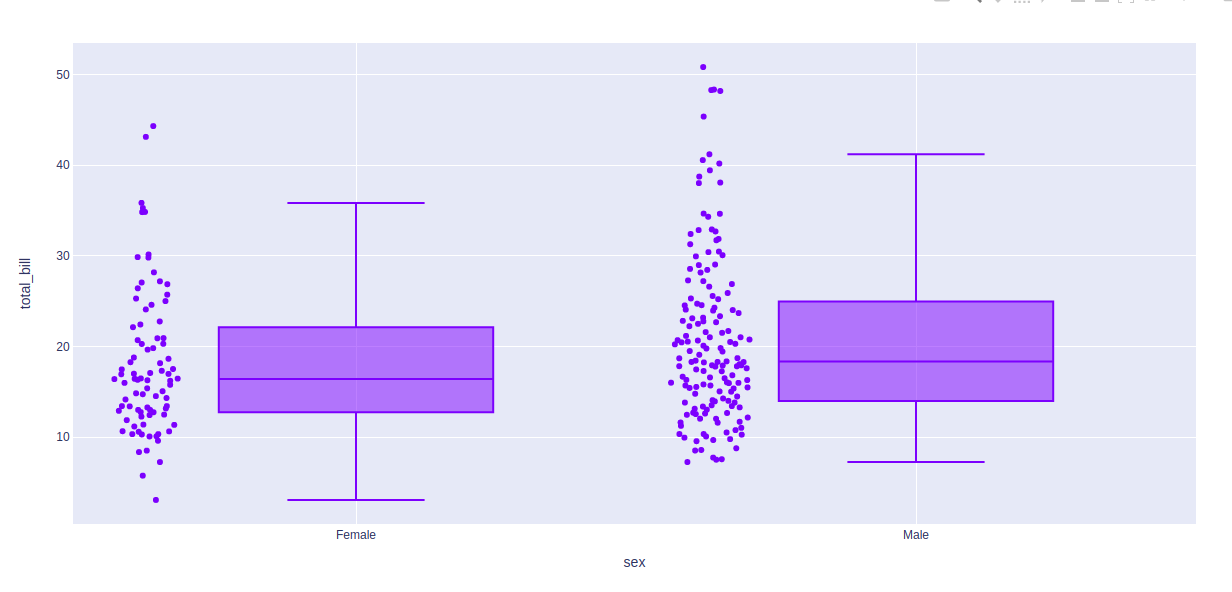
Ejemplo 2: Uso de algoritmo exclusivo
Python3
import plotly.express as px df = px.data.tips() fig = px.box(df, x = "sex", y="total_bill", points="all") fig.update_traces(quartilemethod="exclusive") fig.show()
Producción:
Mostrando los datos subyacentes
Los datos subyacentes se pueden mostrar usando los argumentos de puntos. El valor de este argumento puede ser de tres tipos:
- todo por todos los puntos
- valores atípicos solo para valores atípicos
- falso para ninguno de los anteriores
Ejemplo 1: pasar todo como argumento
Python3
import plotly.express as px df = px.data.tips() fig = px.box(df, x = "sex", y="total_bill", points="all") fig.show()
Producción:
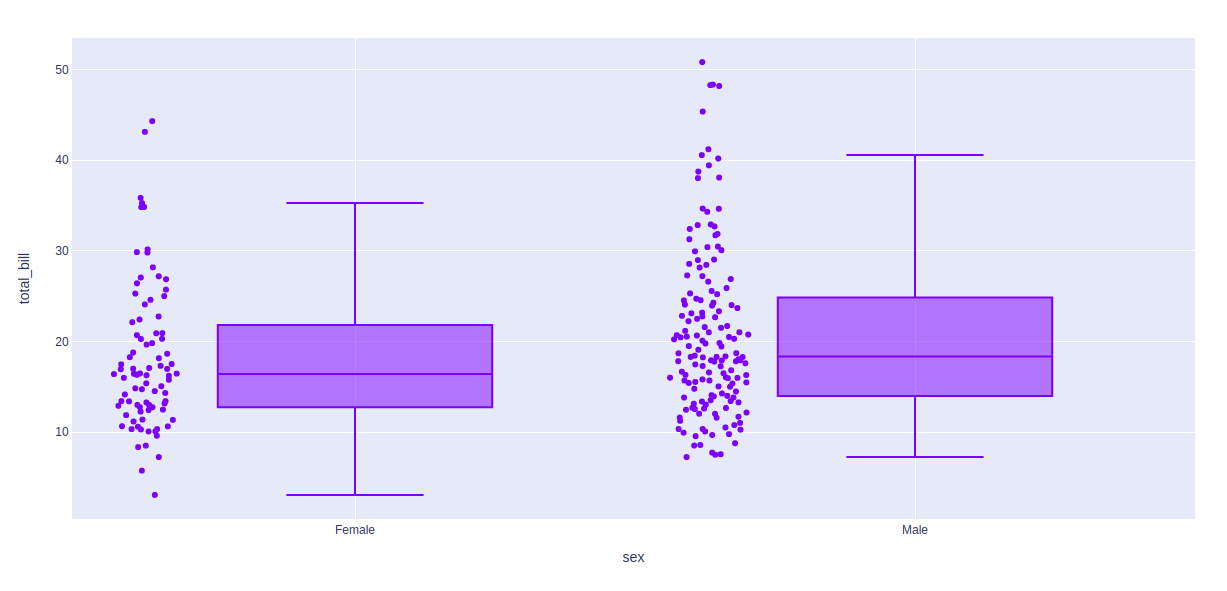
Ejemplo 2:
Python3
import plotly.express as px df = px.data.tips() fig = px.box(df, x = "sex", y="total_bill", points="outliers") fig.show()
Producción:
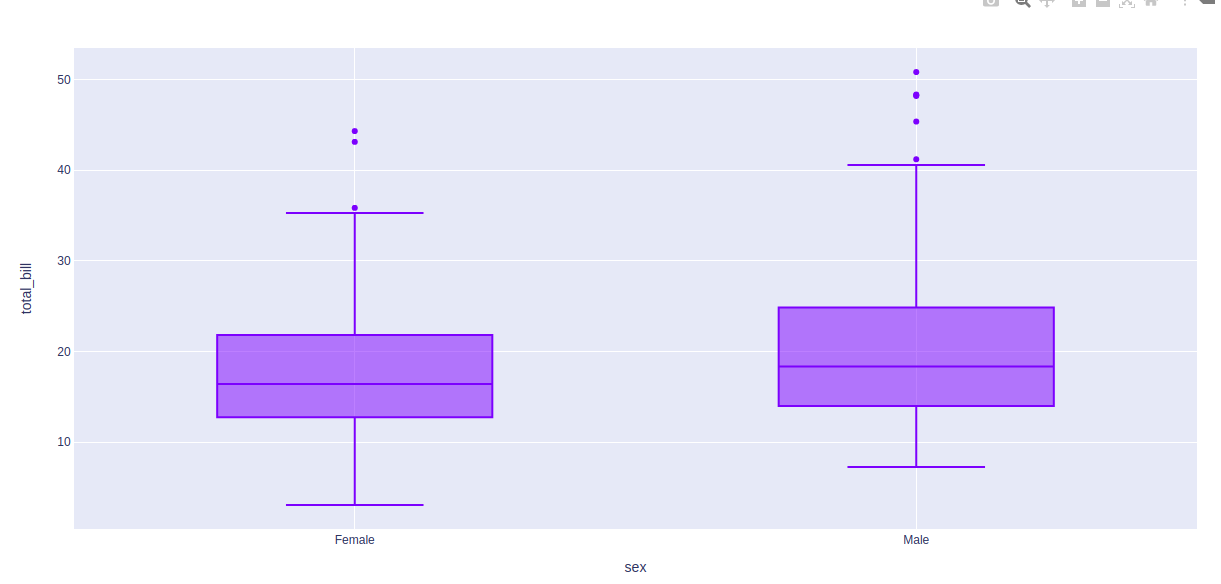
Diagrama de caja de estilo
Boxplot viene con varias opciones de estilo. Veamos una de esas opciones en el siguiente ejemplo.
Ejemplo:
Python3
import plotly.express as px df = px.data.tips() fig = px.box(df, x = "sex", y="total_bill", points="all", notched=True) fig.update_traces(quartilemethod="exclusive") fig.show()
Producción:
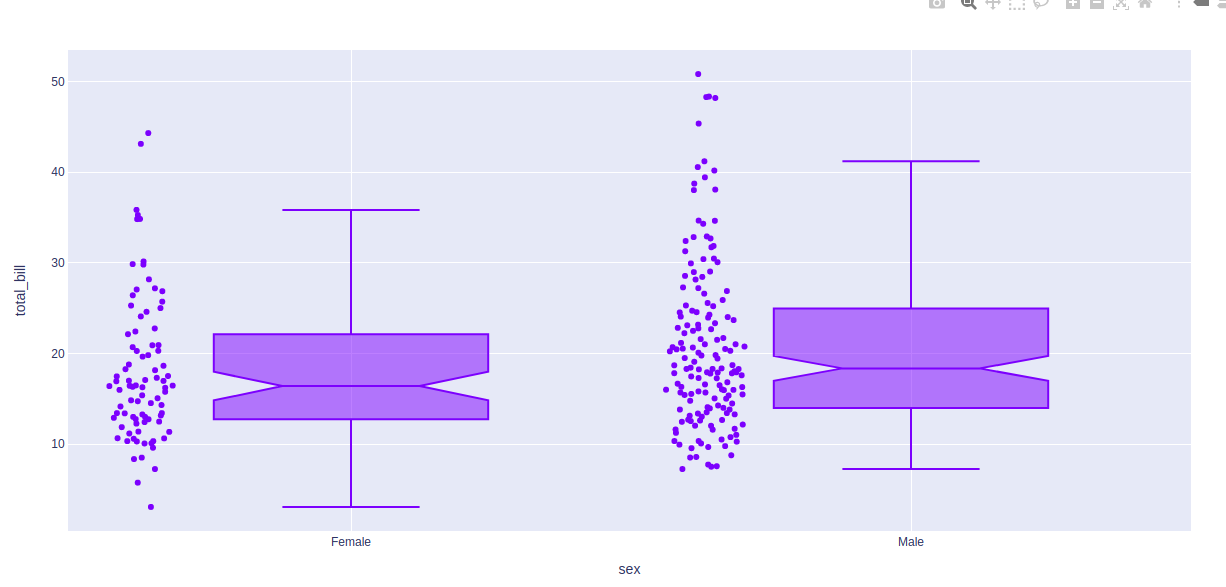
Publicación traducida automáticamente
Artículo escrito por nishantsundriyal98 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA