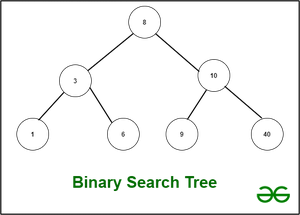
1. Árbol de búsqueda binaria :
un gráfico acíclico se usa comúnmente para ilustrar un árbol de búsqueda binaria. El árbol está formado por Nodes. Cada Node en un árbol binario no tiene más de dos hijos. El valor de cada Node es estrictamente mayor que el valor de su hijo izquierdo y estrictamente menor que el valor de su hijo derecho, según la BST. Es decir, podemos iterar a través de todos los valores BST en orden ordenado. Además, no se permiten valores duplicados en esta estructura de datos.
Hay dos tipos de árboles de búsqueda binarios: equilibrados y no equilibrados.
Suponga que el número de Nodes en un BST es n. O(n) es el peor de los casos para las operaciones de inserción y extracción. Sin embargo, en un árbol de búsqueda binario equilibrado, como AVL o Red-Black Tree, las operaciones similares tienen una complejidad de tiempo de O(log(n)). Otro punto importante a recordar es que construir un BST con n Nodes toma O(n * log(n)) tiempo. Debemos insertar un Node n veces, cada una de las cuales cuesta O(log(n)). El principal beneficio de un árbol de búsqueda binaria es que podemos recorrerlo en tiempo O(n) y recibir todos nuestros valores en orden ordenado.
2. Heap Tree :
Heap es un árbol binario completo.
Si la distancia entre un Node y el Node raíz es k, el Node está en el nivel k del árbol. El nivel de la raíz es cero. En el nivel k, el número máximo de Nodes que pueden existir es 2^k. Un árbol binario completo tiene el número máximo de Nodes en cada nivel. Excepto la última capa, que también debe rellenarse de izquierda a derecha. Es fundamental recordar que el árbol binario completo siempre está equilibrado.
El montón no es lo mismo que un árbol de búsqueda binario. The Heap, por otro lado, no es una estructura de datos ordenada. El montón se representa comúnmente como una array de números en la memoria de la computadora. Es posible tener un montón Min-Heap o Max-Heap. Aunque las características de Min- y Max-Heaps son casi idénticas, la raíz del árbol para Max-Heap es el número más grande y el más pequeño para Min-Heap. De manera similar, la regla básica de Max-Heap es que el subárbol de cada Node tiene valores que son menores o iguales que el Node raíz. El Min-Heap, por otro lado, es el polo opuesto. También implica que el Heap acepta duplicados.
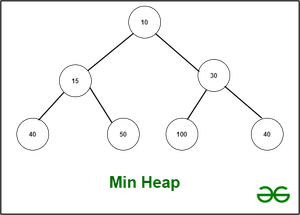
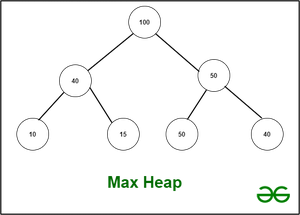
Árbol de búsqueda binaria frente a Montón:
la distinción fundamental es que, mientras que el árbol de búsqueda binaria no permite duplicados, el montón sí lo permite. Se ordena el BST, mientras que Heap no. Entonces, si el orden es importante, BST es el camino a seguir. Si un pedido no es importante, pero necesitamos saber que insertar y eliminar datos llevará tiempo O(log(n)), el Heap asegura que esto sucederá. Si el árbol está totalmente desequilibrado, esto puede llevar hasta O(n) tiempo en un árbol de búsqueda binaria (la string es el peor de los casos). Además, aunque Heap puede construirse en tiempo lineal, el BST requiere que se construya O(n * log(n)).
PriorityQueue y TreeMap son implementaciones de Java de estas estructuras. De forma predeterminada, PriorityQueue es un Max-Heap. La columna vertebral de TreeMap es un árbol de búsqueda binario equilibrado. Se utiliza un árbol rojo-negro para implementarlo.
Publicación traducida automáticamente
Artículo escrito por siddharth_25 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA