En este artículo, discutiremos cómo obtener el número de filas y el número de columnas de un marco de datos de PySpark. Para encontrar el número de filas y el número de columnas, usaremos count() y column() con la función len() respectivamente.
- df.count(): esta función se usa para extraer el número de filas del marco de datos.
- df.distinct().count(): esta función se usa para extraer filas de números distintos que no están duplicados/repetidos en el marco de datos.
- df.columns(): esta función se utiliza para extraer la lista de nombres de columnas presentes en el marco de datos.
- len(df.columns): esta función se utiliza para contar el número de elementos presentes en la lista.
Ejemplo 1: obtenga el número de filas y el número de columnas del marco de datos en pyspark.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Products.com") \
.getOrCreate()
return spk
# function to create Dataframe
def create_df(spark,data,schema):
df1 = spark.createDataFrame(data,schema)
return df1
# main function
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [(1,"Direct-Cool Single Door Refrigerator",12499),
(2,"Full HD Smart LED TV",49999),
(3,"8.5 kg Washing Machine",69999),
(4,"T-shirt",1999),
(5,"Jeans",3999),
(6,"Men's Running Shoes",1499),
(7,"Combo Pack Face Mask",999)]
schm = ["Id","Product Name","Price"]
# calling function to create dataframe
df = create_df(spark,input_data,schm)
df.show()
# extracting number of rows from the Dataframe
row = df.count()
# extracting number of columns from the Dataframe
col = len(df.columns)
# printing
print(f'Dimension of the Dataframe is: {(row,col)}')
print(f'Number of Rows are: {row}')
print(f'Number of Columns are: {col}')
Producción:
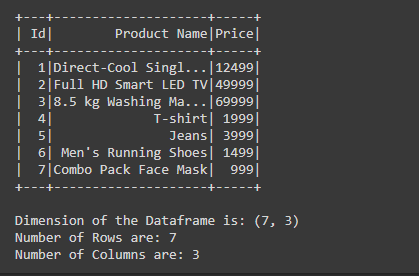
Explicación:
- Para contar el número de filas, usamos la función count() df.count() que extrae el número de filas del marco de datos y lo almacena en la variable denominada ‘fila’
- Para contar el número de columnas estamos usando df.columns() pero como esta función devuelve la lista de nombres de columnas, entonces para contar el número de elementos presentes en la lista estamos usando la función len() en la que estamos pasando df .columns() esto nos da el número total de columnas y lo almacena en la variable llamada ‘col’.
Ejemplo 2: Obtener el número Distinto de filas y columnas de Dataframe.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Student_report.com") \
.getOrCreate()
return spk
# function to create Dataframe
def create_df(spark,data,schema):
df1 = spark.createDataFrame(data,schema)
return df1
# main function
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [(1,"Shivansh","Male",20,80),
(2,"Arpita","Female",18,66),
(3,"Raj","Male",21,90),
(4,"Swati","Female",19,91),
(5,"Arpit","Male",20,50),
(6,"Swaroop","Male",23,65),
(6,"Swaroop","Male",23,65),
(6,"Swaroop","Male",23,65),
(7,"Reshabh","Male",19,70),
(7,"Reshabh","Male",19,70),
(8,"Dinesh","Male",20,75),
(9,"Rohit","Male",21,85),
(9,"Rohit","Male",21,85),
(10,"Sanjana","Female",22,87)]
schm = ["Id","Name","Gender","Age","Percentage"]
# calling function to create dataframe
df = create_df(spark,input_data,schm)
df.show()
# extracting number of distinct rows
# from the Dataframe
row = df.distinct().count()
# extracting total number of rows from
# the Dataframe
all_rows = df.count()
# extracting number of columns from the
# Dataframe
col = len(df.columns)
# printing
print(f'Dimension of the Dataframe is: {(row,col)}')
print(f'Distinct Number of Rows are: {row}')
print(f'Total Number of Rows are: {all_rows}')
print(f'Number of Columns are: {col}')
Producción:
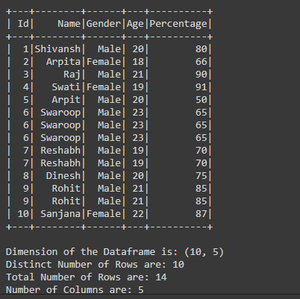
Explicación:
- Para contar el número de filas distintas, estamos usando la función distintiva(). Contar() que extrae el número de filas distintas del marco de datos y lo almacena en la variable denominada ‘fila’
- Para contar el número de columnas estamos usando df.columns() pero como esta función devuelve la lista de nombres de columnas, entonces para contar el número de elementos presentes en la lista estamos usando la función len() en la que estamos pasando df .columns() esto nos da el número total de columnas y lo almacena en la variable llamada ‘col’
Ejemplo 3: Obtener el número de columnas usando la función dtypes.
En el ejemplo, después de crear el Dataframe estamos contando una cantidad de filas usando la función count() y para contar la cantidad de columnas aquí estamos usando la función dtypes . Como sabemos que la función dtypes devuelve la lista de tuplas que contiene el nombre de la columna y el tipo de datos de las columnas. Entonces, para cada columna, existe la tupla que contiene el nombre y el tipo de datos de la columna, de la lista solo contamos las tuplas. El número de tuplas es igual al número de columnas, por lo que esta es también la única forma de obtener el número. de columnas usando la función dtypes.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Student_report.com") \
.getOrCreate()
return spk
# function to create Dataframe
def create_df(spark,data,schema):
df1 = spark.createDataFrame(data,schema)
return df1
# main function
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [(1,"Shivansh","Male",20,80),
(2,"Arpita","Female",18,66),
(3,"Raj","Male",21,90),
(4,"Swati","Female",19,91),
(5,"Arpit","Male",20,50),
(6,"Swaroop","Male",23,65),
(7,"Reshabh","Male",19,70),
(8,"Dinesh","Male",20,75),
(9,"Rohit","Male",21,85),
(10,"Sanjana","Female",22,87)]
schm = ["Id","Name","Gender","Age","Percentage"]
# calling function to create dataframe
df = create_df(spark,input_data,schm)
df.show()
# extracting number of rows from the Dataframe
row = df.count()
# extracting number of columns from the Dataframe using dtypes function
col = len(df.dtypes)
# printing
print(f'Dimension of the Dataframe is: {(row,col)}')
print(f'Number of Rows are: {row}')
print(f'Number of Columns are: {col}')
Producción:
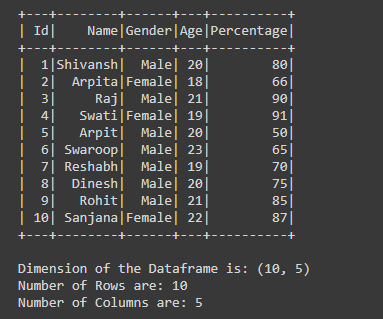
Ejemplo 4: obtener la dimensión del marco de datos de PySpark al convertir el marco de datos de PySpark en el marco de datos de Pandas.
En el código de ejemplo, después de crear el Dataframe, estamos convirtiendo el PySpark Dataframe en Pandas Dataframe usando la función toPandas() escribiendo df.toPandas(). Después de convertir el marco de datos, estamos usando la forma de la función Pandas para obtener la dimensión del marco de datos. Esta función de forma devuelve la tupla, por lo que para imprimir el número de fila y columna individualmente.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Student_report.com") \
.getOrCreate()
return spk
# function to create Dataframe
def create_df(spark,data,schema):
df1 = spark.createDataFrame(data,schema)
return df1
# main function
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [(1,"Shivansh","Male",20,80),
(2,"Arpita","Female",18,66),
(3,"Raj","Male",21,90),
(4,"Swati","Female",19,91),
(5,"Arpit","Male",20,50),
(6,"Swaroop","Male",23,65),
(7,"Reshabh","Male",19,70),
(8,"Dinesh","Male",20,75),
(9,"Rohit","Male",21,85),
(10,"Sanjana","Female",22,87)]
schm = ["Id","Name","Gender","Age","Percentage"]
# calling function to create dataframe
df = create_df(spark,input_data,schm)
df.show()
# converting PySpark df to Pandas df using
# toPandas() function
new_df = df.toPandas()
# using Pandas shape function for getting the
# dimension of the df
dimension = new_df.shape
# printing
print("Dimension of the Dataframe is: ",dimension)
print(f'Number of Rows are: {dimension[0]}')
print(f'Number of Columns are: {dimension[1]}')
Producción:
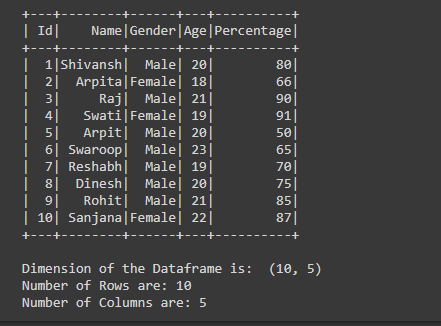
Publicación traducida automáticamente
Artículo escrito por srishivansh5404 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA