El suavizado exponencial es una técnica para suavizar datos de series de tiempo utilizando una función de ventana exponencial. Es un método de la regla del pulgar. A diferencia del promedio móvil simple, con el tiempo las funciones exponenciales asignan pesos exponencialmente decrecientes. Aquí, los pesos mayores se asignan a los valores u observaciones recientes, mientras que los pesos menores se asignan a los valores u observaciones más antiguos. Entre muchas funciones de ventana, en el procesamiento de señales, la función de suavizado exponencial generalmente se aplica para suavizar datos donde actúa como un filtro de paso bajo para eliminar el ruido de alta frecuencia. Este método es bastante intuitivo, por lo general se puede aplicar en un rango amplio o enorme de series de tiempo y también es computacionalmente eficiente. En este artículo, analicemos el suavizado exponencial en la programación R.. Existen muchos tipos de técnicas de suavizado exponencial basadas en las tendencias y la estacionalidad, que son las siguientes:
- Suavizado exponencial simple
- método de holt
- Método estacional de Holt-Winter
- Método de tendencia amortiguada
Antes de continuar, es necesario ver los requisitos de replicación.
Requisitos de replicación del análisis en R
En R, los requisitos previos de este análisis serán la instalación de los paquetes necesarios. Necesitamos instalar los siguientes dos paquetes usando el comando install.packages() desde la consola R:
- fpp2 (con el que se cargará automáticamente el paquete de pronóstico)
- ordenado
Bajo el paquete de pronóstico, obtendremos muchas funciones que mejorarán y ayudarán en nuestro pronóstico. En este análisis, trabajaremos con dos conjuntos de datos bajo el paquete fpp2 . Estos son el conjunto de datos «goog» y el conjunto de datos «qcement» . Ahora necesitamos cargar los paquetes requeridos en nuestro R Script usando la función library() . Después de cargar ambos paquetes, prepararemos nuestro conjunto de datos. Para ambos conjuntos de datos, dividiremos los datos en dos conjuntos: conjunto de entrenamiento y conjunto de prueba.
R
# loading the required packages library(tidyverse) library(fpp2) # create training and testing set # of the Google stock data goog.train <- window(goog, end = 900) goog.test <- window(goog, start = 901) # create training and testing # set of the AirPassengers data qcement.train <- window(qcement, end = c(2012, 4)) qcement.test <- window(qcement, start = c(2013, 1))
Ahora estamos listos para continuar con nuestro análisis.
Suavizado exponencial simple (SES)
La técnica de suavizado exponencial simple se utiliza para datos que no tienen tendencia o patrón estacional. El SES es el más simple entre todas las técnicas de suavizado exponencial. Sabemos que en cualquier tipo de suavizado exponencial ponderamos más los valores u observaciones recientes que los valores u observaciones antiguos. El peso de todos y cada uno de los parámetros siempre está determinado por un parámetro de suavizado o alfa. El valor de alfa está entre 0 y 1. En la práctica, si alfa está entre 0,1 y 0,2, SES funcionará bastante bien. Cuando alfa está más cerca de 0, se considera un aprendizaje lento, ya que el algoritmo le da más peso a los datos históricos. Si el valor de alfa está más cerca de 1, se denomina aprendizaje rápido, ya que el algoritmo otorga más peso a las observaciones o datos recientes. Por lo tanto, podemos decir que los cambios recientes en los datos dejarán un mayor impacto en el pronóstico.
En R, para realizar el análisis de suavizado exponencial simple, necesitamos usar la función ses() . Para entender la técnica vamos a ver algunos ejemplos. Usaremos el conjunto de datos de goog para SES.
Ejemplo 1:
En este ejemplo, estamos configurando alfa = 0.2 y también los pasos hacia adelante del pronóstico h = 100 para nuestro modelo inicial.
R
# SES in R # loading the required packages library(tidyverse) library(fpp2) # create training and validation # of the Google stock data goog.train <- window(goog, end = 900) goog.test <- window(goog, start = 901) # Performing SES on the # Google stock data ses.goog <- ses(goog.train, alpha = .2, h = 100) autoplot(ses.goog)
Producción:
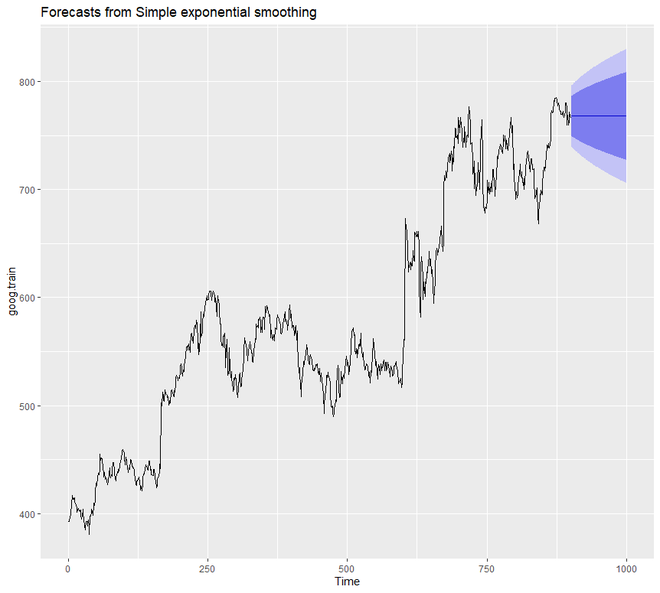
En el gráfico de salida anterior, podemos notar que nuestro modelo de pronóstico proyecta una estimación plana hacia el futuro. Por lo tanto, podemos decir que a partir de los datos no está capturando la tendencia actual. Por lo tanto, para corregir esto, usaremos la función diff() para eliminar la tendencia de los datos.
Ejemplo 2:
R
# SES in R # loading the required packages library(tidyverse) library(fpp2) # create training and validation # of the Google stock data goog.train <- window(goog, end = 900) goog.test <- window(goog, start = 901) # removing the trend goog.dif <- diff(goog.train) autoplot(goog.dif) # reapplying SES on the filtered data ses.goog.dif <- ses(goog.dif, alpha = .2, h = 100) autoplot(ses.goog.dif)
Producción:
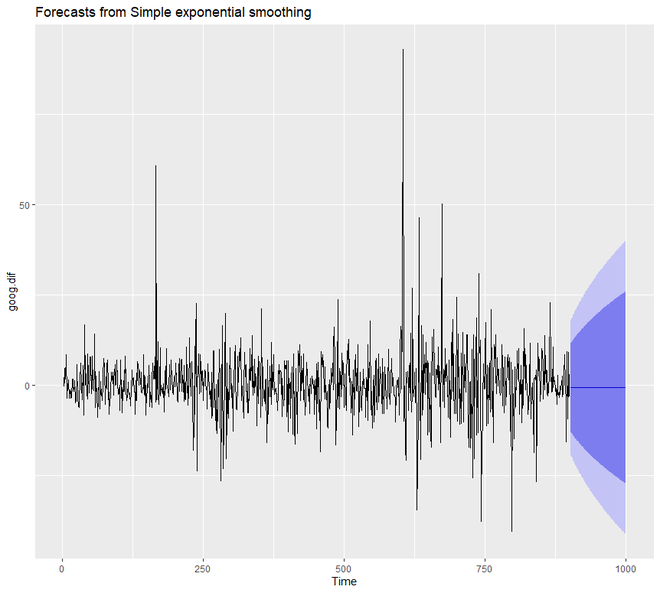
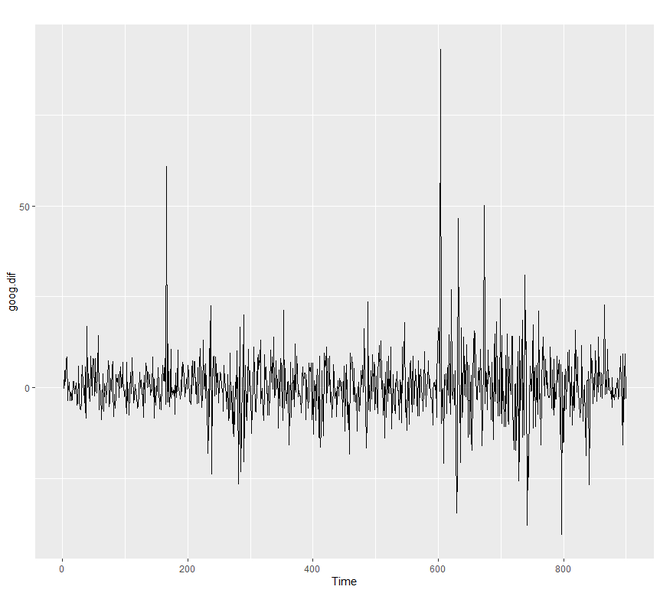
Para comprender el rendimiento de nuestro modelo, debemos comparar nuestro pronóstico con nuestro conjunto de datos de validación o prueba. Dado que nuestro conjunto de datos de tren fue diferenciado, también debemos formar o crear una validación diferenciada o un conjunto de prueba.
Ejemplo 3:
Aquí vamos a crear un conjunto de validación diferenciado y luego compararemos nuestro pronóstico con el conjunto de validación. Aquí estamos configurando el valor de alfa de 0.01-0.99 usando el bucle. Estamos tratando de entender qué nivel minimizará la prueba RMSE. Veremos que 0.05 será el que más se minimice.
R
# SES in R
# loading the required packages
library(tidyverse)
library(fpp2)
# create training and validation
# of the Google stock data
goog.train <- window(goog,
end = 900)
goog.test <- window(goog,
start = 901)
# removing trend from test set
goog.dif.test <- diff(goog.test)
accuracy(ses.goog.dif, goog.dif.test)
# comparing our model
alpha <- seq(.01, .99, by = .01)
RMSE <- NA
for(i in seq_along(alpha)) {
fit <- ses(goog.dif, alpha = alpha[i],
h = 100)
RMSE[i] <- accuracy(fit,
goog.dif.test)[2,2]
}
# convert to a data frame and
# identify min alpha value
alpha.fit <- data_frame(alpha, RMSE)
alpha.min <- filter(alpha.fit,
RMSE == min(RMSE))
# plot RMSE vs. alpha
ggplot(alpha.fit, aes(alpha, RMSE)) +
geom_line() +
geom_point(data = alpha.min,
aes(alpha, RMSE),
size = 2, color = "red")
Producción:
ME RMSE MAE MPE MAPE MASE ACF1 Theil's U Training set -0.01368221 9.317223 6.398819 99.97907 253.7069 0.7572009 -0.05440377 NA Test set 0.97219517 8.141450 6.117483 109.93320 177.9684 0.7239091 0.12278141 0.9900678
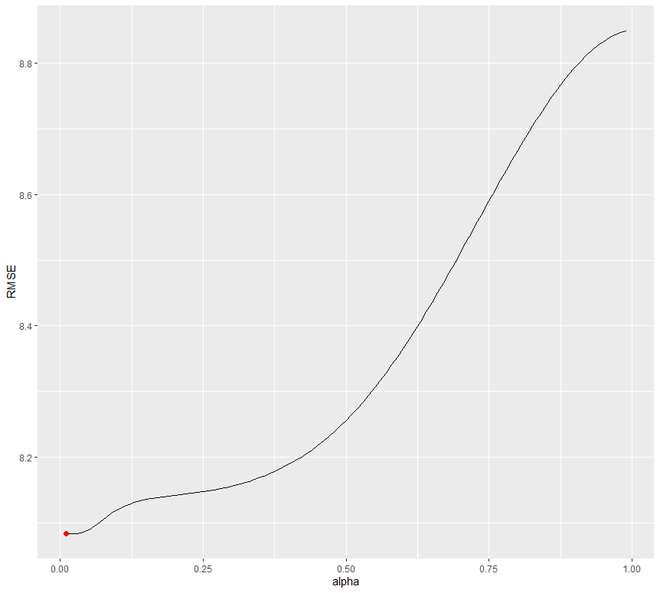
Ahora, intentaremos reajustar nuestro modelo de pronóstico para SES con alfa = 0.05. Notaremos la diferencia significativa entre alfa 0.02 y alfa=0.05.
Ejemplo 4:
R
# SES in R
# loading packages
library(tidyverse)
library(fpp2)
# create training and validation
# of the Google stock data
goog.train <- window(goog,
end = 900)
goog.test <- window(goog,
start = 901)
# removing trend
goog.dif <- diff(goog.train)
# refit model with alpha = .05
ses.goog.opt <- ses(goog.dif,
alpha = .05,
h = 100)
# performance eval
accuracy(ses.goog.opt, goog.dif.test)
# plotting results
p1 <- autoplot(ses.goog.opt) +
theme(legend.position = "bottom")
p2 <- autoplot(goog.dif.test) +
autolayer(ses.goog.opt, alpha = .5) +
ggtitle("Predicted vs. actuals for
the test data set")
gridExtra::grid.arrange(p1, p2,
nrow = 1)
Producción:
> accuracy(ses.goog.opt, goog.dif.test)
ME RMSE MAE MPE MAPE MASE ACF1 Theil's U
Training set -0.01188991 8.939340 6.030873 109.97354 155.7700 0.7136602 0.01387261 NA
Test set 0.30483955 8.088941 6.028383 97.77722 112.2178 0.7133655 0.12278141 0.9998811
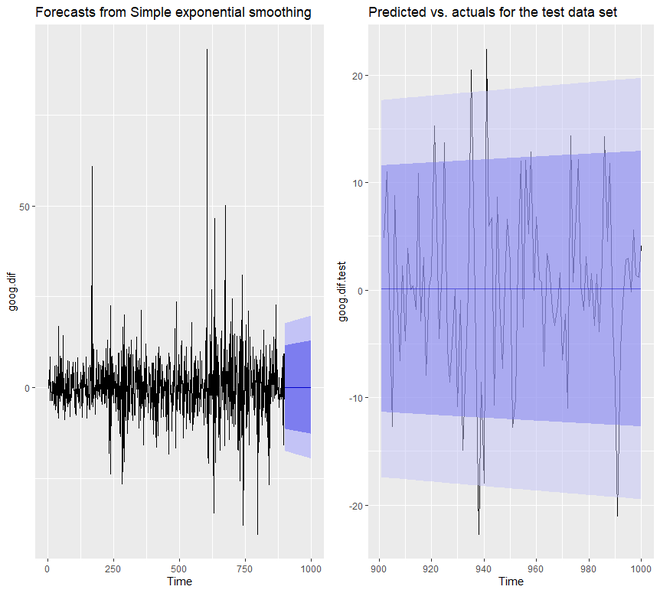
Veremos que ahora el intervalo de confianza predicho de nuestro modelo es mucho más estrecho.
Método de Holt
Hemos visto que en SES tuvimos que eliminar las tendencias a largo plazo para mejorar el modelo. Pero en el método de Holt , podemos aplicar suavizado exponencial mientras capturamos tendencias en los datos. Esta es una técnica que trabaja con datos que tienen tendencia pero no estacionalidad. Para hacer predicciones sobre los datos, el método de Holt utiliza dos parámetros de suavizado , alfa y beta , que corresponden a los componentes de nivel y los componentes de tendencia.
En R, para aplicar el Método de Holt vamos a utilizar la función holt() . De nuevo entenderemos el principio de funcionamiento de esta técnica utilizando algunos ejemplos. Vamos a usar el conjunto de datos de goog nuevamente.
Ejemplo 1:
R
# holt's method in R # loading packages library(tidyverse) library(fpp2) # create training and validation # of the Google stock data goog.train <- window(goog, end = 900) goog.test <- window(goog, start = 901) # applying holt's method on # Google stock Data holt.goog <- holt(goog.train, h = 100) autoplot(holt.goog)
Producción:
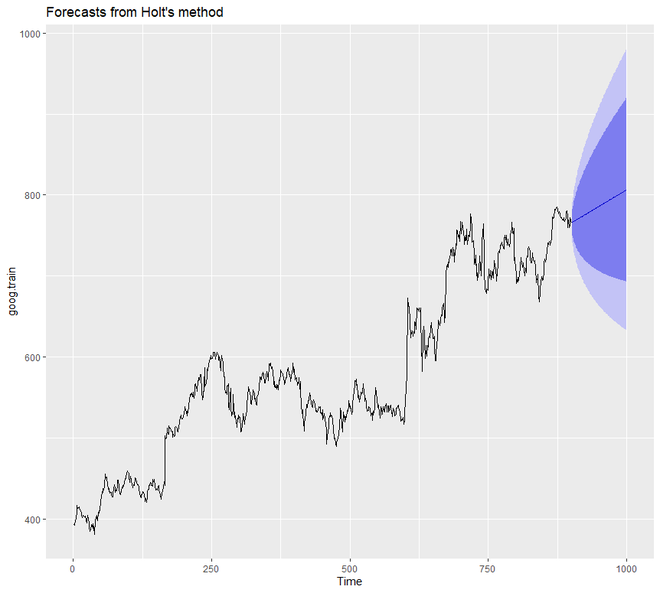
En el ejemplo anterior, no configuramos el valor de alfa y beta manualmente. Pero podemos hacerlo. Sin embargo, si mencionamos algún valor para alfa y beta, automáticamente la función holt() identificará el valor óptimo. En este caso, si el valor de alfa es 0,9967, indica un aprendizaje rápido y si el valor de beta es 0,0001, indica un aprendizaje lento de la tendencia.
Ejemplo 2:
En este ejemplo, vamos a establecer el valor de alfa y beta. Además, vamos a ver la precisión del modelo.
R
# holt's method in R # loading the packages library(tidyverse) library(fpp2) # create training and validation # of the Google stock data goog.train <- window(goog, end = 900) goog.test <- window(goog, start = 901) # holt's method holt.goog$model # accuracy of the model accuracy(holt.goog, goog.test)
Producción:
Holt's method
Call:
holt(y = goog.train, h = 100)
Smoothing parameters:
alpha = 0.9999
beta = 1e-04
Initial states:
l = 401.1276
b = 0.4091
sigma: 8.8149
AIC AICc BIC
10045.74 10045.81 10069.75
> accuracy(holt.goog, goog.test)
ME RMSE MAE MPE MAPE MASE ACF1 Theil's U
Training set -0.003332796 8.795267 5.821057 -0.01211821 1.000720 1.002452 0.03100836 NA
Test set 0.545744415 16.328680 12.876836 0.03013427 1.646261 2.217538 0.87733298 2.024518
El valor óptimo, es decir, beta = 0,0001, se utiliza para eliminar errores del conjunto de entrenamiento. Podemos ajustar nuestra versión beta a este valor óptimo.
Ejemplo 3:
Tratemos de encontrar el valor óptimo de beta a través de un ciclo que va desde 0.0001 a 0.5 que minimizará la prueba RMSE. Veremos que 0.0601 será el valor de beta que sumergirá RMSE.
R
# holts method in R
# loading the package
library(tidyverse)
library(fpp2)
# create training and validation
# of the Google stock data
goog.train <- window(goog,
end = 900)
goog.test <- window(goog,
start = 901)
# identify optimal alpha parameter
beta <- seq(.0001, .5, by = .001)
RMSE <- NA
for(i in seq_along(beta)) {
fit <- holt(goog.train,
beta = beta[i],
h = 100)
RMSE[i] <- accuracy(fit,
goog.test)[2,2]
}
# convert to a data frame and
# identify min alpha value
beta.fit <- data_frame(beta, RMSE)
beta.min <- filter(beta.fit,
RMSE == min(RMSE))
# plot RMSE vs. alpha
ggplot(beta.fit, aes(beta, RMSE)) +
geom_line() +
geom_point(data = beta.min,
aes(beta, RMSE),
size = 2, color = "red")
Producción:
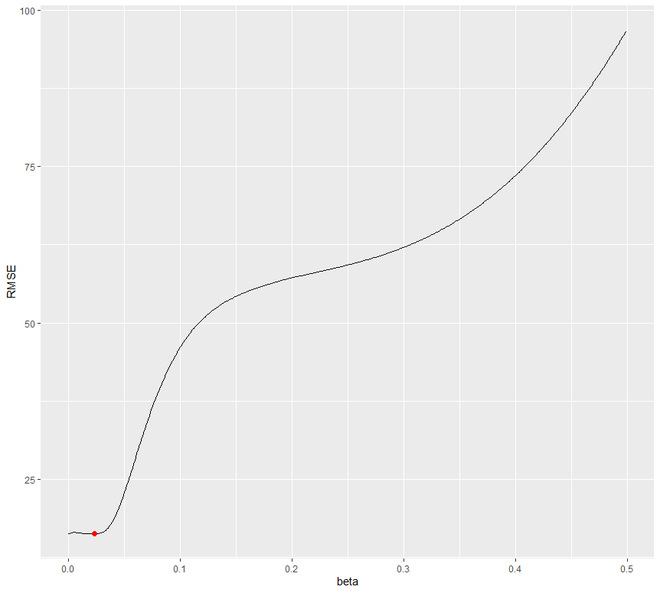
Ahora ajustemos el modelo con el valor óptimo obtenido de beta.
Ejemplo 4:
Vamos a establecer el valor óptimo de beta y también compararemos la precisión predictiva con nuestro modelo original.
R
# loading the package
library(tidyverse)
library(fpp2)
# create training and validation
# of the Google stock data
goog.train <- window(goog,
end = 900)
goog.test <- window(goog,
start = 901)
holt.goog <- holt(goog.train,
h = 100)
# new model with optimal beta
holt.goog.opt <- holt(goog.train,
h = 100,
beta = 0.0601)
# accuracy of first model
accuracy(holt.goog, goog.test)
# accuracy of new optimal model
accuracy(holt.goog.opt, goog.test)
p1 <- autoplot(holt.goog) +
ggtitle("Original Holt's Model") +
coord_cartesian(ylim = c(400, 1000))
p2 <- autoplot(holt.goog.opt) +
ggtitle("Optimal Holt's Model") +
coord_cartesian(ylim = c(400, 1000))
gridExtra::grid.arrange(p1, p2,
nrow = 1)
Producción:
> accuracy(holt.goog, goog.test)
ME RMSE MAE MPE MAPE MASE ACF1 Theil's U
Training set -0.003332796 8.795267 5.821057 -0.01211821 1.000720 1.002452 0.03100836 NA
Test set 0.545744415 16.328680 12.876836 0.03013427 1.646261 2.217538 0.87733298 2.024518
> accuracy(holt.goog.opt, goog.test)
ME RMSE MAE MPE MAPE MASE ACF1 Theil's U
Training set -0.01493114 8.960214 6.058869 -0.005524151 1.039572 1.043406 0.009696325 NA
Test set 21.41138275 28.549029 23.841097 2.665066997 2.988712 4.105709 0.895371665 3.435763
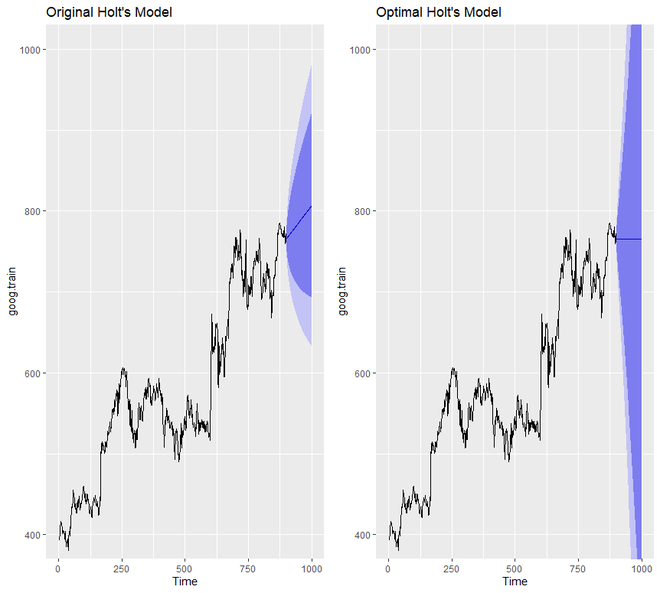
Notaremos que el modelo óptimo comparado con el modelo original es mucho más conservador. Además, el intervalo de confianza del modelo óptimo es mucho más extremo.
Método estacional de Holt-Winter
El método estacional de Holt-Winter se utiliza para datos con patrones y tendencias estacionales. Este método se puede implementar mediante el uso de la estructura aditiva o mediante el uso de la estructura multiplicativa según el conjunto de datos. La estructura o modelo aditivo se usa cuando el patrón estacional de los datos tiene la misma magnitud o es consistente en todo momento, mientras que la estructura o modelo multiplicativo se usa si la magnitud del patrón estacional de los datos aumenta con el tiempo. Utiliza tres parámetros de suavizado: alfa, beta y gamma .
En R, usamos la función decompose() para realizar este tipo de suavizado exponencial. Usaremos el conjunto de datos de qcement para estudiar el funcionamiento de esta técnica.
Ejemplo 1:
R
# Holt-Winter's method in R # loading packages library(tidyverse) library(fpp2) # create training and validation # of the AirPassengers data qcement.train <- window(qcement, end = c(2012, 4)) qcement.test <- window(qcement, start = c(2013, 1)) # applying holt-winters # method on qcement autoplot(decompose(qcement))
Producción:
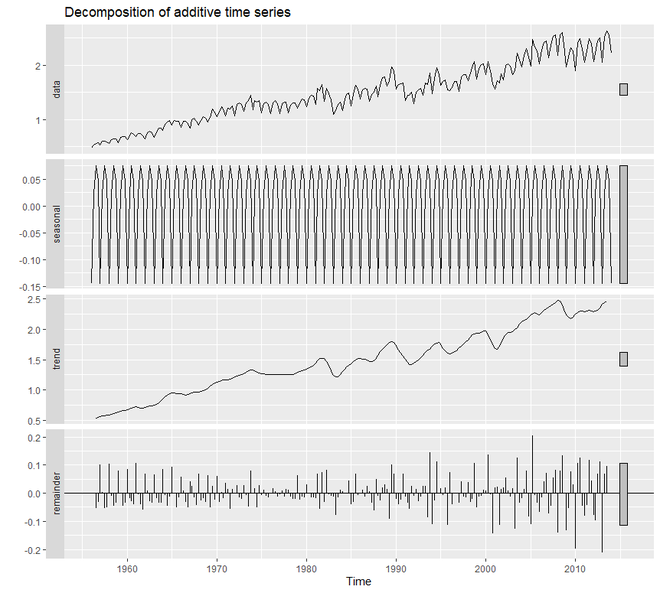
Para crear un modelo aditivo que se ocupe del error, la tendencia y la estacionalidad, vamos a utilizar la función ets() . De los 36 modelos, ets() elige el mejor modelo aditivo. Para el modelo aditivo, el parámetro del modelo de ets() será ‘AAA’.
Ejemplo 2:
R
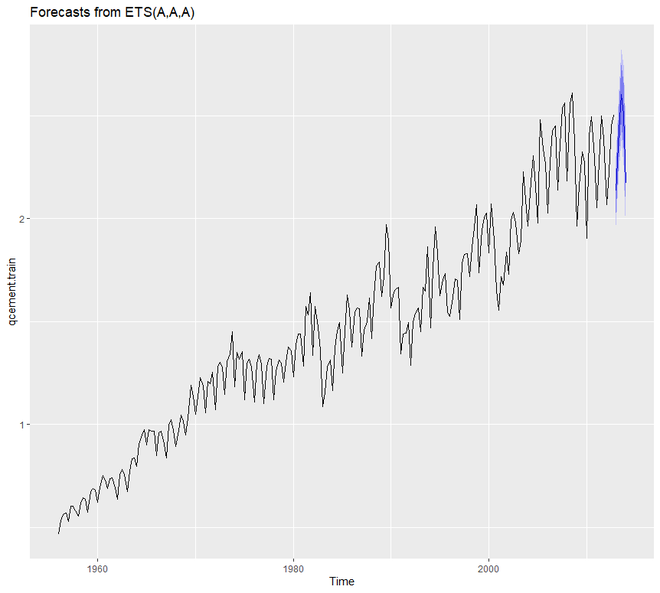
# loading package library(tidyverse) library(fpp2) # create training and validation # of the AirPassengers data qcement.train <- window(qcement, end = c(2012, 4)) qcement.test <- window(qcement, start = c(2013, 1)) # applying ets qcement.hw <- ets(qcement.train, model = "AAA") autoplot(forecast(qcement.hw))
Producción:
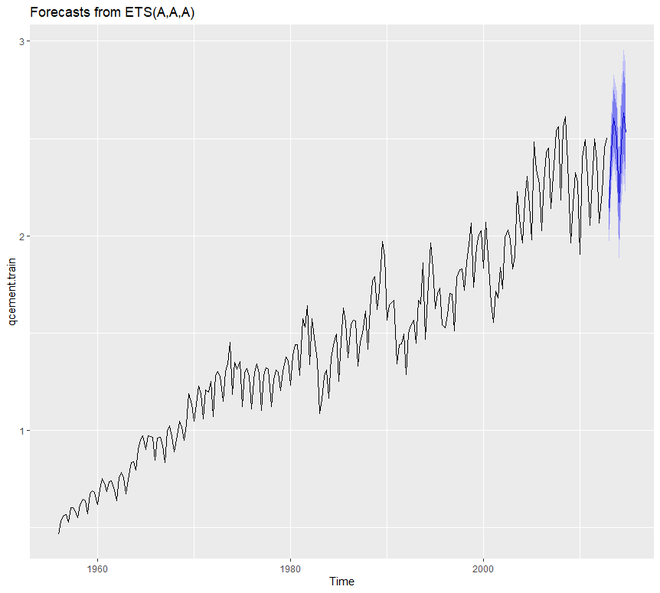
Ahora evaluaremos nuestro modelo y resumiremos los parámetros de suavizado. También comprobaremos los residuos y averiguaremos la precisión de nuestro modelo.
Ejemplo 3:
R
# additive model # loading packages library(tidyverse) library(fpp2) # create training and validation # of the AirPassengers data qcement.train <- window(qcement, end = c(2012, 4)) qcement.test <- window(qcement, start = c(2013, 1)) qcement.hw <- ets(qcement.train, model = "AAA") # assessing our model summary(qcement.hw) checkresiduals(qcement.hw) # forecast the next 5 quarters qcement.f1 <- forecast(qcement.hw, h = 5) # check accuracy accuracy(qcement.f1, qcement.test)
Producción:
> summary(qcement.hw)
ETS(A,A,A)
Call:
ets(y = qcement.train, model = "AAA")
Smoothing parameters:
alpha = 0.6418
beta = 1e-04
gamma = 0.1988
Initial states:
l = 0.4511
b = 0.0075
s = 0.0049 0.0307 9e-04 -0.0365
sigma: 0.0854
AIC AICc BIC
126.0419 126.8676 156.9060
Training set error measures:
ME RMSE MAE MPE MAPE MASE ACF1
Training set 0.001463693 0.08393279 0.0597683 -0.003454533 3.922727 0.5912949 0.02150539
> checkresiduals(qcement.hw)
Ljung-Box test
data: Residuals from ETS(A,A,A)
Q* = 20.288, df = 3, p-value = 0.0001479
Model df: 8. Total lags used: 11
> accuracy(qcement.f1, qcement.test)
ME RMSE MAE MPE MAPE MASE ACF1 Theil's U
Training set 0.001463693 0.08393279 0.05976830 -0.003454533 3.922727 0.5912949 0.02150539 NA
Test set 0.031362775 0.07144211 0.06791904 1.115342984 2.899446 0.6719311 -0.31290496 0.2112428
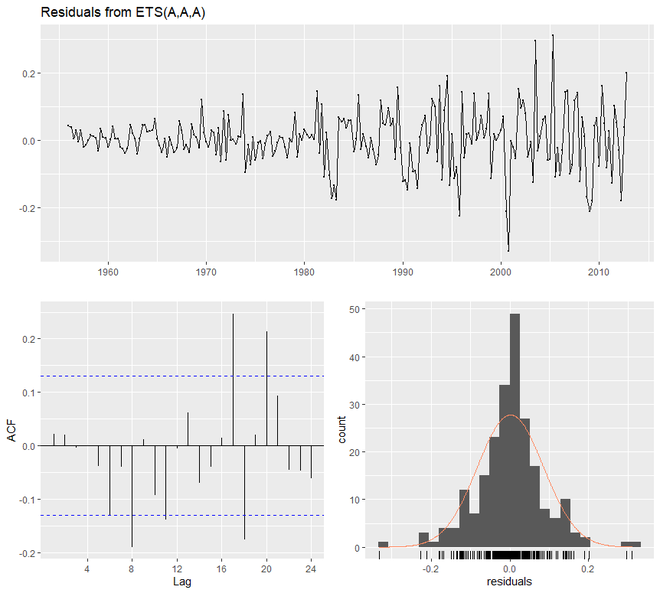
Ahora vamos a ver cómo funciona el modelo multiplicativo usando ets() . Para ello, el parámetro del modelo de ets() será ‘MAM’.
Ejemplo 4:
R
# multiplicative model in R # loading package library(tidyverse) library(fpp2) # create training and validation # of the AirPassengers data qcement.train <- window(qcement, end = c(2012, 4)) qcement.test <- window(qcement, start = c(2013, 1)) # applying ets qcement.hw2 <- ets(qcement.train, model = "MAM") checkresiduals(qcement.hw2)
Producción:
> checkresiduals(qcement.hw2)
Ljung-Box test
data: Residuals from ETS(M,A,M)
Q* = 23.433, df = 3, p-value = 3.281e-05
Model df: 8. Total lags used: 11
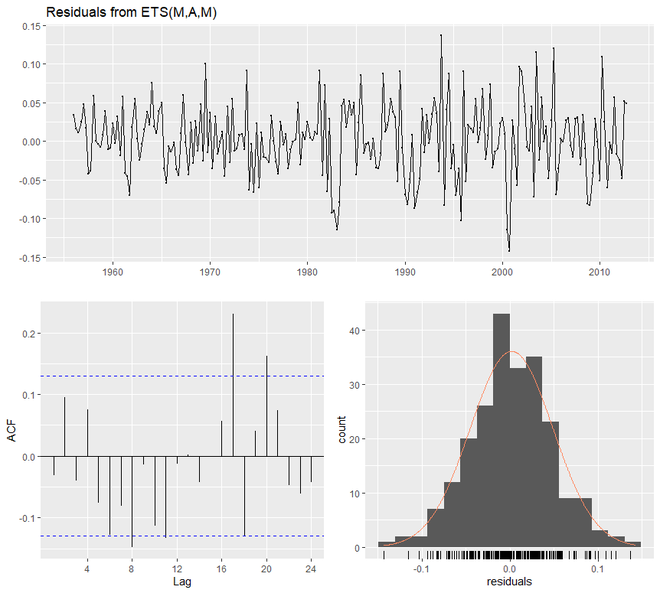
Aquí optimizaremos el parámetro gamma para minimizar la tasa de error. El valor de gamma será 0,21. Junto con eso, vamos a averiguar la precisión y también trazar los valores predictivos.
Ejemplo 5:
R
# Holt winters model in R
# loading packages
library(tidyverse)
library(fpp2)
# create training and validation
# of the AirPassengers data
qcement.train <- window(qcement,
end = c(2012, 4))
qcement.test <- window(qcement,
start = c(2013, 1))
qcement.hw <- ets(qcement.train,
model = "AAA")
# forecast the next 5 quarters
qcement.f1 <- forecast(qcement.hw,
h = 5)
# check accuracy
accuracy(qcement.f1, qcement.test)
gamma <- seq(0.01, 0.85, 0.01)
RMSE <- NA
for(i in seq_along(gamma)) {
hw.expo <- ets(qcement.train,
"AAA",
gamma = gamma[i])
future <- forecast(hw.expo,
h = 5)
RMSE[i] = accuracy(future,
qcement.test)[2,2]
}
error <- data_frame(gamma, RMSE)
minimum <- filter(error,
RMSE == min(RMSE))
ggplot(error, aes(gamma, RMSE)) +
geom_line() +
geom_point(data = minimum,
color = "blue", size = 2) +
ggtitle("gamma's impact on
forecast errors",
subtitle = "gamma = 0.21 minimizes RMSE")
# previous model with additive
# error, trend and seasonality
accuracy(qcement.f1, qcement.test)
# new model with
# optimal gamma parameter
qcement.hw6 <- ets(qcement.train,
model = "AAA",
gamma = 0.21)
qcement.f6 <- forecast(qcement.hw6,
h = 5)
accuracy(qcement.f6, qcement.test)
# predicted values
qcement.f6
autoplot(qcement.f6)
Producción:
> accuracy(qcement.f1, qcement.test)
ME RMSE MAE MPE MAPE MASE ACF1 Theil's U
Training set 0.001463693 0.08393279 0.05976830 -0.003454533 3.922727 0.5912949 0.02150539 NA
Test set 0.031362775 0.07144211 0.06791904 1.115342984 2.899446 0.6719311 -0.31290496 0.2112428
> accuracy(qcement.f6, qcement.test)
ME RMSE MAE MPE MAPE MASE ACF1 Theil's U
Training set -0.001312025 0.08377557 0.05905971 -0.2684606 3.834134 0.5842847 0.04832198 NA
Test set 0.033492771 0.07148708 0.06775269 1.2096488 2.881680 0.6702854 -0.35877010 0.2202448
> qcement.f6
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
2013 Q1 2.134650 2.025352 2.243947 1.967494 2.301806
2013 Q2 2.427828 2.299602 2.556055 2.231723 2.623934
2013 Q3 2.601989 2.457284 2.746694 2.380681 2.823296
2013 Q4 2.505001 2.345506 2.664496 2.261075 2.748927
2014 Q1 2.171068 1.987914 2.354223 1.890958 2.451179
Método de amortiguamiento en R
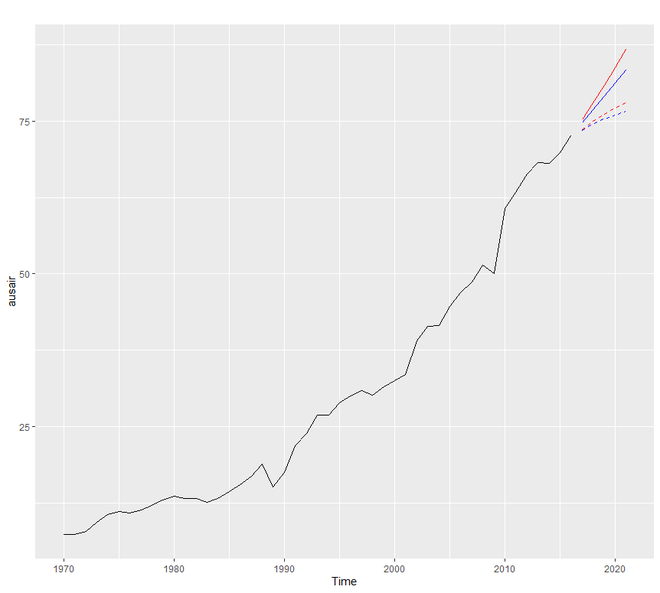
El método de amortiguamiento utiliza el coeficiente de amortiguamiento phi para estimar de forma más conservadora las tendencias previstas. El valor de phi se encuentra entre 0 y 1. Si creemos que nuestro modelo aditivo y multiplicativo va a ser una línea plana, es probable que esté amortiguado. Para comprender el principio de funcionamiento del pronóstico de amortiguamiento, utilizaremos el conjunto de datos fpp2::ausair donde crearemos muchos modelos e intentaremos tener líneas de tendencia mucho más conservadoras.
Ejemplo:
R
# Damping model in R # loading the packages library(tidyverse) library(fpp2) # holt's linear (additive) model fit1 <- ets(ausair, model = "ZAN", alpha = 0.8, beta = 0.2) pred1 <- forecast(fit1, h = 5) # holt's linear (additive) model fit2 <- ets(ausair, model = "ZAN", damped = TRUE, alpha = 0.8, beta = 0.2, phi = 0.85) pred2 <- forecast(fit2, h = 5) # holt's exponential # (multiplicative) model fit3 <- ets(ausair, model = "ZMN", alpha = 0.8, beta = 0.2) pred3 <- forecast(fit3, h = 5) # holt's exponential # (multiplicative) model damped fit4 <- ets(ausair, model = "ZMN", damped = TRUE, alpha = 0.8, beta = 0.2, phi = 0.85) pred4 <- forecast(fit4, h = 5) autoplot(ausair) + autolayer(pred1$mean, color = "blue") + autolayer(pred2$mean, color = "blue", linetype = "dashed") + autolayer(pred3$mean, color = "red") + autolayer(pred4$mean, color = "red", linetype = "dashed")
Producción: