Veamos cómo obtener todas las filas en un Pandas DataFrame que contiene una substring dada con la ayuda de diferentes ejemplos.
Código #1: Verifique los valores PG en la columna Posición
# importing pandas
import pandas as pd
# Creating the dataframe with dict of lists
df = pd.DataFrame({'Name': ['Geeks', 'Peter', 'James', 'Jack', 'Lisa'],
'Team': ['Boston', 'Boston', 'Boston', 'Chele', 'Barse'],
'Position': ['PG', 'PG', 'UG', 'PG', 'UG'],
'Number': [3, 4, 7, 11, 5],
'Age': [33, 25, 34, 35, 28],
'Height': ['6-2', '6-4', '5-9', '6-1', '5-8'],
'Weight': [89, 79, 113, 78, 84],
'College': ['MIT', 'MIT', 'MIT', 'Stanford', 'Stanford'],
'Salary': [99999, 99994, 89999, 78889, 87779]},
index =['ind1', 'ind2', 'ind3', 'ind4', 'ind5'])
print(df, "\n")
print("Check PG values in Position column:\n")
df1 = df['Position'].str.contains("PG")
print(df1)
Producción: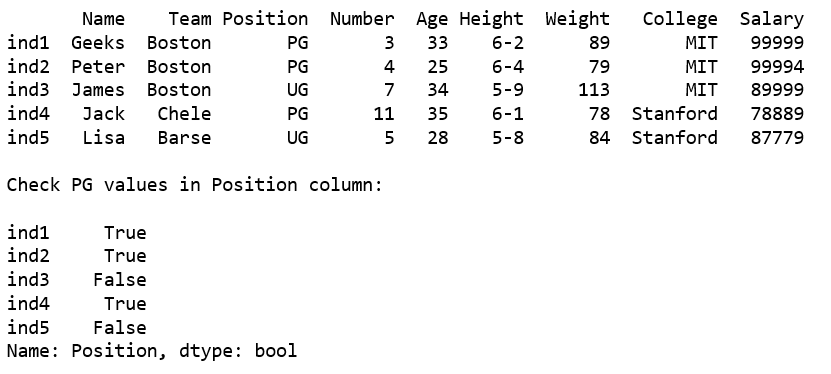
Pero este resultado no parece muy útil, ya que devuelve los valores booleanos con el índice. A ver si podemos hacer algo mejor.
Código #2: Obtener las filas que cumplen la condición
# importing pandas as pd
import pandas as pd
# Creating the dataframe with dict of lists
df = pd.DataFrame({'Name': ['Geeks', 'Peter', 'James', 'Jack', 'Lisa'],
'Team': ['Boston', 'Boston', 'Boston', 'Chele', 'Barse'],
'Position': ['PG', 'PG', 'UG', 'PG', 'UG'],
'Number': [3, 4, 7, 11, 5],
'Age': [33, 25, 34, 35, 28],
'Height': ['6-2', '6-4', '5-9', '6-1', '5-8'],
'Weight': [89, 79, 113, 78, 84],
'College': ['MIT', 'MIT', 'MIT', 'Stanford', 'Stanford'],
'Salary': [99999, 99994, 89999, 78889, 87779]},
index =['ind1', 'ind2', 'ind3', 'ind4', 'ind5'])
df1 = df[df['Position'].str.contains("PG")]
print(df1)
Producción: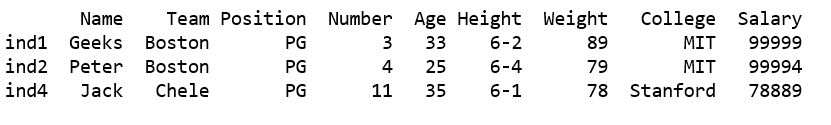
Código n.º 3: filtre todas las filas en las que Equipo contenga ‘Boston’ o Universidad contenga ‘MIT’.
# importing pandas
import pandas as pd
# Creating the dataframe with dict of lists
df = pd.DataFrame({'Name': ['Geeks', 'Peter', 'James', 'Jack', 'Lisa'],
'Team': ['Boston', 'Boston', 'Boston', 'Chele', 'Barse'],
'Position': ['PG', 'PG', 'UG', 'PG', 'UG'],
'Number': [3, 4, 7, 11, 5],
'Age': [33, 25, 34, 35, 28],
'Height': ['6-2', '6-4', '5-9', '6-1', '5-8'],
'Weight': [89, 79, 113, 78, 84],
'College': ['MIT', 'MIT', 'MIT', 'Stanford', 'Stanford'],
'Salary': [99999, 99994, 89999, 78889, 87779]},
index =['ind1', 'ind2', 'ind3', 'ind4', 'ind5'])
df1 = df[df['Team'].str.contains("Boston") | df['College'].str.contains('MIT')]
print(df1)
Salida: 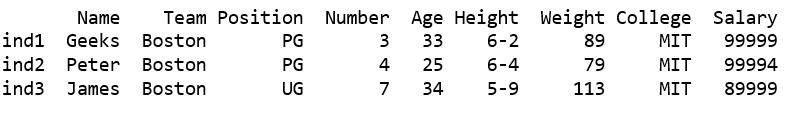
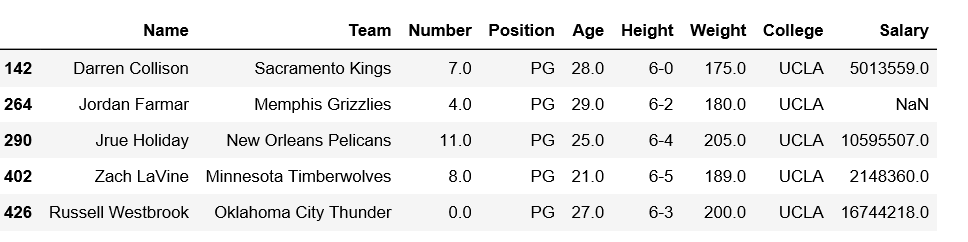
Código n.º 4: las filas de filtro que verifican el nombre del equipo contienen ‘Boston y la posición debe ser PG.
# importing pandas module
import pandas as pd
# making data frame
df = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
df1 = df[df['Team'].str.contains('Boston') & df['Position'].str.contains('PG')]
df1
Producción: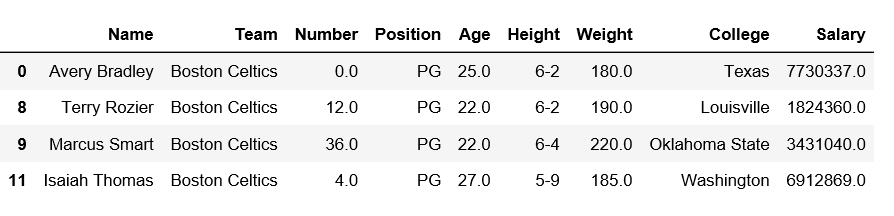
Código n.° 5: las filas de filtro que verifican que la posición contiene PG y la universidad debe contener como UC.
# importing pandas module
import pandas as pd
# making data frame
df = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
df1 = df[df['Position'].str.contains("PG") & df['College'].str.contains('UC')]
df1
Producción: