En este artículo, vamos a discutir la parte introductoria de Apache Spark, la historia de Spark y por qué Spark es importante. Vamos a discutir uno por uno.
Según la definición de Databrick, “Apache Spark es un motor de análisis unificado ultrarrápido para big data y aprendizaje automático. Fue desarrollado originalmente en UC Berkeley en 2009”.
Databricks es uno de los principales contribuyentes de Spark, incluye yahoo! Intel, etc. Apache Spark es uno de los proyectos de código abierto más grandes para el procesamiento de datos. Es un motor de procesamiento de datos rápido y en memoria.

Historia de Spark:
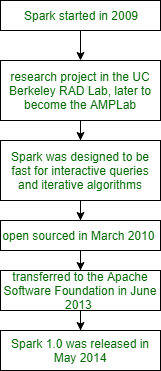
Spark comenzó en 2009 en el laboratorio de I+D de UC Berkeley, que ahora se conoce como AMPLab. Luego, en 2010, Spark se convirtió en código abierto bajo una licencia BSD. Luego, Spark se transfirió a ASF (Apache Software Foundation) en junio de 2013. Los investigadores de Spark trabajaron anteriormente en Hadoop map-reduce. En el laboratorio de investigación y desarrollo de UC Berkeley, observaron que era ineficiente para trabajos de computación iterativos e interactivos. En Spark para admitir el almacenamiento en memoria y la recuperación eficiente de fallas, Spark fue diseñado para ser rápido para consultas interactivas y algoritmos iterativos. En el diagrama a continuación, vamos a describir la historia de Spark. Echemos un vistazo.
Características de Chispa:
- Apache Spark puede usar para realizar el procesamiento por lotes.
- Apache Spark también se puede utilizar para realizar el procesamiento de secuencias. Para el procesamiento de transmisiones, usamos Apache Storm / S4.
- Se puede utilizar para el procesamiento interactivo. Anteriormente usábamos Apache Impala o Apache Tez para el procesamiento interactivo.
- Spark también es útil para realizar el procesamiento de gráficos. Neo4j / Apache Graph estaba usando para el procesamiento de gráficos.
- Spark puede procesar los datos en tiempo real y en modo por lotes.
Entonces, podemos decir que Spark es un poderoso motor de código abierto para el procesamiento de datos.
Referencias: Referencias
de Apache Spark
Publicación traducida automáticamente
Artículo escrito por Ashish_rana y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA