En este artículo, veremos diferentes formas de agregar columnas múltiples en marcos de datos de PySpark.
Vamos a crear un marco de datos de muestra para la demostración:
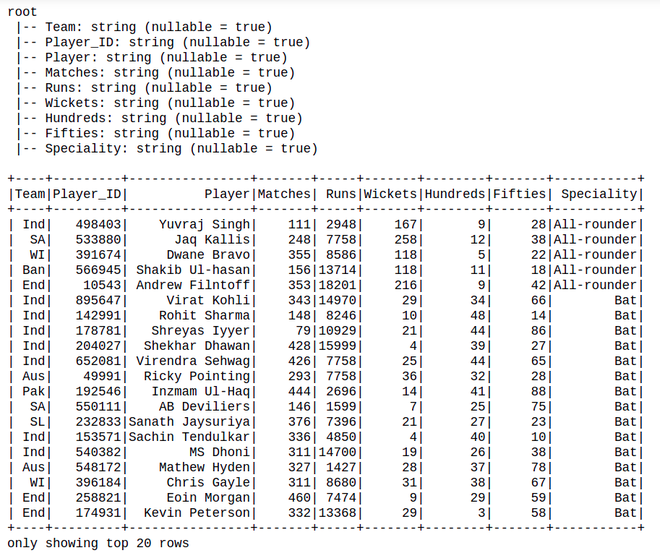
Conjunto de datos utilizado: Cricket_data_set_odi
Python3
# import pandas to read json file
import pandas as pd
# importing module
import pyspark
# importing sparksession from pyspark.sql
# module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# create Dataframe
df=spark.read.option(
"header",True).csv("Cricket_data_set_odi.csv")
# Display Schema
df.printSchema()
# Show Dataframe
df.show()
Producción:
Método 1: Usando withColumn()
withColumn() se usa para agregar una columna nueva o actualizar una columna existente en DataFrame
Sintaxis: df.withColumn(colName, col)
Devuelve: una nueva :class:`DataFrame` agregando una columna o reemplazando la columna existente que tiene el mismo nombre.
Código:
Python3
df.withColumn( 'Avg_runs', df.Runs / df.Matches).withColumn( 'wkt+10', df.Wickets+10).show()
Producción:

Método 2 : Usar select()
También puede agregar varias columnas usando seleccionar.
Sintaxis: df.select(*columnas)
Código:
Python3
# Using select() to Add Multiple Column
df.select('*', (df.Runs / df.Matches).alias('Avg_runs'),
(df.Wickets+10).alias('wkt+10')).show()
Producción :

Método 3: agregar una columna múltiple constante a DataFrame usando withColumn() y select()
Vamos a crear una nueva columna con valor constante usando la función SQL lit(), en el siguiente código. La función lit() presente en Pyspark se usa para agregar una nueva columna en un marco de datos de Pyspark asignando un valor constante o literal.
Python3
from pyspark.sql.functions import col, lit
df.select('*',lit("Cricket").alias("Sport")).
withColumn("Fitness",lit(("Good"))).show()
Producción:
