En este artículo, aprenderemos cómo importar o leer un archivo CSV en un marco de datos en el lenguaje de programación R.
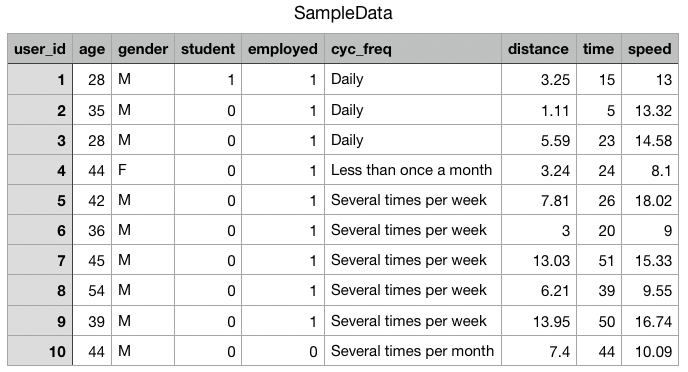
Conjunto de datos en uso:
Paso 1: establecer o cambiar el directorio de trabajo
Para importar o leer el archivo CSV dado en nuestro marco de datos, primero debemos verificar nuestro directorio de trabajo actual y asegurarnos de que el archivo CSV esté en el mismo directorio en el que se encuentra nuestro estudio R, de lo contrario, podría mostrar » Error de archivo no encontrado”.
Para verificar el directorio de trabajo actual, necesitamos usar la función getwd(), y para cambiar el directorio de trabajo actual a algún otro directorio de trabajo, necesitamos usar la función stewd().
getwd() devuelve una ruta de archivo absoluta que representa el directorio de trabajo actual del proceso R.
Sintaxis:
obtener()
setwd(dir) utilizado para establecer el directorio de trabajo en dir.
Sintaxis:
establecer(ruta)
Ejemplo:
R
# gives the current working directory
getwd()
# changes the location
setwd("C:/Users/Vanshi/Desktop/gfg")
Producción:
C:/Usuarios/Vanshi/Documentos
Paso 2: Lea el archivo CSV
Ahora que hemos establecido nuestra ruta de trabajo, importaremos el archivo CSV al marco de datos y nombraremos nuestro marco de datos como sdata.
Aquí, estamos leyendo el archivo .csv llamado «SampleData» usando el comando read.csv, en nuestro estudio R, lo que significa que estamos alimentando los valores a Rstudio para extraer información importante de él.
La función read.csv() lee un archivo en formato de tabla y crea un marco de datos a partir de él, con casos correspondientes a líneas y variables a campos en el archivo.
Sintaxis: read.csv(file, header = TRUE, sep = “,”, quote = “\””, dec = “.”, fill = TRUE, comment.char = “”, …)
Argumentos:
- archivo: el nombre del archivo del que se van a leer los datos.
- encabezado: un valor lógico que indica si el archivo contiene los nombres de las variables en su primera línea. Si falta, el valor se determina a partir del formato del archivo: el encabezado se establece en VERDADERO si y solo si la primera fila contiene un campo menos que el número de columnas.
- sep: el carácter separador de campo. Los valores en cada línea del archivo están separados por este carácter. Si sep = “” (el valor predeterminado para read.table), el separador es ‘espacio en blanco’, es decir, uno o más espacios, tabulaciones, saltos de línea o retornos de carro.
- cita: el conjunto de caracteres de cita.
- dec: el carácter utilizado en el archivo para los puntos decimales.
- relleno: lógico. Si es VERDADERO, en caso de que las filas tengan una longitud diferente, los campos en blanco se agregan implícitamente.
- comment.char: carácter: un vector de caracteres de longitud uno que contiene un solo carácter o una string vacía.
- … : Más argumentos por aprobar.
Ejemplo:
R
sdata <- read.csv("SampleData.csv", header = TRUE, sep = ",")
sdata
# views the data frame formed from the csv file
View(sdata)
Producción:
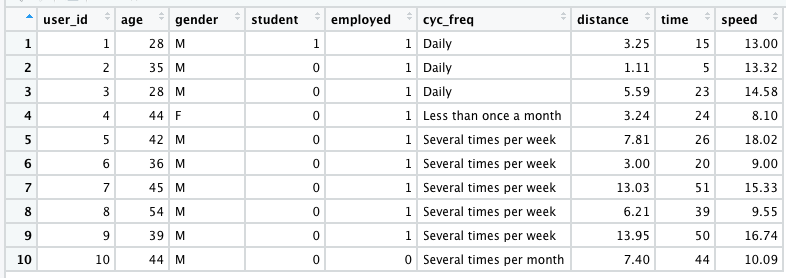
Ahora que hemos creado nuestro marco de datos, podemos realizar algunas operaciones en él. Los datos se leen de acuerdo con el uso del marco de datos. A continuación se presentan dos ejemplos que leen los datos según sus requisitos.
Ejemplo 1:
R
sdata <- read.csv( "SampleData.csv", header = TRUE, sep = ",") highspeed <- subset( sdata, sdata$speed == max(sdata$speed)) # views the subsetted value in # tabular form View(highspeed)
Producción:

Ejemplo 2:
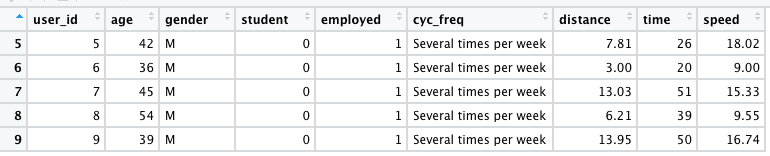
R
sdata <- read.csv( "SampleData.csv", header = TRUE, sep = ",") highfreq <- subset( sdata, sdata$cyc_freq == "Several times per week") # views the information, of the above # condition in tabular format View(highfreq)
Producción:
Publicación traducida automáticamente
Artículo escrito por shilpimazumdar7150 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA