Para comprender cómo las variables en un conjunto de datos se relacionan entre sí y cómo esa relación depende de otras variables, realizamos un análisis estadístico. Este análisis estadístico ayuda a visualizar las tendencias e identificar varios patrones en el conjunto de datos. Una de las funciones que se pueden utilizar para obtener la relación entre dos variables en Seaborn es relplot().
Relplot() combina FacetGrid con cualquiera de las dos funciones de nivel de ejes scatterplot() y lineplot() . Scatterplot es el tipo predeterminado de relplot(). Usando esto podemos visualizar la distribución conjunta de dos variables a través de una nube de puntos. Podemos dibujar diagramas de dispersión en seaborn usando varias formas. El más común es cuando ambas variables son numéricas.
Ejemplo: Tomemos un ejemplo de un conjunto de datos que consta de datos de emisiones de CO2 de diferentes vehículos. Para obtener el conjunto de datos, haga clic aquí.
# import libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# set grid style
sns.set(style ="darkgrid")
# import dataset
dataset = pd.read_csv('FuelConsumption.csv')
Tracemos el diagrama de dispersión básico para visualizar la relación entre la variable objetivo «EMISIONES DE CO2» y «TAMAÑO DEL MOTOR»
sns.relplot(x ="ENGINESIZE", y ="CO2EMISSIONS", data = dataset);
Producción: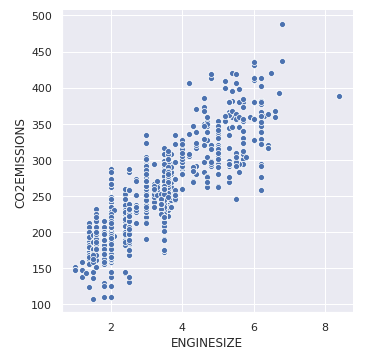
Podemos agregar visualizar una variable más agregando otra dimensión a la gráfica. Esto se puede hacer usando “tono”, que colorea los puntos de la tercera variable, añadiéndole así un significado.
sns.relplot(x ="ENGINESIZE", y ="CO2EMISSIONS", hue ="FUELTYPE", data = dataset);
Producción: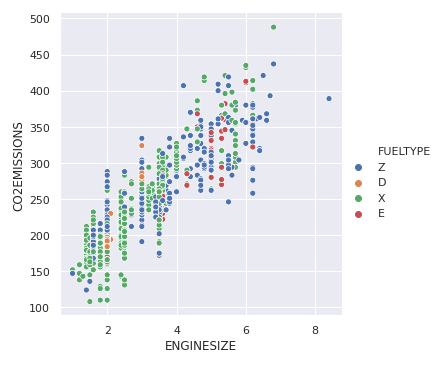
Para resaltar las diferentes clases, podemos agregar estilos de marcador
sns.relplot(x ="ENGINESIZE", y ="CO2EMISSIONS", hue ="FUELTYPE", style ="FUELTYPE", data = dataset);
Producción: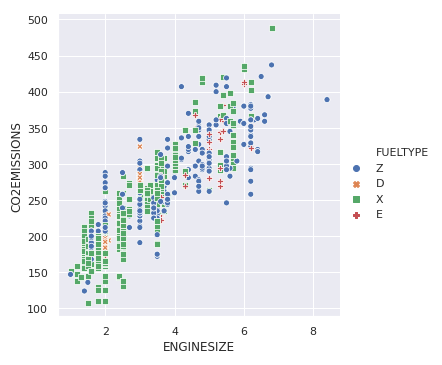
En el ejemplo anterior, la semántica de matiz era para una variable categórica, por lo que tenía una paleta cualitativa predeterminada. Pero si usamos una variable numérica en lugar de categórica, entonces la paleta predeterminada utilizada es secuencial, que también se puede modificar.
sns.relplot(x ="ENGINESIZE", y ="CO2EMISSIONS", hue ="CYLINDERS", data = dataset);
Producción: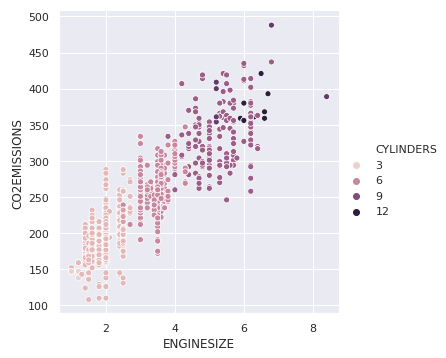
También podemos cambiar el tamaño de los puntos para la tercera variable.
sns.relplot(x ="ENGINESIZE", y ="CO2EMISSIONS", size ="CYLINDERS", data = dataset);
Producción: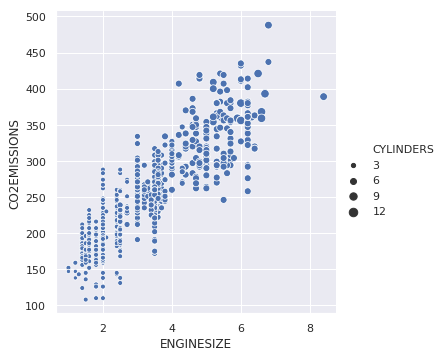
Publicación traducida automáticamente
Artículo escrito por devanshigupta1304 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA