Collect() es la función, operación para RDD o Dataframe que se utiliza para recuperar los datos del Dataframe. Se usa para recuperar todos los elementos de la fila de cada partición en un RDD y los lleva al programa/Node del controlador.
Entonces, en este artículo, vamos a aprender cómo recuperar los datos del marco de datos usando la operación de acción collect().
Sintaxis: df.collect()
Donde df es el marco de datos
Ejemplo 1: Recuperar todos los datos del marco de datos usando recopilar().
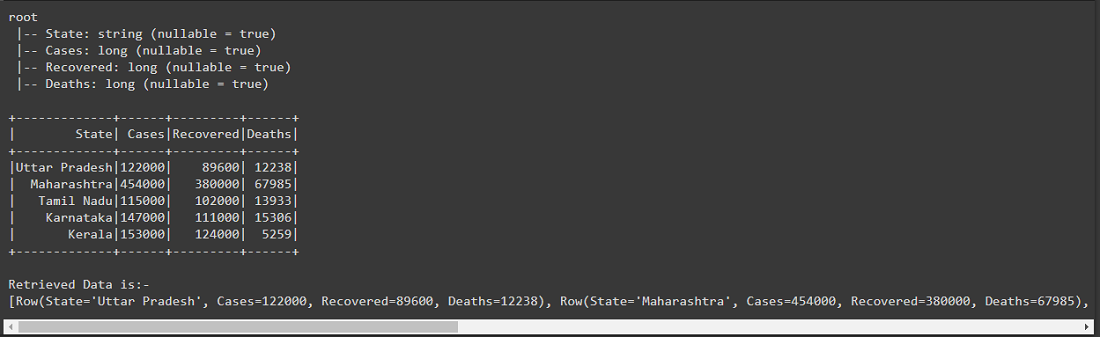
Después de crear el marco de datos, para recuperar todos los datos del marco de datos, hemos utilizado la acción recopilar() escribiendo df.collect(), esto devolverá el tipo de array de fila, en el siguiente resultado se muestra el esquema del marco de datos y el Marco de datos creado real.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.appName("Corona_cases_statewise.com") \
.getOrCreate()
return spk
# function to create RDD
def create_RDD(sc_obj,data):
df = sc.parallelize(data)
return df
if __name__ == "__main__":
input_data = [("Uttar Pradesh",122000,89600,12238),
("Maharashtra",454000,380000,67985),
("Tamil Nadu",115000,102000,13933),
("Karnataka",147000,111000,15306),
("Kerala",153000,124000,5259)]
# calling function to create SparkSession
spark = create_session()
# creating spark context object
sc = spark.sparkContext
# calling function to create RDD
rd_df = create_RDD(sc,input_data)
schema_lst = ["State","Cases","Recovered","Deaths"]
# creating the dataframe using createDataFrame function
df = spark.createDataFrame(rd_df,schema_lst)
# printing schema of the dataframe and showing the dataframe
df.printSchema()
df.show()
# retrieving the data from the dataframe using collect()
df2= df.collect()
print("Retrieved Data is:-")
print(df2)
Producción:
Ejemplo 2: Recuperación de datos de filas específicas usando collect().
Después de crear el marco de datos, recuperamos los datos del marco de datos de la fila 0 usando la acción de recopilar() escribiendo print (df.collect() [0] [0:]) respectivamente en esto estamos pasando fila y columna después de recopilar(), en la primera declaración de impresión hemos pasado fila y columna como [0][0:] aquí primero [0] representa la fila que hemos pasado 0 y segundo [0:] esto representa la columna y los dos puntos (:) se usan para recuperar todas las columnas, en resumen, hemos recuperado la fila 0 con todos los elementos de la columna.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.appName("Corona_cases_statewise.com") \
.getOrCreate()
return spk
# function to create RDD
def create_RDD(sc_obj,data):
df = sc.parallelize(data)
return df
if __name__ == "__main__":
input_data = [("Uttar Pradesh",122000,89600,12238),
("Maharashtra",454000,380000,67985),
("Tamil Nadu",115000,102000,13933),
("Karnataka",147000,111000,15306),
("Kerala",153000,124000,5259)]
# calling function to create SparkSession
spark = create_session()
# creating spark context object
sc = spark.sparkContext
# calling function to create RDD
rd_df = create_RDD(sc,input_data)
schema_lst = ["State","Cases","Recovered","Deaths"]
# creating the dataframe using createDataFrame function
df = spark.createDataFrame(rd_df,schema_lst)
# printing schema of the dataframe and showing the dataframe
df.printSchema()
df.show()
print("Retrieved Data is:-")
# Retrieving data from 0th row
print(df.collect()[0][0:])
Producción:

Ejemplo 3: Recuperar datos de múltiples filas usando collect().
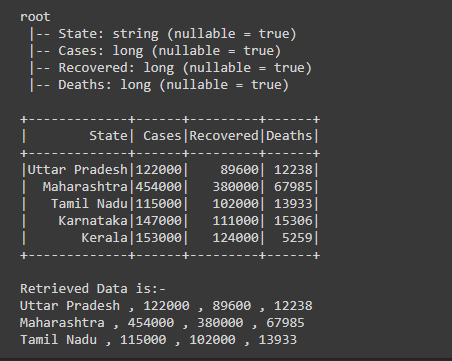
Después de crear el marco de datos, estamos recuperando los datos de las primeras tres filas del marco de datos usando la acción recopilar() con bucle for, escribiendo para la fila en df.collect() [0: 3] , después de escribir la acción recopilar() estamos pasando las filas de números que queremos [0: 3], primero [0] representa la fila inicial y usando «:» punto y coma y [3] representa la fila final hasta la cual queremos los datos de varias filas.
Aquí está el número de filas de las que estamos recuperando los datos es 0,1 y 2, el último índice siempre se excluye, es decir, 3.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.appName("Corona_cases_statewise.com") \
.getOrCreate()
return spk
# function to create RDD
def create_RDD(sc_obj,data):
df = sc.parallelize(data)
return df
if __name__ == "__main__":
input_data = [("Uttar Pradesh",122000,89600,12238),
("Maharashtra",454000,380000,67985),
("Tamil Nadu",115000,102000,13933),
("Karnataka",147000,111000,15306),
("Kerala",153000,124000,5259)]
# calling function to create SparkSession
spark = create_session()
# creating spark context object
sc = spark.sparkContext
# calling function to create RDD
rd_df = create_RDD(sc,input_data)
schema_lst = ["State","Cases","Recovered","Deaths"]
# creating the dataframe using createDataFrame function
df = spark.createDataFrame(rd_df,schema_lst)
# showing the dataframe and schema
df.printSchema()
df.show()
print("Retrieved Data is:-")
# Retrieving multiple rows using collect() and for loop
for row in df.collect()[0:3]:
print((row["State"]),",",str(row["Cases"]),",",
str(row["Recovered"]),",",str(row["Deaths"]))
Producción:
Ejemplo 4: recuperar datos de una columna específica usando collect().
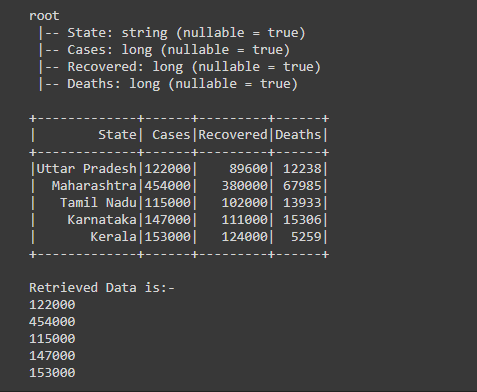
Después de crear el Dataframe, estamos recuperando los datos de la columna ‘Casos’ usando la acción collect() con for loop. Al iterar el ciclo a df.collect(), eso nos da la array de filas de esas filas que estamos recuperando e imprimiendo los datos de la columna ‘Casos’ escribiendo print(col[“Cases”]);
Como estamos obteniendo las filas uno iterando for loop desde Array of rows, de esa fila estamos recuperando los datos de la columna «Casos» solamente. Al escribir print(col[“Cases”]) aquí desde cada fila, estamos recuperando los datos de la columna ‘Casos’ al pasar ‘Casos’ en la col.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.appName("Corona_cases_statewise.com") \
.getOrCreate()
return spk
# function to create RDD
def create_RDD(sc_obj,data):
df = sc.parallelize(data)
return df
if __name__ == "__main__":
input_data = [("Uttar Pradesh",122000,89600,12238),
("Maharashtra",454000,380000,67985),
("Tamil Nadu",115000,102000,13933),
("Karnataka",147000,111000,15306),
("Kerala",153000,124000,5259)]
# calling function to create SparkSession
spark = create_session()
# creating spark context object
sc = spark.sparkContext
# calling function to create RDD
rd_df = create_RDD(sc,input_data)
schema_lst = ["State","Cases","Recovered","Deaths"]
# creating the dataframe using createDataFrame function
df = spark.createDataFrame(rd_df,schema_lst)
# showing the dataframe and schema
df.printSchema()
df.show()
print("Retrieved Data is:-")
# Retrieving data from the "Cases" column
for col in df.collect():
print(col["Cases"])
Producción:
Ejemplo 5: Recuperar los datos de múltiples columnas usando collect().
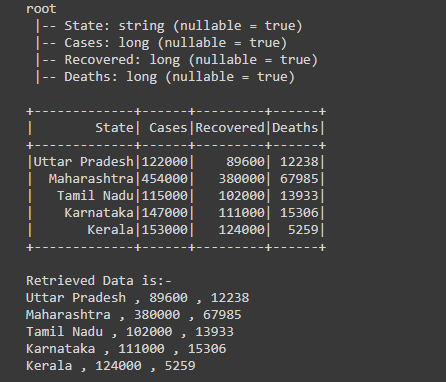
Después de crear el marco de datos, estamos recuperando los datos de varias columnas que incluyen «Estado», «Recuperado» y «Muertes».
Para recuperar los datos de varias columnas, primero tenemos que obtener la array de filas que obtenemos usando la acción df.collect() ahora iterar el ciclo for de cada fila de la array, ya que al iterar estamos obteniendo filas una por una, así que desde esa fila estamos recuperando los datos de las columnas «Estado», «Recuperado» y «Muertes» de cada columna e imprimiendo los datos escribiendo, print(col[«Estado»],»,»,col[«Recuperado»], «,»col[«Muertes»])
Python
# importing necessary libraries
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.appName("Corona_cases_statewise.com") \
.getOrCreate()
return spk
# function to create RDD
def create_RDD(sc_obj,data):
df = sc.parallelize(data)
return df
if __name__ == "__main__":
input_data = [("Uttar Pradesh",122000,89600,12238),
("Maharashtra",454000,380000,67985),
("Tamil Nadu",115000,102000,13933),
("Karnataka",147000,111000,15306),
("Kerala",153000,124000,5259)]
# calling function to create SparkSession
spark = create_session()
# creating spark context object
sc = spark.sparkContext
# calling function to create RDD
rd_df = create_RDD(sc,input_data)
schema_lst = ["State","Cases","Recovered","Deaths"]
# creating the dataframe using createDataFrame function
df = spark.createDataFrame(rd_df,schema_lst)
# showing the dataframe and schema
df.printSchema()
df.show()
print("Retrieved Data is:-")
# Retrieving data of the "State",
# "Recovered" and "Deaths" column
for col in df.collect():
print(col["State"],",",col["Recovered"],",
",col["Deaths"])
Producción:
Publicación traducida automáticamente
Artículo escrito por srishivansh5404 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA