La función PySpark Window realiza operaciones estadísticas como rango, número de fila, etc. en un grupo, marco o colección de filas y devuelve resultados para cada fila individualmente. También está creciendo popularmente para realizar transformaciones de datos. Comprenderemos el concepto de funciones de ventana, la sintaxis y, finalmente, cómo usarlas con PySpark SQL y PySpark DataFrame API.
Hay principalmente tres tipos de función de ventana:
- función analítica
- Función de clasificación
- Función agregada
Para realizar la operación de la función de ventana en un grupo de filas primero, necesitamos particionar, es decir, definir el grupo de filas de datos usando la función window.partition(), y para el número de fila y la función de rango, necesitamos ordenar adicionalmente por datos de partición usando ORDER BY cláusula.
Sintaxis para Window.partition:
Window.partitionBy(“nombre_columna”).orderBy(“nombre_columna”)
Sintaxis para la función de ventana:
DataFrame.withColumn(“new_col_name”, Window_function().over(Window_partition))
Comprendamos e implementemos todas estas funciones una por una con ejemplos.
Funciones analíticas
Una función analítica es una función que devuelve un resultado después de operar con datos o un conjunto finito de filas divididas por una cláusula SELECT o en la cláusula ORDER BY. Devuelve un resultado en el mismo número de filas que el número de filas de entrada. Por ejemplo, lead(), lag(), cume_dist().
Creando dataframe para demostración:
Antes de comenzar con estas funciones, primero debemos crear un DataFrame. Crearemos un DataFrame que contenga detalles de los empleados como Employee_Name, Age, Department, Salary. Después de crear el DataFrame, aplicaremos cada función analítica en este DataFrame df.
Python3
# importing pyspark
from pyspark.sql.window import Window
import pyspark
# importing sparksessio
from pyspark.sql import SparkSession
# creating a sparksession object
# and providing appName
spark = SparkSession.builder.appName("pyspark_window").getOrCreate()
# sample data for dataframe
sampleData = (("Ram", 28, "Sales", 3000),
("Meena", 33, "Sales", 4600),
("Robin", 40, "Sales", 4100),
("Kunal", 25, "Finance", 3000),
("Ram", 28, "Sales", 3000),
("Srishti", 46, "Management", 3300),
("Jeny", 26, "Finance", 3900),
("Hitesh", 30, "Marketing", 3000),
("Kailash", 29, "Marketing", 2000),
("Sharad", 39, "Sales", 4100)
)
# column names for dataframe
columns = ["Employee_Name", "Age",
"Department", "Salary"]
# creating the dataframe df
df = spark.createDataFrame(data=sampleData,
schema=columns)
# importing Window from pyspark.sql.window
# creating a window
# partition of dataframe
windowPartition = Window.partitionBy("Department").orderBy("Age")
# print schema
df.printSchema()
# show df
df.show()
Producción:
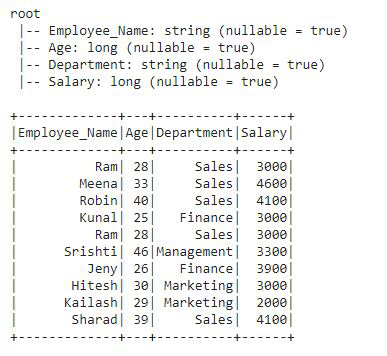
Este es el DataFrame sobre el que aplicaremos todas las funciones analíticas.
Ejemplo 1: Uso de cume_dist()
La función de ventana cume_dist() se utiliza para obtener la distribución acumulativa dentro de una partición de ventana. Es similar a CUME_DIST en SQL. Veamos un ejemplo:
Python3
# importing cume_dist()
# from pyspark.sql.functions
from pyspark.sql.functions import cume_dist
# applying window function with
# the help of DataFrame.withColumn
df.withColumn("cume_dist",
cume_dist().over(windowPartition)).show()
Producción:
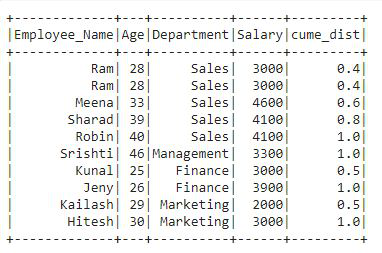
En la salida, podemos ver que se agrega una nueva columna al df llamada «cume_dist» que contiene la distribución acumulada de la columna Departamento que está ordenada por la columna Edad.
Ejemplo 2: Usar lag()
Se utiliza una función lag() para acceder a los datos de las filas anteriores según el valor de desplazamiento definido en la función. Esta función es similar al LAG en SQL.
Python3
# importing lag() from pyspark.sql.functions
from pyspark.sql.functions import lag
df.withColumn("Lag", lag("Salary", 2).over(windowPartition)) \
.show()
Producción:
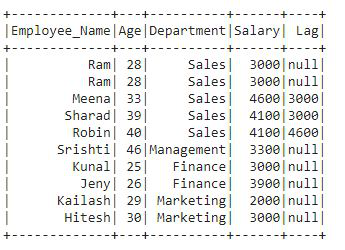
En la salida, podemos ver que la columna de retraso se agrega al df que contiene valores de retraso. En las primeras 2 filas hay un valor nulo como hemos definido el desplazamiento 2 seguido de la columna Salario en la función lag(). Las siguientes filas contienen los valores de las filas anteriores.
Ejemplo 3: Usar lead()
Se utiliza una función lead() para acceder a los datos de las siguientes filas según el valor de compensación definido en la función. Esta función es similar a LEAD en SQL y justo opuesta a la función lag() o LAG en SQL.
Python3
# importing lead() from pyspark.sql.functions
from pyspark.sql.functions import lead
df.withColumn("Lead", lead("salary", 2).over(windowPartition)) \
.show()
Producción:
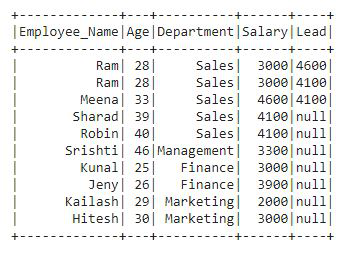
Función de clasificación
La función devuelve el rango estadístico de un valor dado para cada fila en una partición o grupo. El objetivo de esta función es proporcionar una numeración consecutiva de las filas en la columna resultante, establecida por el orden seleccionado en Window.partition para cada partición especificada en la cláusula OVER. Por ejemplo, número_fila(), range(), rango_denso(), etc.
Creando Dataframe para demostración:
Antes de comenzar con estas funciones, primero debemos crear un DataFrame. Crearemos un DataFrame que contenga detalles del estudiante como Roll_No, Student_Name, Subject, Marks. Después de crear el DataFrame, aplicaremos cada función de clasificación en este DataFrame df2.
Python3
# importing pyspark
from pyspark.sql.window import Window
import pyspark
# importing sparksessio
from pyspark.sql import SparkSession
# creating a sparksession object and providing appName
spark = SparkSession.builder.appName("pyspark_window").getOrCreate()
# sample data for dataframe
sampleData = ((101, "Ram", "Biology", 80),
(103, "Meena", "Social Science", 78),
(104, "Robin", "Sanskrit", 58),
(102, "Kunal", "Phisycs", 89),
(101, "Ram", "Biology", 80),
(106, "Srishti", "Maths", 70),
(108, "Jeny", "Physics", 75),
(107, "Hitesh", "Maths", 88),
(109, "Kailash", "Maths", 90),
(105, "Sharad", "Social Science", 84)
)
# column names for dataframe
columns = ["Roll_No", "Student_Name", "Subject", "Marks"]
# creating the dataframe df
df2 = spark.createDataFrame(data=sampleData,
schema=columns)
# importing window from pyspark.sql.window
# creating a window partition of dataframe
windowPartition = Window.partitionBy("Subject").orderBy("Marks")
# print schema
df2.printSchema()
# show df
df2.show()
Producción:
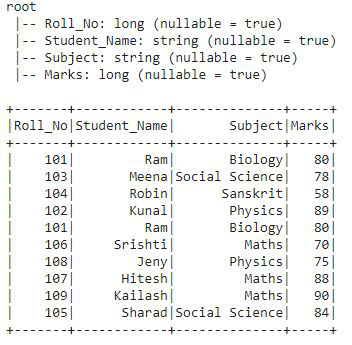
Este es el DataFrame df2 en el que aplicaremos todas las funciones de clasificación de ventanas.
Ejemplo 1: Usando número_fila().
La función row_number() se usa para dar un número secuencial a cada fila presente en la tabla. Veamos el ejemplo:
Python3
# importing row_number() from pyspark.sql.functions
from pyspark.sql.functions import row_number
# applying the row_number() function
df2.withColumn("row_number",
row_number().over(windowPartition)).show()
Producción:
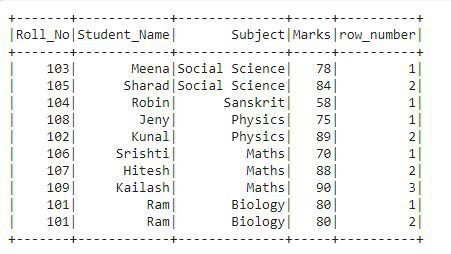
En este resultado, podemos ver que tenemos el número de fila para cada fila según la partición especificada, es decir, los números de fila se dan seguidos de la columna Asunto y Marcas.
Ejemplo 2: Uso de range()
La función de rango se usa para otorgar rangos a las filas especificadas en la partición de la ventana. Esta función deja huecos en el rango si hay empates. Veamos el ejemplo:
Python3
# importing rank() from pyspark.sql.functions
from pyspark.sql.functions import rank
# applying the rank() function
df2.withColumn("rank", rank().over(windowPartition)) \
.show()
Producción:
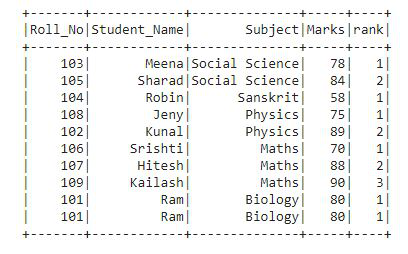
En el resultado, el rango se proporciona a cada fila según la columna Asunto y Marcas como se especifica en la partición de la ventana.
Ejemplo 3: Uso de percent_rank()
Esta función es similar a la función rank(). También proporciona rango a las filas pero en formato de percentil. Veamos el ejemplo:
Python3
# importing percent_rank() from pyspark.sql.functions
from pyspark.sql.functions import percent_rank
# applying the percent_rank() function
df2.withColumn("percent_rank",
percent_rank().over(windowPartition)).show()
Producción:
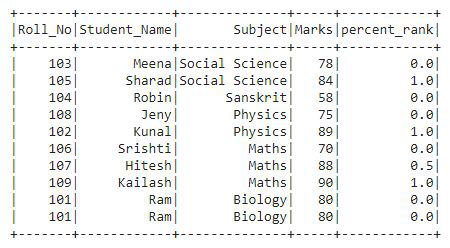
Podemos ver que en la salida, la columna de clasificación contiene valores en forma de percentil, es decir, en formato decimal.
Ejemplo 4: Usar dense_rank()
Esta función se utiliza para obtener el rango de cada fila en forma de números de fila. Esto es similar a la función de range(), solo hay una diferencia: la función de rango deja espacios en el rango cuando hay empates. Veamos el ejemplo:
Python3
# importing dense_rank() from pyspark.sql.functions
from pyspark.sql.functions import dense_rank
# applying the dense_rank() function
df2.withColumn("dense_rank",
dense_rank().over(windowPartition)).show()
Producción:
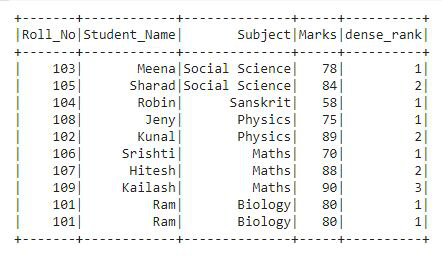
En la salida, podemos ver que los rangos se dan en forma de números de fila.
Función agregada
Una función agregada o función de agregación es una función en la que los valores de varias filas se agrupan para formar un solo valor de resumen. La definición de los grupos de filas sobre los que operan se realiza mediante la cláusula SQL GROUP BY. Por ejemplo, PROMEDIO, SUMA, MIN, MAX, etc.
Creando Dataframe para demostración:
Antes de comenzar con estas funciones, crearemos un nuevo DataFrame que contenga detalles de empleados como Employee_Name, Department y Salary. Después de crear el DataFrame, aplicaremos cada función Agregada en este DataFrame.
Python3
# importing pyspark
import pyspark
# importing sparksessio
from pyspark.sql import SparkSession
# creating a sparksession
# object and providing appName
spark = SparkSession.builder.appName("pyspark_window").getOrCreate()
# sample data for dataframe
sampleData = (("Ram", "Sales", 3000),
("Meena", "Sales", 4600),
("Robin", "Sales", 4100),
("Kunal", "Finance", 3000),
("Ram", "Sales", 3000),
("Srishti", "Management", 3300),
("Jeny", "Finance", 3900),
("Hitesh", "Marketing", 3000),
("Kailash", "Marketing", 2000),
("Sharad", "Sales", 4100)
)
# column names for dataframe
columns = ["Employee_Name", "Department", "Salary"]
# creating the dataframe df
df3 = spark.createDataFrame(data=sampleData,
schema=columns)
# print schema
df3.printSchema()
# show df
df3.show()
Producción:
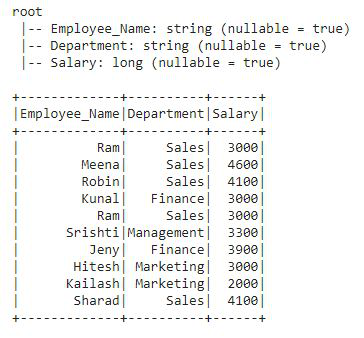
Este es el DataFrame df3 sobre el que aplicaremos todas las funciones de agregado.
Ejemplo: Veamos cómo aplicar las funciones agregadas con este ejemplo
Python3
# importing window from pyspark.sql.window
from pyspark.sql.window import Window
# importing aggregate functions
# from pyspark.sql.functions
from pyspark.sql.functions import col,avg,sum,min,max,row_number
# creating a window partition of dataframe
windowPartitionAgg = Window.partitionBy("Department")
# applying window aggregate function
# to df3 with the help of withColumn
# this is average()
df3.withColumn("Avg",
avg(col("salary")).over(windowPartitionAgg))
#this is sum()
.withColumn("Sum",
sum(col("salary")).over(windowPartitionAgg))
#this is min()
.withColumn("Min",
min(col("salary")).over(windowPartitionAgg))
#this is max()
.withColumn("Max",
max(col("salary")).over(windowPartitionAgg)).show()
Producción:
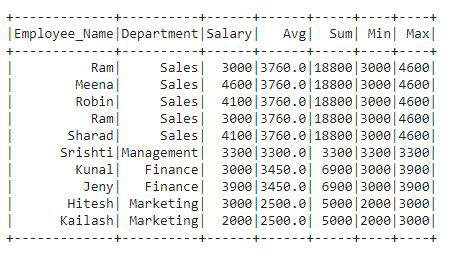
En la salida df, podemos ver que hay cuatro nuevas columnas agregadas a df. En el código, hemos aplicado las cuatro funciones agregadas una por una. Tenemos cuatro columnas de salida agregadas al df3 que contiene valores para cada fila. Estas cuatro columnas contienen los valores Promedio, Suma, Mínimo y Máximo de la columna Salario.
Publicación traducida automáticamente
Artículo escrito por neelutiwari y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA