En este artículo, analicemos cómo filtrar el marco de datos de pandas con múltiples condiciones. Hay posibilidades de filtrar datos del marco de datos de Pandas con múltiples condiciones durante todo el desarrollo del software. El motivo es que el marco de datos puede tener varias columnas y varias filas. La visualización selectiva de columnas con filas limitadas es siempre la vista esperada de los usuarios. Para cumplir con las expectativas del usuario y también ayudar en escenarios de aprendizaje profundo de máquinas, es muy necesario filtrar el marco de datos de Pandas con múltiples condiciones.
Veamos las diferentes formas de hacer lo mismo.
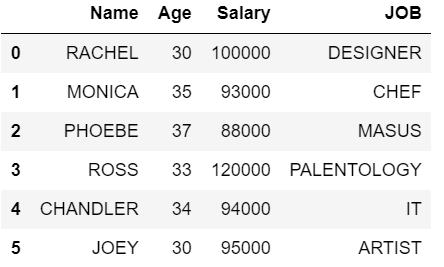
Creación de un marco de datos de muestra para continuar
Python3
# import module
import pandas as pd
# assign data
dataFrame = pd.DataFrame({'Name': [' RACHEL ', ' MONICA ', ' PHOEBE ',
' ROSS ', 'CHANDLER', ' JOEY '],
'Age': [30, 35, 37, 33, 34, 30],
'Salary': [100000, 93000, 88000, 120000, 94000, 95000],
'JOB': ['DESIGNER', 'CHEF', 'MASUS', 'PALENTOLOGY',
'IT', 'ARTIST']})
# display dataframe
display(dataFrame)
Producción:
Método 1: Usando loc
Aquí obtendremos todas las filas que tienen Salario mayor o igual a 100000 y Edad < 40 y su TRABAJO comienza con ‘D’ del marco de datos. Imprima los detalles con Nombre y su TRABAJO. Para el requisito anterior, podemos lograrlo usando loc . Se utiliza para acceder a una o más filas y columnas por etiqueta(s) o por una array booleana. loc funciona con etiquetas de columna e índices.
Python3
# import module
import pandas as pd
# assign data
dataFrame = pd.DataFrame({'Name': [' RACHEL ', ' MONICA ', ' PHOEBE ',
' ROSS ', 'CHANDLER', ' JOEY '],
'Age': [30, 35, 37, 33, 34, 30],
'Salary': [100000, 93000, 88000, 120000, 94000, 95000],
'JOB': ['DESIGNER', 'CHEF', 'MASUS', 'PALENTOLOGY',
'IT', 'ARTIST']})
# filter dataframe
display(dataFrame.loc[(dataFrame['Salary']>=100000) & (dataFrame['Age']< 40) & (dataFrame['JOB'].str.startswith('D')),
['Name','JOB']])
Producción:
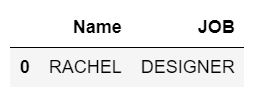
La salida se resuelve para las condiciones dadas y, finalmente, mostraremos solo 2 columnas, a saber, Nombre y TRABAJO.
Método 2: Usando NumPy
Aquí obtendrá todas las filas que tengan Salario mayor o igual a 100000 y Edad < 40 y su TRABAJO comienza con ‘D’ del marco de datos. Necesitamos usar NumPy.
Python3
# import module
import pandas as pd
import numpy as np
# assign data
dataFrame = pd.DataFrame({'Name': [' RACHEL ', ' MONICA ', ' PHOEBE ',
' ROSS ', 'CHANDLER', ' JOEY '],
'Age': [30, 35, 37, 33, 34, 30],
'Salary': [100000, 93000, 88000, 120000, 94000, 95000],
'JOB': ['DESIGNER', 'CHEF', 'MASUS', 'PALENTOLOGY',
'IT', 'ARTIST']})
# filter dataframe
filtered_values = np.where((dataFrame['Salary']>=100000) & (dataFrame['Age']< 40) & (dataFrame['JOB'].str.startswith('D')))
print(filtered_values)
display(dataFrame.loc[filtered_values])
Producción:
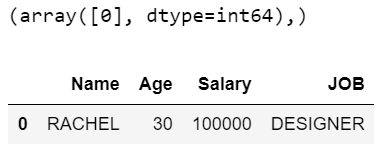
En el ejemplo anterior, print(filtered_values) dará la salida como (array([0], dtype=int64)), lo que indica que la primera fila con valor de índice 0 será la salida. Después de eso, la salida tendrá 1 fila con todas las columnas y se recuperará según las condiciones dadas.
Método 3: Uso de Query (eval y query solo funcionan con columnas)
En este enfoque, obtenemos todas las filas que tienen Salario menor o igual a 100000 y Edad < 40, y su TRABAJO comienza con ‘C’ del marco de datos. Solo consulta las columnas de un DataFrame con una o más expresiones booleanas y, si son múltiples, tiene & condición en el medio.
Python3
# import module
import pandas as pd
# assign data
dataFrame = pd.DataFrame({'Name': [' RACHEL ', ' MONICA ', ' PHOEBE ',
' ROSS ', 'CHANDLER', ' JOEY '],
'Age': [30, 35, 37, 33, 34, 30],
'Salary': [100000, 93000, 88000, 120000, 94000, 95000],
'JOB': ['DESIGNER', 'CHEF', 'MASUS', 'PALENTOLOGY',
'IT', 'ARTIST']})
# filter dataframe
display(dataFrame.query('Salary <= 100000 & Age < 40 & JOB.str.startswith("C").values'))
Producción:
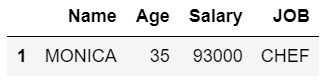
Método 4: pandas Boolean indexando múltiples condiciones de manera estándar («La indexación booleana» funciona solo con valores en una columna)
En este enfoque, obtenemos todas las filas que tienen Salario menor o igual a 100000 y Edad < 40 y su TRABAJO comienza con ‘P’ del marco de datos. Para seleccionar el subconjunto de datos utilizando los valores en el marco de datos y aplicando condiciones booleanas, debemos seguir estas formas
Python3
# import module
import pandas as pd
# assign data
dataFrame = pd.DataFrame({'Name': [' RACHEL ', ' MONICA ', ' PHOEBE ',
' ROSS ', 'CHANDLER', ' JOEY '],
'Age': [30, 35, 37, 33, 34, 30],
'Salary': [100000, 93000, 88000, 120000, 94000, 95000],
'JOB': ['DESIGNER', 'CHEF', 'MASUS', 'PALENTOLOGY',
'IT', 'ARTIST']})
# filter dataframe
display(dataFrame[(dataFrame['Salary']>=100000) & (dataFrame['Age']<40) & dataFrame['JOB'].str.startswith('P')][['Name','Age','Salary']])
Producción:

Mencionamos una lista de columnas que deben recuperarse junto con las condiciones booleanas y, dado que muchas condiciones, tiene ‘&’.
Método 5: evaluar múltiples condiciones («eval» y «query» funcionan solo con columnas)
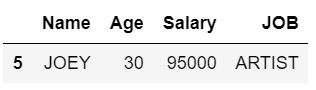
Aquí, obtenemos todas las filas que tienen Salario menor o igual a 100000 y Edad < 40 y su TRABAJO comienza con ‘A’ del marco de datos.
Python3
# import module
import pandas as pd
# assign data
dataFrame = pd.DataFrame({'Name': [' RACHEL ', ' MONICA ', ' PHOEBE ',
' ROSS ', 'CHANDLER', ' JOEY '],
'Age': [30, 35, 37, 33, 34, 30],
'Salary': [100000, 93000, 88000, 120000, 94000, 95000],
'JOB': ['DESIGNER', 'CHEF', 'MASUS', 'PALENTOLOGY',
'IT', 'ARTIST']})
# filter dataframe
display(dataFrame[dataFrame.eval("Salary <=100000 & (Age <40) & JOB.str.startswith('A').values")])
Producción:
Los marcos de datos son un concepto muy esencial en Python y se requiere la filtración de datos que se puede realizar en función de varias condiciones. Se pueden conseguir de cualquiera de las formas anteriores. Puntos a tener en cuenta:
- loc funciona con etiquetas de columna e índices.
- eval y query solo funcionan con columnas.
- La indexación booleana funciona solo con valores en una columna.
Publicación traducida automáticamente
Artículo escrito por priyarajtt y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA