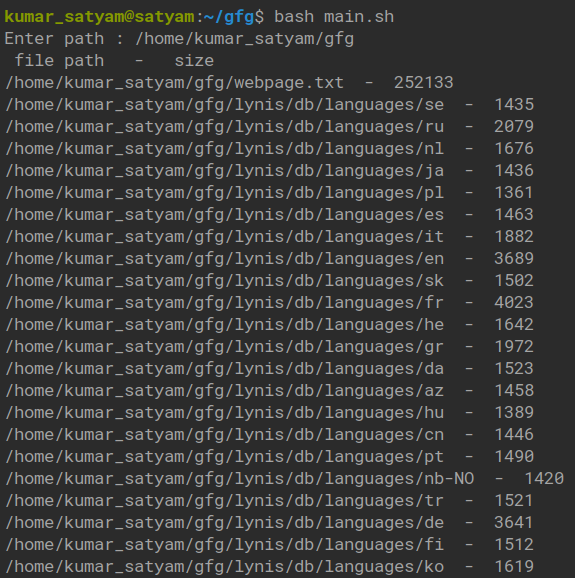
Debemos tener situaciones al menos una vez en las que necesitamos enumerar archivos para su tamaño particular, tal vez en bytes, kilobytes, etc., surge la necesidad de minimizar la tarea tediosa para ahorrar tiempo y concentrarse en las cosas requeridas. Así que necesitamos ciertas herramientas o scripts para hacer esto por nosotros, aquí es donde Linux y los scripts de shell realmente brillan. Es muy fácil hacer scripts de shell portátiles en Linux. Podemos hacer uso de algunas utilidades y herramientas de línea de comandos para que sea muy eficiente y fácil.
Aquí, debemos enumerar los archivos con tamaños superiores a 1000 bytes. Se pueden usar herramientas y utilidades como find, stat, etc. para ubicar y filtrar archivos y sistemas de archivos con mucho control y funcionalidad. Seguramente necesitamos incrustar estas herramientas en un script de shell junto con algunas declaraciones condicionales y de bucle básicas para que sea más programático y eficiente.
Acercarse
El enfoque de este script es bastante importante porque esa es la parte lógica real que va en la compilación, que es bastante sintáctica y teórica. Entonces necesitamos imprimir archivos con un límite de tamaño. Para eso, necesitamos iterar o recorrer la ruta o el directorio especificado para buscar archivos. Podemos usar el comando llamado find para recorrer la ruta de entrada. Ahora, para verificar el tamaño de los archivos, debemos usar un comando llamado stat para almacenar el tamaño de los archivos en el formato requerido (en este caso, bytes). Después de eso, una declaración condicional (si bloque) para verificar si el archivo cumple con las condiciones requeridas, en este caso, debe exceder 1000.
A continuación se muestra la implementación:
#!/bin/bash
read -p "Enter path : " -r filep
echo " file path - size "
for i in $(find "$filep" -depth);
do
size=$(stat -c%s "$i")
if [ $size -gt 1000 ]
then
echo $i " - " $size
fi
done