Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
La función Pandas dataframe.nunique()devuelve series con un número de observaciones distintas sobre el eje solicitado. Si establecemos el valor del eje en 0, entonces encuentra el número total de observaciones únicas sobre el eje del índice. Si establecemos el valor del eje en 1, entonces encuentra el número total de observaciones únicas sobre el eje de la columna. También proporciona la función para excluir los NaNvalores del recuento de números únicos.
Sintaxis: DataFrame.nunique(axis=0, dropna=True)
Parámetros:
eje: {0 o ‘índice’, 1 o ‘columnas’}, predeterminado 0
dropna: no incluya NaN en los recuentos.Devoluciones : nunique : Serie
Ejemplo #1: Use nunique()la función para encontrar el número de valores únicos sobre el eje de la columna.
# importing pandas as pd
import pandas as pd
# Creating the first dataframe
df = pd.DataFrame({"A":[14, 4, 5, 4, 1],
"B":[5, 2, 54, 3, 2],
"C":[20, 20, 7, 3, 8],
"D":[14, 3, 6, 2, 6]})
# Print the dataframe
df
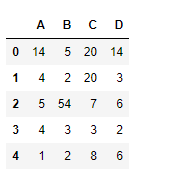
Usemos la dataframe.nunique()función para encontrar los valores únicos en el eje de la columna.
# find unique values df.nunique(axis = 1)
Salida: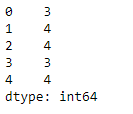
Como podemos ver en la salida, la función imprime el número total. de valores únicos en cada fila.
Ejemplo #2: use nunique()la función para encontrar el número de valores únicos sobre el eje de índice en un marco de datos. El marco de datos contiene NaNvalores.
# importing pandas as pd
import pandas as pd
# Creating the first dataframe
df = pd.DataFrame({"A":["Sandy", "alex", "brook", "kelly", np.nan],
"B":[np.nan, "olivia", "olivia", "", "amanda"],
"C":[20 + 5j, 20 + 5j, 7, None, 8],
"D":[14.8, 3, None, 6, 6]})
# apply the nunique() function
df.nunique(axis = 0, dropna = True)
Salida:
la función trata la string vacía como un valor único en la columna 2.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA