Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
La función sort_values() de Pandas ordena un marco de datos en orden ascendente o descendente de la columna pasada. Es diferente a la función ordenada de Python, ya que no puede ordenar un marco de datos y no se puede seleccionar una columna en particular.
Analicemos Dataframe.sort_values() Ordenación de un solo parámetro:
Sintaxis:
DataFrame.sort_values(by, axis=0, ascendente=True, inplace=False, kind=’quicksort’, na_position=’last’)
Cada parámetro tiene algunos valores predeterminados excepto el parámetro ‘por’.
Parámetros:
por: Único/Lista de nombres de columna para ordenar el marco de datos por.
eje: 0 o ‘índice’ para filas y 1 o ‘columnas’ para Columna.
ascendente: valor booleano que ordena el marco de datos en orden ascendente si es verdadero.
inplace: valor booleano. Realiza los cambios en el marco de datos pasado si es True.
kind: string que puede tener tres entradas (‘quicksort’, ‘mergesort’ o ‘heapsort’) del algoritmo utilizado para ordenar el marco de datos.
na_position: toma la entrada de dos strings ‘último’ o ‘primero’ para establecer la posición de los valores nulos. El valor predeterminado es ‘último’.
Tipo de devolución:
Devuelve un marco de datos ordenado con las mismas dimensiones que el marco de datos que llama a la función.
Para obtener un enlace al archivo CSV utilizado en el código, haga clic aquí.
Ejemplo #1: Clasificación por nombre
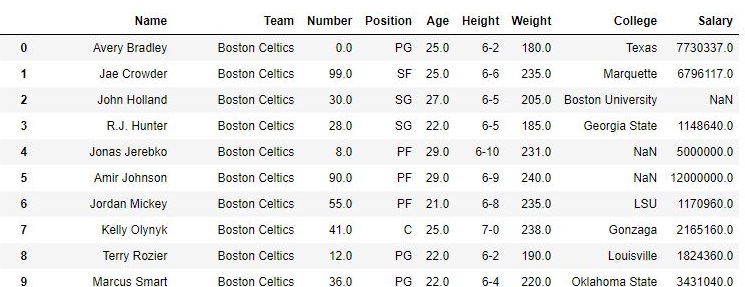
En el siguiente ejemplo, se crea un marco de datos a partir del archivo csv y el marco de datos se ordena en orden ascendente de Nombres de jugadores.
Antes de clasificar-
Python
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# display
data
Producción:
Después de ordenar-
Python
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# sorting data frame by name
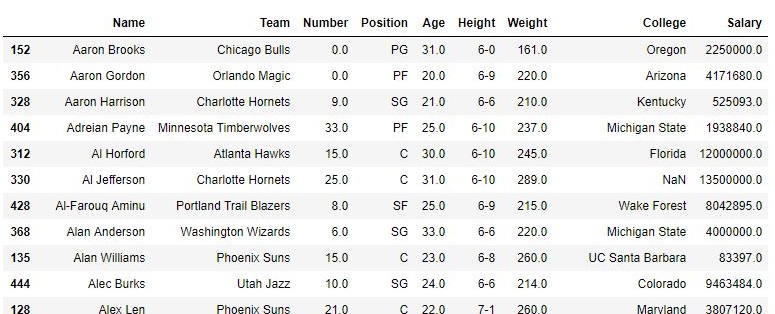
data.sort_values("Name", axis = 0, ascending = True,
inplace = True, na_position ='last')
# display
data
Como se muestra en la imagen, la columna de índice ahora está desordenada ya que el marco de datos está ordenado por Nombre.
Producción:
Ejemplo #2: Cambiar la posición de los valores nulos
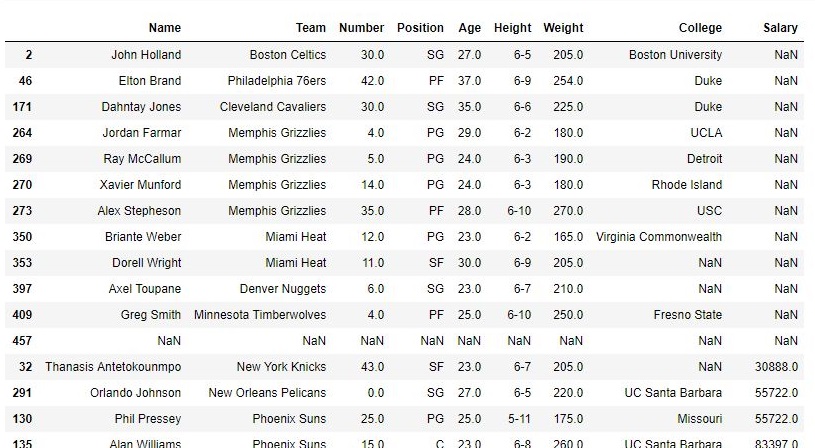
En los datos proporcionados, hay muchos valores nulos en diferentes columnas que se colocan en el último lugar de manera predeterminada. En este ejemplo, el marco de datos se ordena con respecto a la columna Salario y los valores nulos se mantienen en la parte superior.
Python
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# sorting data frame by name
data.sort_values("Salary", axis = 0, ascending = True,
inplace = True, na_position ='first')
data
# display
Como se muestra en la imagen de salida, los valores de NaN están en la parte superior y luego viene el valor ordenado de Salario.
Producción:
Publicación traducida automáticamente
Artículo escrito por Kartikaybhutani y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA