Twitter es una de las plataformas de redes sociales más populares. La API de Twitter proporciona las herramientas que necesita para contribuir, participar y analizar la conversación que tiene lugar en Twitter, que encuentra muchas aplicaciones en campos como el análisis de datos y la inteligencia artificial. Este artículo se enfoca en cómo extraer tweets que tienen un Hashtag particular a partir de una fecha determinada.
Requisitos:
- Tweepy es un paquete de Python diseñado para acceder fácilmente a la API de Twitter. Casi toda la funcionalidad proporcionada por la API de Twitter se puede utilizar a través de Tweepy . Para instalar este tipo, escriba el siguiente comando en la terminal.
pip install Tweepy
- Pandas es un marco muy poderoso para el análisis de datos en python. Se basa en Numpy Package y su estructura de datos clave es un DataFrame donde se pueden manipular datos tabulares. Para instalar este tipo, escriba el siguiente comando en la terminal.
pip install pandas
requisitos previos:
- Cree una cuenta de desarrollador de Twitter y obtenga su clave secreta de consumidor y token de acceso
- Instale el módulo Tweepy y Pandas en su sistema ejecutando este comando en el símbolo del sistema
Enfoque paso a paso:
- Importe los módulos requeridos.
- Cree una función explícita para mostrar datos de tweets.
- Cree otra función para raspar datos con respecto a un Hashtag dado usando el módulo tweepy .
- En el Código del controlador, asigne las credenciales de la cuenta de desarrollador de Twitter junto con el Hashtag, la fecha inicial y la cantidad de tweets.
- Finalmente, llame a la función para raspar los datos con Hashtag, fecha inicial y número de tweets como argumento.
A continuación se muestra el programa completo basado en el enfoque anterior:
Python
# Python Script to Extract tweets of a
# particular Hashtag using Tweepy and Pandas
# import modules
import pandas as pd
import tweepy
# function to display data of each tweet
def printtweetdata(n, ith_tweet):
print()
print(f"Tweet {n}:")
print(f"Username:{ith_tweet[0]}")
print(f"Description:{ith_tweet[1]}")
print(f"Location:{ith_tweet[2]}")
print(f"Following Count:{ith_tweet[3]}")
print(f"Follower Count:{ith_tweet[4]}")
print(f"Total Tweets:{ith_tweet[5]}")
print(f"Retweet Count:{ith_tweet[6]}")
print(f"Tweet Text:{ith_tweet[7]}")
print(f"Hashtags Used:{ith_tweet[8]}")
# function to perform data extraction
def scrape(words, date_since, numtweet):
# Creating DataFrame using pandas
db = pd.DataFrame(columns=['username',
'description',
'location',
'following',
'followers',
'totaltweets',
'retweetcount',
'text',
'hashtags'])
# We are using .Cursor() to search
# through twitter for the required tweets.
# The number of tweets can be
# restricted using .items(number of tweets)
tweets = tweepy.Cursor(api.search_tweets,
words, lang="en",
since_id=date_since,
tweet_mode='extended').items(numtweet)
# .Cursor() returns an iterable object. Each item in
# the iterator has various attributes
# that you can access to
# get information about each tweet
list_tweets = [tweet for tweet in tweets]
# Counter to maintain Tweet Count
i = 1
# we will iterate over each tweet in the
# list for extracting information about each tweet
for tweet in list_tweets:
username = tweet.user.screen_name
description = tweet.user.description
location = tweet.user.location
following = tweet.user.friends_count
followers = tweet.user.followers_count
totaltweets = tweet.user.statuses_count
retweetcount = tweet.retweet_count
hashtags = tweet.entities['hashtags']
# Retweets can be distinguished by
# a retweeted_status attribute,
# in case it is an invalid reference,
# except block will be executed
try:
text = tweet.retweeted_status.full_text
except AttributeError:
text = tweet.full_text
hashtext = list()
for j in range(0, len(hashtags)):
hashtext.append(hashtags[j]['text'])
# Here we are appending all the
# extracted information in the DataFrame
ith_tweet = [username, description,
location, following,
followers, totaltweets,
retweetcount, text, hashtext]
db.loc[len(db)] = ith_tweet
# Function call to print tweet data on screen
printtweetdata(i, ith_tweet)
i = i+1
filename = 'scraped_tweets.csv'
# we will save our database as a CSV file.
db.to_csv(filename)
if __name__ == '__main__':
# Enter your own credentials obtained
# from your developer account
consumer_key = "XXXXXXXXXXXXXXXXXXXXX"
consumer_secret = "XXXXXXXXXXXXXXXXXXXXX"
access_key = "XXXXXXXXXXXXXXXXXXXXX"
access_secret = "XXXXXXXXXXXXXXXXXXXXX"
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_key, access_secret)
api = tweepy.API(auth)
# Enter Hashtag and initial date
print("Enter Twitter HashTag to search for")
words = input()
print("Enter Date since The Tweets are required in yyyy-mm--dd")
date_since = input()
# number of tweets you want to extract in one run
numtweet = 100
scrape(words, date_since, numtweet)
print('Scraping has completed!')
Producción:
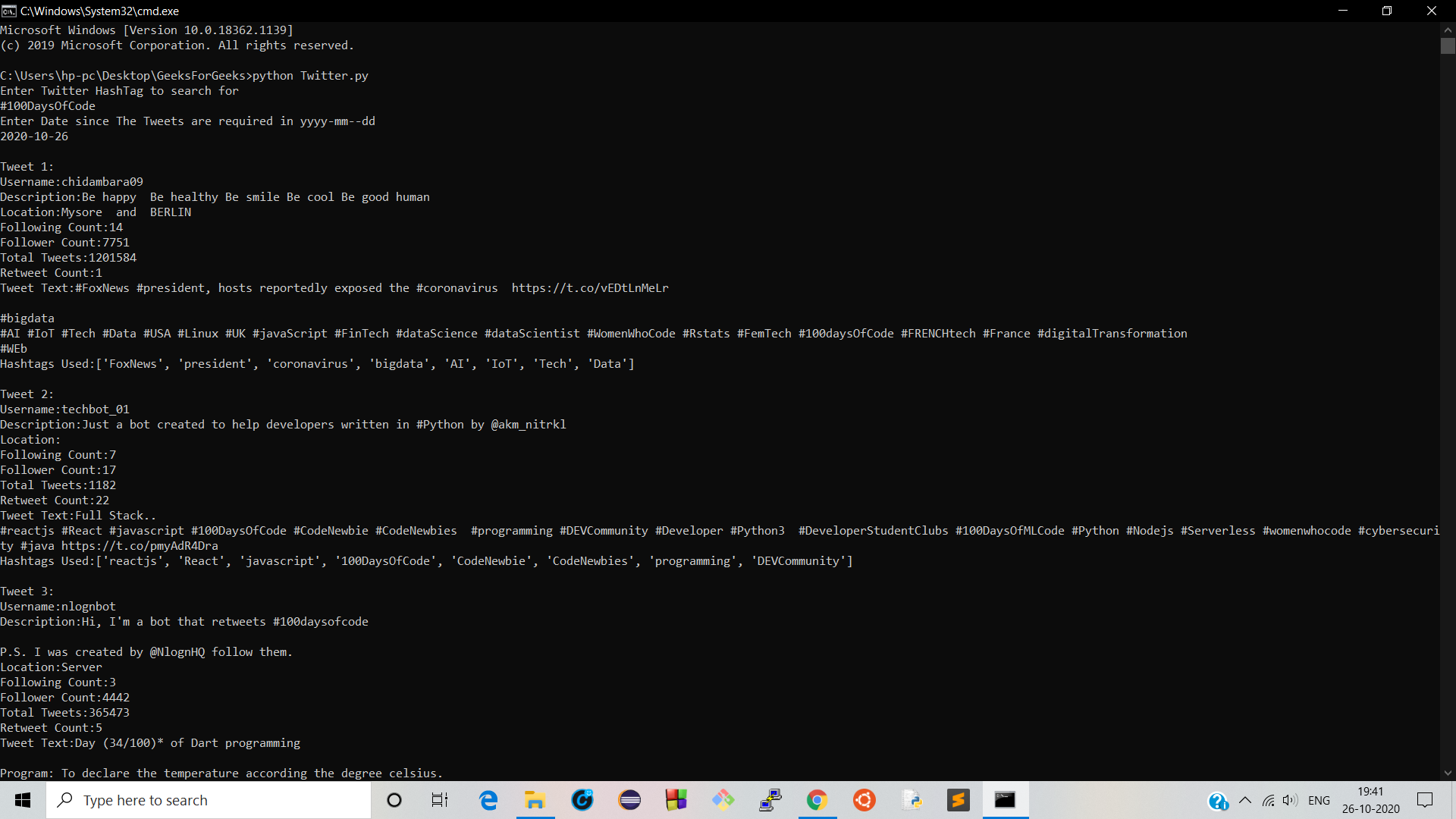
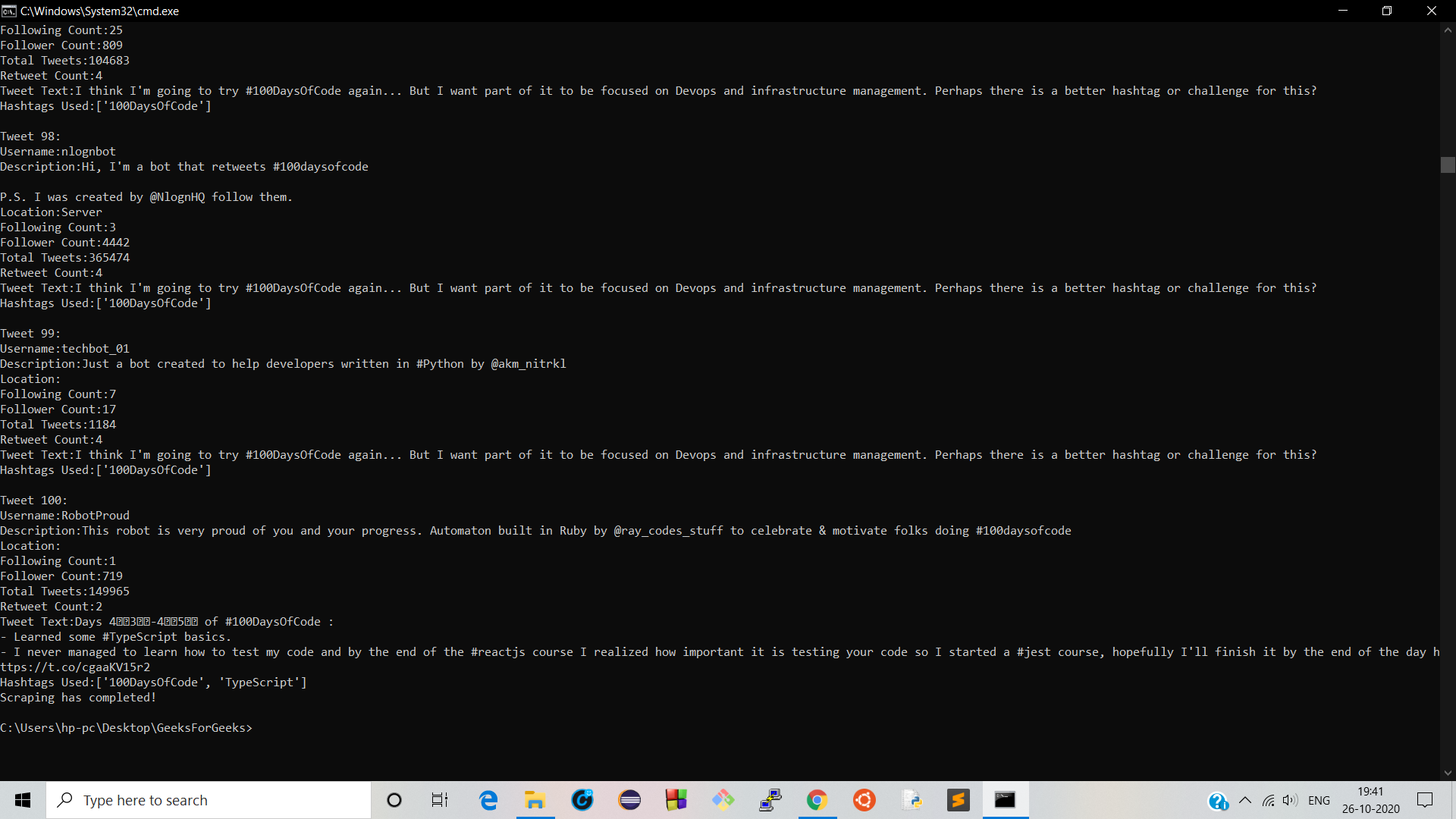
Manifestación:
Publicación traducida automáticamente
Artículo escrito por sanjanatalreja28 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA