Una serie de puntos de datos recopilados en el transcurso de un período de tiempo y que están indexados en el tiempo se conocen como datos de series temporales. Estas observaciones se registran en puntos sucesivos igualmente espaciados en el tiempo. Por ejemplo, la señal de ECG, la señal de EEG, el mercado de valores, los datos meteorológicos, etc., se indexan en el tiempo y se registran durante un período de tiempo. Analizar estos datos y predecir futuras observaciones tiene un alcance de investigación más amplio.
En este artículo, veremos cómo implementar EDA: análisis exploratorio de datos utilizando Pandas Library en Python. Intentaremos inferir la naturaleza de los datos durante un período de tiempo específico trazando varios gráficos con matplotlib.pyplot, seaborn, statsmodels y más paquetes.
Para facilitar la comprensión de los gráficos y otras funciones, crearemos un conjunto de datos de muestra con 16 filas y 5 columnas que incluye las columnas Fecha, A, B, C, D y E.
Python3
import pandas as pd
# Sample data which will be used
# to create the dataframe
sample_timeseries_data = {
'Date': ['2020-01-25', '2020-02-25',
'2020-03-25', '2020-04-25',
'2020-05-25', '2020-06-25',
'2020-07-25', '2020-08-25',
'2020-09-25', '2020-10-25',
'2020-11-25', '2020-12-25',
'2021-01-25', '2021-02-25',
'2021-03-25', '2021-04-25'],
'A': [102, 114, 703, 547,
641, 669, 897, 994,
1002, 974, 899, 954,
1105, 1189, 1100, 934],
'B': [1029, 1178, 723, 558,
649, 669, 899, 1000,
1012, 984, 918, 959,
1125, 1199, 1109, 954],
'C': [634, 422,152, 23,
294, 1452, 891, 990,
924, 960, 874, 548,
174, 49, 655, 914],
'D': [1296, 7074, 3853, 4151,
2061, 1478, 2061, 3853,
6379, 2751, 1064, 6263,
2210, 6566, 3918, 1121],
'E': [10, 17, 98, 96,
85, 89, 90, 92,
86, 84, 78, 73,
71, 65, 70, 60]
}
# Creating a dataframe using pandas
# module with Date, A, B, C, D and E
# as columns.
dataframe = pd.DataFrame(
sample_timeseries_data,columns=[
'Date', 'A', 'B', 'C', 'D', 'E'])
# Changing the datatype of Date, from
# Object to datetime64
dataframe["Date"] = dataframe["Date"].astype("datetime64")
# Setting the Date as index
dataframe = dataframe.set_index("Date")
dataframe
Producción:
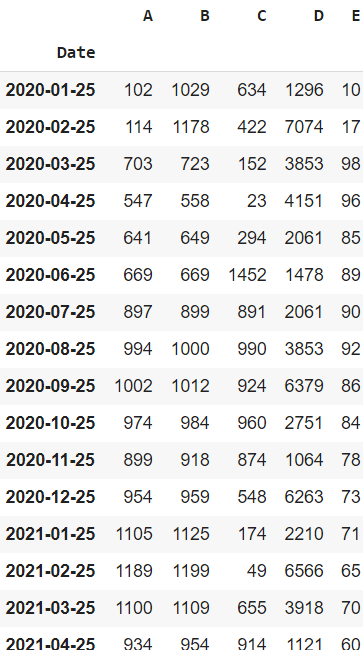
Marco de datos de serie temporal de muestra
Trazar los datos de la serie temporal
Trazado de gráfico de líneas basado en series temporales :
Los gráficos de líneas se utilizan para representar la relación entre dos datos X e Y en un eje diferente.
Sintaxis: plt.plot(x)
Ejemplo 1: este gráfico muestra la variación de los valores de la columna A desde enero de 2020 hasta abril de 2020. Tenga en cuenta que los valores tienen una tendencia positiva en general, pero hay altibajos a lo largo del curso.
Python3
import matplotlib.pyplot as plt
# Using a inbuilt style to change
# the look and feel of the plot
plt.style.use("fivethirtyeight")
# setting figure size to 12, 10
plt.figure(figsize=(12, 10))
# Labelling the axes and setting
# a title
plt.xlabel("Date")
plt.ylabel("Values")
plt.title("Sample Time Series Plot")
# plotting the "A" column alone
plt.plot(dataframe["A"])
Producción:
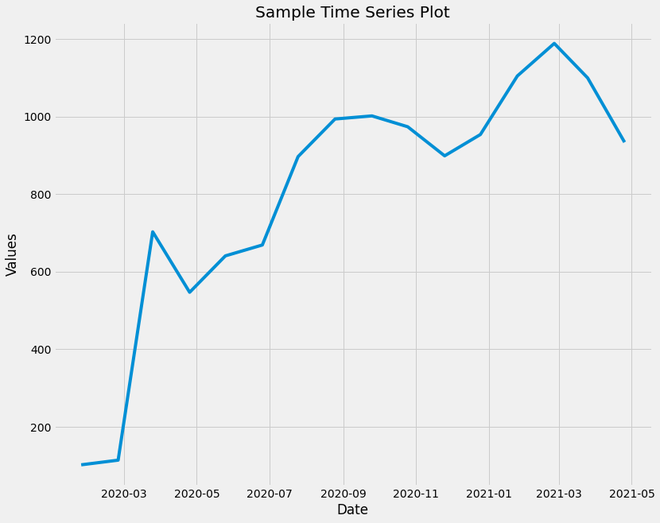
Gráfico de serie temporal de muestra
Ejemplo 2: Trazado con todas las variables.
Python3
plt.style.use("fivethirtyeight")
dataframe.plot(subplots=True, figsize=(12, 15))
Producción:
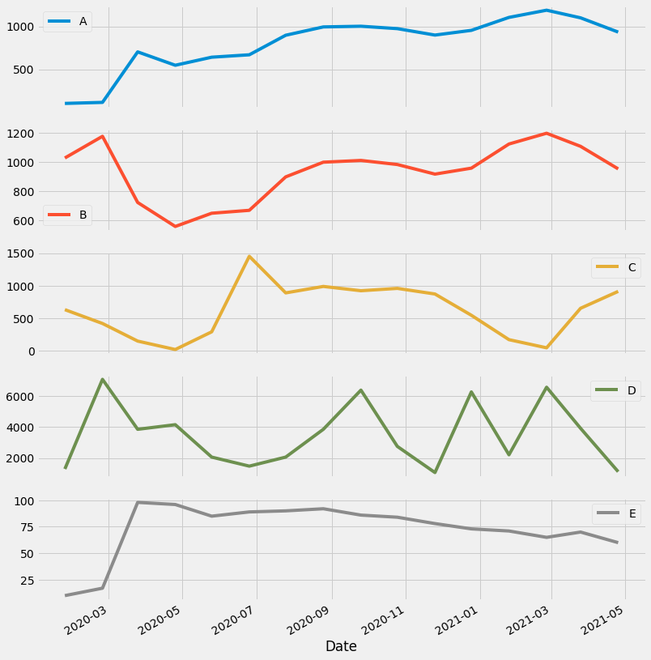
Trazado de todas las columnas de datos de series temporales
Trazado Gráfico de barras basado en series temporales :
Un diagrama de barras o gráfico de barras es un gráfico que representa la categoría de datos con barras rectangulares con longitudes y alturas proporcionales a los valores que representan. Los gráficos de barras se pueden trazar horizontal o verticalmente. Un gráfico de barras describe las comparaciones entre las categorías discretas. Uno de los ejes del gráfico representa las categorías específicas que se comparan, mientras que el otro eje representa los valores medidos correspondientes a esas categorías.
Sintaxis: plt.bar(x, alto, ancho, inferior, alinear)
Este gráfico de barras representa la variación de los valores de la columna ‘A’. Esto se puede utilizar para comparar el futuro y los valores rápidos.
Python3
import matplotlib.pyplot as plt
# Using a inbuilt style to change
# the look and feel of the plot
plt.style.use("fivethirtyeight")
# setting figure size to 12, 10
plt.figure(figsize=(15, 10))
# Labelling the axes and setting a
# title
plt.xlabel("Date")
plt.ylabel("Values")
plt.title("Bar Plot of 'A'")
# plotting the "A" column alone
plt.bar(dataframe.index, dataframe["A"], width=5)
Producción:

Gráfico de barras para la columna ‘A’
Trazado de gráficos de media móvil basados en series de tiempo :
La media de una ventana de tamaño n que se desliza desde el principio hasta el final del marco de datos se conoce como media móvil. Si la ventana no tiene n observaciones, se devuelve NaN.
Sintaxis: pandas.DataFrame.rolling(n).mean()
Ejemplo:
Python3
dataframe.rolling(window = 5).mean()
Producción:
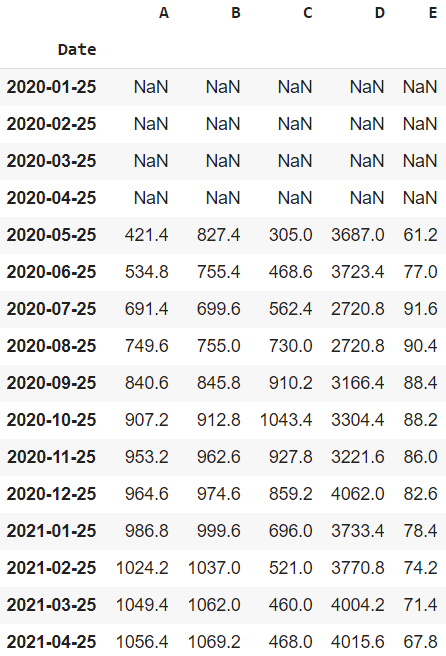
La media móvil del marco de datos
Aquí, trazaremos la serie de tiempo con una gráfica de media móvil:
Python3
import matplotlib.pyplot as plt
# Using a inbuilt style to change
# the look and feel of the plot
plt.style.use("fivethirtyeight")
# setting figure size to 12, 10
plt.figure(figsize=(12, 10))
# Labelling the axes and setting
# a title
plt.xlabel("Date")
plt.ylabel("Values")
plt.title("Values of 'A' and Rolling Mean (2) Plot")
# plotting the "A" column and "A" column
# of Rolling Dataframe (window_size = 20)
plt.plot(dataframe["A"])
plt.plot(dataframe.rolling(
window=2, min_periods=1).mean()["A"])
Producción:
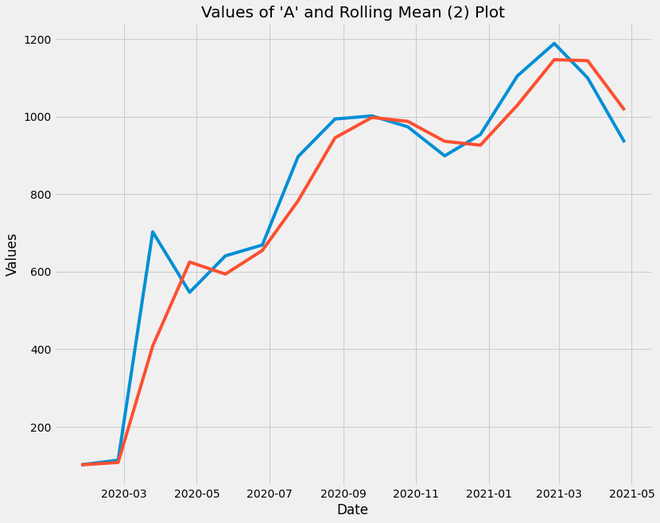
Gráfico de media móvil
Explicación:
- La línea azul del gráfico representa los valores originales de la columna ‘A’, mientras que la línea roja del gráfico representa la media móvil de los valores de la columna ‘A’ del tamaño de la ventana = 2
- A través de este gráfico, inferimos que la media móvil de los datos de una serie temporal devuelve valores con menos fluctuaciones. Se conserva la tendencia de la trama, pero se descartan los altibajos no deseados que son de menor importancia.
- Para graficar la descomposición de datos de series de tiempo, análisis de diagramas de caja, etc., es una buena práctica usar un marco de datos de media móvil para que las fluctuaciones no afecten el análisis, especialmente al pronosticar la tendencia.
Descomposición de series de tiempo:
Muestra las observaciones y estos cuatro elementos en el mismo gráfico:
- Componente de tendencia: muestra el patrón de los datos que se extienden a lo largo de los distintos períodos estacionales. Representa la variación de los valores ‘A’ durante un período de 2 años sin fluctuaciones.
- Componente estacional: este gráfico muestra los altibajos de los valores ‘A’, es decir, las variaciones normales recurrentes.
- Componente Residual: Este es el componente sobrante después de descomponer los datos de valores ‘A’ en Tendencia y Componente Estacional.
- Componente observado: esta tendencia y un componente estacional se pueden utilizar para estudiar los datos con diversos fines.
Ejemplo:
Python3
import statsmodels.api as sm
from pylab import rcParams
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Separating the Date Component into
# Year and Month
dataframe['Date'] = dataframe.index
dataframe['Year'] = dataframe['Date'].dt.year
dataframe['Month'] = dataframe['Date'].dt.month
# using inbuilt style
plt.style.use("fivethirtyeight")
# Creating a dataframe with "Date" and "A"
# columns only. This dataframe is date indexed
decomposition_dataframe = dataframe[['Date', 'A']].copy()
decomposition_dataframe.set_index('Date', inplace=True)
decomposition_dataframe.index = pd.to_datetime(decomposition_dataframe.index)
# using sm.tsa library, we are plotting the
# seasonal decomposition of the "A" column
# Multiplicative Model : Y[t] = T[t] * S[t] * R[t]
decomposition = sm.tsa.seasonal_decompose(decomposition_dataframe,
model='multiplicative', freq=5)
decomp = decomposition.plot()
decomp.suptitle('"A" Value Decomposition')
# changing the runtime configuration parameters to
# have a desired plot of desired size, etc
rcParams['figure.figsize'] = 12, 10
rcParams['axes.labelsize'] = 12
rcParams['ytick.labelsize'] = 12
rcParams['xtick.labelsize'] = 12
Producción:
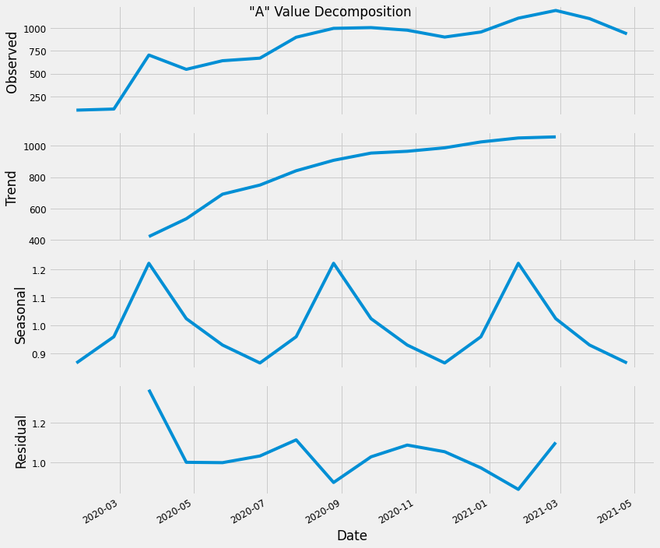
Descomposición del valor ‘A’
Trazado de gráficos de autocorrelación basados en series temporales :
Es una herramienta de uso común para verificar la aleatoriedad en un conjunto de datos. Esta aleatoriedad se determina calculando la autocorrelación de los valores de los datos en diferentes intervalos de tiempo. Muestra las propiedades de un tipo de datos conocido como serie temporal. Estos gráficos están disponibles en la mayoría de los programas de software estadístico de propósito general. Se puede trazar utilizando pandas.plotting.autocorrelation_plot().
Sintaxis: pandas.plotting.autocorrelation_plot(series, ax=Ninguno, **kwargs)
Parámetros:
- series: este parámetro es la serie temporal que se utilizará para trazar.
- hacha: este parámetro es un objeto de ejes matplotlib. Su valor predeterminado es Ninguno.
Devoluciones: esta función devuelve un objeto de clase matplotlip.axis.Axes
Teniendo en cuenta la tendencia, estacionalidad, cíclica y residual, esta gráfica muestra que el valor actual de los datos de la serie temporal está relacionado con los valores anteriores. Podemos ver que una proporción significativa de la línea muestra una correlación efectiva con el tiempo, y podemos usar dichos gráficos de correlación para estudiar la dependencia interna de los datos de series temporales.
Código:
Python3
from pandas.plotting import autocorrelation_plot autocorrelation_plot(dataframe['A'])
Producción:
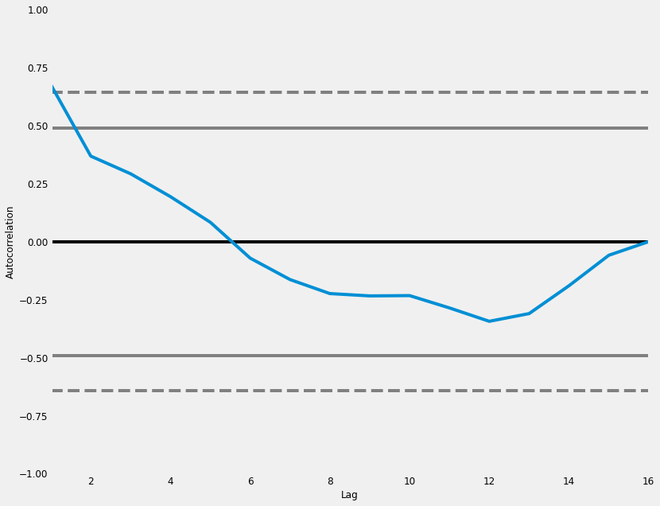
Gráfica de autocorrelación
Trazado de diagrama de caja basado en series temporales :
Box Plot es la representación visual de los grupos de representación de datos numéricos a través de sus cuartiles. Boxplot también se usa para detectar el valor atípico en el conjunto de datos. Captura el resumen de los datos de manera eficiente con un simple cuadro y bigotes y nos permite comparar fácilmente entre grupos. Boxplot resume los datos de una muestra utilizando los percentiles 25, 50 y 75.
Sintaxis: seaborn.boxplot(x=Ninguno, y=Ninguno, hue=Ninguno, data=Ninguno, order=Ninguno, hue_order=Ninguno, orient=Ninguno, color=Ninguno, palette=Ninguno, saturación=0.75, ancho=0.8, dodge=True, fliersize=5, linewidth=Ninguno, whis=1.5, ax=Ninguno, **kwargs)
Parámetros:
x, y, hue: Entradas para trazar datos de formato largo.
datos: conjunto de datos para el trazado. Si x e y están ausentes, esto se interpreta como formato ancho.
color: Color para todos los elementos.Devoluciones: Devuelve el objeto Axes con la trama dibujada en él.
Aquí, a través de estos gráficos, podremos obtener una intuición de los rangos de valores ‘A’ de cada año (Gráfico de caja por año) así como de cada mes (Gráfico de caja por mes). Además, a través del diagrama de caja mensual, podemos observar que el rango de valores es ligeramente más alto en enero y febrero, en comparación con otros meses.
Python3
# Splitting the plot into (1,2) subplots
# and initializing them using fig and ax
# variables
fig, ax = plt.subplots(nrows=1, ncols=2,
figsize=(15, 6))
# Using Seaborn Library for Box Plot
sns.boxplot(dataframe['Year'],
dataframe["A"], ax=ax[0])
# Defining the title and axes names
ax[0].set_title('Year-wise Box Plot for A',
fontsize=20, loc='center')
ax[0].set_xlabel('Year')
ax[0].set_ylabel('"A" values')
# Using Seaborn Library for Box Plot
sns.boxplot(dataframe['Month'],
dataframe["A"], ax=ax[1])
# Defining the title and axes names
ax[1].set_title('Month-wise Box Plot for A',
fontsize=20, loc='center')
ax[1].set_xlabel('Month')
ax[1].set_ylabel('"A" values')
# rotate the ticks and right align them
fig.autofmt_xdate()
Producción:
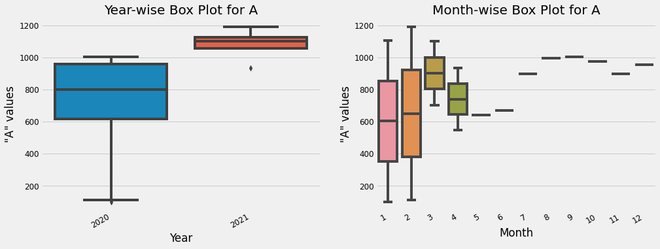
análisis de diagrama de caja de los valores de la columna ‘A’
Análisis de turnos:
Esta gráfica se logra dividiendo el valor actual de la columna ‘A’ por el valor desplazado de la columna ‘A’. El cambio predeterminado es por un valor. Este gráfico se utiliza para analizar la estabilidad del valor a diario.
Python3
dataframe['Change'] = dataframe.A.div(dataframe.A.shift()) dataframe['Change'].plot(figsize=(15, 10), xlabel = "Date", ylabel = "Value Difference", title = "Shift Plot")
Producción:
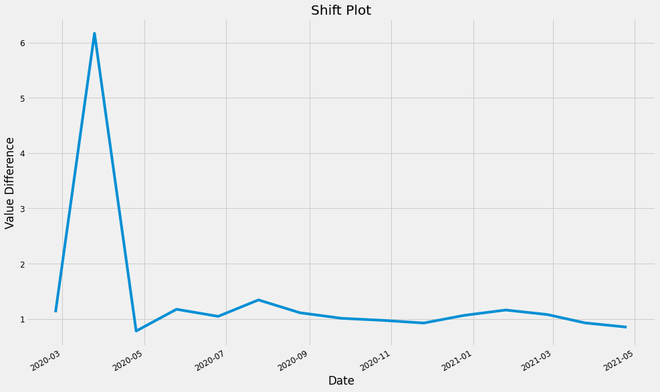
diagrama de desplazamiento de los valores ‘A’
Trazado de mapa de calor basado en series temporales:
Podemos interpretar la tendencia de los valores de la columna «A» a lo largo de los años muestreados durante 12 meses, la variación de valores a lo largo de diferentes años, etc. También podemos inferir cómo han cambiado los valores a partir del valor promedio. Este mapa de calor es una visualización realmente útil. Este mapa de calor muestra la variación de la temperatura entre años y meses, diferenciada mediante un mapa de colores.
Python3
import calendar
import seaborn as sns
import pandas as pd
dataframe['Date'] = dataframe.index
# Splitting the Date into Year and Month
dataframe['Year'] = dataframe['Date'].dt.year
dataframe['Month'] = dataframe['Date'].dt.month
# Creating a Pivot Table with "A"
# column values and is Month indexed.
table_df = pd.pivot_table(dataframe, values=["A"],
index=["Month"],
columns=["Year"],
fill_value=0,
margins=True)
# Naming the index, can be generated
# using calendar.month_abbr[i]
mon_name = [['Jan', 'Feb', 'Mar', 'Apr',
'May', 'Jun', 'Jul', 'Aug',
'Sep','Oct', 'Nov', 'Dec', 'All']]
# Indexing using Month Names
table_df = table_df.set_index(mon_name)
# Creating a heatmap using sns with Red,
# Yellow & Green Colormap.
ax = sns.heatmap(table_df, cmap='RdYlGn_r',
robust=True, fmt='.2f',
annot=True, linewidths=.6,
annot_kws={'size':10},
cbar_kws={'shrink':.5,
'label':'"A" values'})
# Setting the Tick Labels, Title and x & Y labels
ax.set_yticklabels(ax.get_yticklabels())
ax.set_xticklabels(ax.get_xticklabels())
plt.title('"A" Value Analysis', pad=14)
plt.xlabel('Year')
plt.ylabel('Months')
Producción:
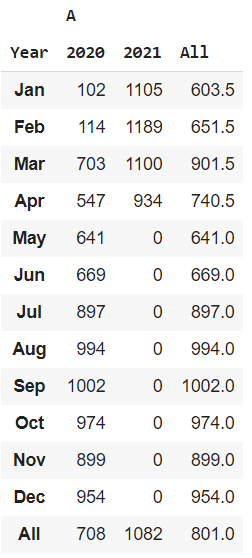
tabla de mapa de calor para la columna «A»
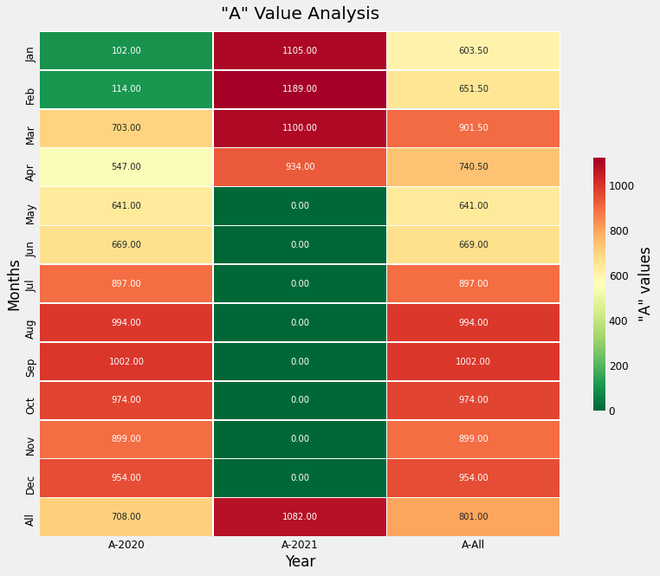
Gráfico de mapa de calor para los valores de la columna «A»
Publicación traducida automáticamente
Artículo escrito por therealnavzz y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA