Un cuantil es donde una muestra se divide en subgrupos adyacentes del mismo tamaño.
La mediana es un cuantil; la mediana se coloca en una distribución de probabilidad de modo que exactamente la mitad de los datos estén por debajo de la mediana y la mitad de los datos estén por encima de la mediana. La mediana corta una distribución en dos áreas iguales, por lo que a veces se denomina 2 cuantiles.
Los cuartiles también son cuantiles; dividen la distribución en cuatro partes iguales.
Los percentiles son cuantiles que dividen una distribución en 100 partes iguales y los deciles son cuantiles que dividen una distribución en 10 partes iguales.
Podemos usar la siguiente fórmula para estimar la i -ésima observación:
ith observation = q (n + 1)
donde q es el cuantil, la proporción por debajo del i -ésimo valor que está buscando
n es el número de elementos en un conjunto de datos.
Entonces, para encontrar el rango del Cuantil, q debe ser 0.25, ya que queremos dividir nuestro conjunto de datos en 4 partes iguales y clasificar los valores de 0 a 3 según el cuartil en el que se encuentran.
Y de manera similar para el rango de Decile, q debe ser 0.1 ya que queremos que nuestro conjunto de datos se divida en 10 partes iguales.
Antes de pasar a Pandas, probemos el concepto anterior en un ejemplo para comprender cómo se calculan nuestros rangos de cuantiles y deciles.
Ejemplo de pregunta: encuentre el número en el siguiente conjunto de datos donde el 25 por ciento de los valores se encuentran por debajo y el 75 por ciento por encima.
Datos: 32, 47, 55, 62, 74, 77, 86
Paso 1: Ordena los datos de menor a mayor. Los datos de la pregunta ya están en orden ascendente.
Paso 2: Cuente cuántas observaciones tiene en su conjunto de datos. este conjunto de datos en particular tiene 7 elementos.
Paso 3: Convierta cualquier porcentaje a un decimal para «q». Estamos buscando el número donde el 25 por ciento de los valores se encuentran por debajo de él, así que conviértalo a 0,25.
Paso 4: Inserta tus valores en la fórmula:
Responder:
i -ésima observación = q (n + 1)
i -ésima observación = .25(7 + 1) = 2
La i -ésima observación está en 2. El segundo número del conjunto es 47, que es el número donde el 25 por ciento de los valores se encuentran por debajo de él. Y luego podemos comenzar a clasificar nuestros números del 0 al 3, ya que estamos encontrando el rango cuantílico. Enfoque similar para encontrar el rango de deciles, en este caso es solo que el valor de q será 0.1.
Ahora veamos en Pandas cómo podemos lograr lo mismo rápidamente.
Código para crear un marco de datos:
python3
# Import pandas
import pandas as pd
# Create a DataFrame
df1 = {'Name':['George', 'Andrea', 'John', 'Helen',
'Ravi', 'Julia', 'Justin'],
'EnglishScore':[62, 47, 55, 74, 32, 77, 86]}
df1 = pd.DataFrame(df1, columns = ['Name', ''])
# Sorting the DataFrame in Ascending Order of English Score
df1.sort_values(by =['EnglishScore'], inplace = True)
Si imprimimos el marco de datos anterior, obtenemos el siguiente resultado:
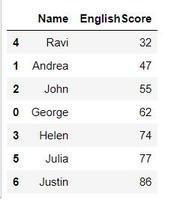
Marco de datos
Ahora podemos encontrar el rango de cuantiles usando la función pandas qcut() pasando el nombre de la columna que se considerará para el rango, el valor del parámetro q que significa el número de cuantiles. 10 para deciles, 4 para cuartiles, etc. y etiquetas = Falso para devolver los contenedores como enteros.
El siguiente es el código para el rango cuantil
python3
# code df1['QuantileRank']= pd.qcut(df1['EnglishScore'], q = 4, labels = False)
Y ahora, si imprimimos el marco de datos, podemos ver la nueva columna QauntileRank clasificando nuestros datos según la columna EnglishScore.
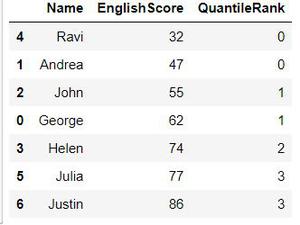
Rango cuantil
De manera similar, para calcular el rango de deciles establecemos q = 10
python3
# code df1['DecileRank']= pd.qcut(df1['EnglishScore'], q = 10, labels = False)
Ahora, si imprimimos nuestro DataFrame, obtenemos el siguiente resultado.
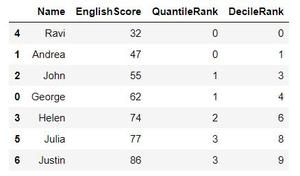
DecilRank
Así es como podemos usar el método qcut() de Pandas para calcular los diversos cuantiles en una columna.
El código completo para el ejemplo anterior se proporciona a continuación.
python3
# code
import pandas as pd
# Create a DataFrame
df1 = {'Name':['George', 'Andrea', 'John', 'Helen',
'Ravi', 'Julia', 'Justin'],
'EnglishScore':[62, 47, 55, 74, 32, 77, 86]}
df1 = pd.DataFrame(df1, columns =['Name', 'EnglishScore'])
# Sorting the DataFrame in Ascending Order of English Score
# Sorting just for the purpose of better data readability.
df1.sort_values(by =['EnglishScore'], inplace = True)
# Calculating Quantile Rank
df1['QuantileRank']= pd.qcut(df1['EnglishScore'], q = 4, labels = False)
# Calculating Decile Rank
df1['DecileRank'] = pd.qcut(df1['EnglishScore'], q = 10, labels = False)
# printing the dataframe
print(df1)
Publicación traducida automáticamente
Artículo escrito por Amrinder Singh Bedi y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA