En un gráfico conectado, la centralidad de cercanía (o cercanía) de un Node es una medida de centralidad en una red, calculada como la suma de la longitud de los caminos más cortos entre el Node y todos los demás Nodes en el gráfico. Por lo tanto, cuanto más central es un Node, más cerca está de todos los demás Nodes.
La cercanía fue definida por Bavelas (1950) como el recíproco de la lejanía, es decir:
 .
.
where  is the distance between vertices
is the distance between vertices  and
and  . When speaking of closeness centrality, people usually refer to its normalized form which represents the average length of the shortest paths instead of their sum. It is generally given by the previous formula multiplied by
. When speaking of closeness centrality, people usually refer to its normalized form which represents the average length of the shortest paths instead of their sum. It is generally given by the previous formula multiplied by  , where
, where  is the number of nodes in the graph. For large graphs this difference becomes inconsequential so the
is the number of nodes in the graph. For large graphs this difference becomes inconsequential so the  is dropped resulting in:
is dropped resulting in:
 .
.
This adjustment allows comparisons between nodes of graphs of different sizes.
Tomar distancias desde o hacia todos los demás Nodes es irrelevante en gráficos no dirigidos, mientras que puede producir resultados totalmente diferentes en gráficos dirigidos (por ejemplo, un sitio web puede tener una centralidad de cercanía alta del enlace saliente, pero una centralidad de cercanía baja de los enlaces entrantes).
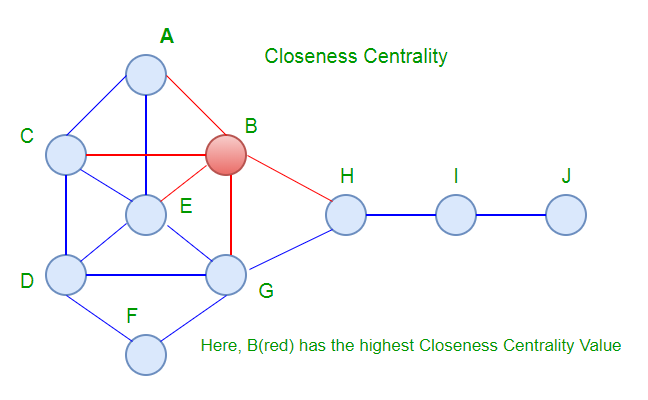
En grafos inconexos
Cuando un grafo no es fuertemente conexo, una idea muy extendida es la de utilizar la suma del recíproco de distancias, en lugar del recíproco de la suma de distancias, con la convención  :
:
 .
.
The most natural modification of Bavelas’s definition of closeness is following the general principle proposed by Marchiori and Latora (2000) that in graphs with infinite distances the harmonic mean behaves better than the arithmetic mean. Indeed, Bavelas’s closeness can be described as the denormalized reciprocal of the arithmetic mean of distances, whereas harmonic centrality is the denormalized reciprocal of the harmonic mean of distances.
Esta idea fue enunciada explícitamente para grafos no dirigidos bajo el nombre de centralidad valorada por Dekker (2005) y bajo el nombre de centralidad armónica por Rochat (2009), axiomatizada por Garg (2009) y propuesta nuevamente más tarde por Opsahl (2010). Fue estudiado en grafos generales dirigidos por Boldi y Vigna (2014). Esta idea también es bastante similar al potencial de mercado propuesto en Harris (1954), que ahora suele denominarse acceso al mercado.
Variantes
Dangalchev (2006), en un trabajo sobre vulnerabilidad de redes, propone para grafos no dirigidos una definición diferente:

This definition is used effectively for disconnected graphs and allows to create convenient formulae for graph operations. For example if a graph  is created by linking node p of graph
is created by linking node p of graph  to node
to node  of graph
of graph  then the combine closeness is:
then the combine closeness is:

The information centrality of Stephenson and Zelen (1989) is another closeness measure, which computes the harmonic mean of the resistance distances towards a vertex x, which is smaller if x has many paths of small resistance connecting it to other vertices.
En la definición clásica de la centralidad de cercanía, la difusión de la información se modela mediante el uso de caminos más cortos. Es posible que este modelo no sea el más realista para todos los tipos de escenarios de comunicación. Por lo tanto, se han discutido definiciones relacionadas para medir la cercanía, como la centralidad de cercanía de paseo aleatorio introducida por Noh y Rieger (2004). Mide la velocidad con la que los mensajes que caminan aleatoriamente alcanzan un vértice desde otra parte del gráfico, una especie de versión aleatoria de la centralidad de la cercanía. La cercanía jerárquica de Tran y Kwon (2014) es una centralidad de cercanía extendida para tratar de otra manera la limitación de la cercanía en grafos que no están fuertemente conectados. La cercanía jerárquica incluye explícitamente información sobre el rango de otros Nodes que pueden verse afectados por el Node dado.
A continuación se muestra el código para el cálculo de la Centralidad de Cercanía del grafo y sus diversos Nodes.
def closeness_centrality(G, u=None, distance=None, normalized=True):
r"""Compute closeness centrality for nodes.
Closeness centrality [1]_ of a node `u` is the reciprocal of the
sum of the shortest path distances from `u` to all `n-1` other nodes.
Since the sum of distances depends on the number of nodes in the
graph, closeness is normalized by the sum of minimum possible
distances `n-1`.
.. math::
C(u) = \frac{n - 1}{\sum_{v=1}^{n-1} d(v, u)},
where `d(v, u)` is the shortest-path distance between `v` and `u`,
and `n` is the number of nodes in the graph.
Notice that higher values of closeness indicate higher centrality.
Parameters
----------
G : graph
A NetworkX graph
u : node, optional
Return only the value for node u
distance : edge attribute key, optional (default=None)
Use the specified edge attribute as the edge distance in shortest
path calculations
normalized : bool, optional
If True (default) normalize by the number of nodes in the connected
part of the graph.
Returns
-------
nodes : dictionary
Dictionary of nodes with closeness centrality as the value.
See Also
--------
betweenness_centrality, load_centrality, eigenvector_centrality,
degree_centrality
Notes
-----
The closeness centrality is normalized to `(n-1)/(|G|-1)` where
`n` is the number of nodes in the connected part of graph
containing the node. If the graph is not completely connected,
this algorithm computes the closeness centrality for each
connected part separately.
If the 'distance' keyword is set to an edge attribute key then the
shortest-path length will be computed using Dijkstra's algorithm with
that edge attribute as the edge weight.
"""
if distance is not None:
# use Dijkstra's algorithm with specified attribute as edge weight
path_length = functools.partial(nx.single_source_dijkstra_path_length,
weight=distance)
else:
path_length = nx.single_source_shortest_path_length
if u is None:
nodes = G.nodes()
else:
nodes = [u]
closeness_centrality = {}
for n in nodes:
sp = path_length(G,n)
totsp = sum(sp.values())
if totsp > 0.0 and len(G) > 1:
closeness_centrality[n] = (len(sp)-1.0) / totsp
# normalize to number of nodes-1 in connected part
if normalized:
s = (len(sp)-1.0) / ( len(G) - 1 )
closeness_centrality[n] *= s
else:
closeness_centrality[n] = 0.0
if u is not None:
return closeness_centrality[u]
else:
return closeness_centrality
La función anterior se invoca usando la biblioteca networkx y una vez que la biblioteca está instalada, eventualmente puede usarla y el siguiente código debe escribirse en python para la implementación de la centralidad de cercanía de un Node.
import networkx as nx G=nx.erdos_renyi_graph(100,0.6) c=nx.closeness_centrality(G) print(c)
La salida del código anterior es:
{0: 0.6971830985915493, 1: 0.7122302158273381, 2: 0.6875, 3: 0.7021276595744681,
4: 0.7443609022556391, 5: 0.7388059701492538, 6: 0.7071428571428572, 7: 0.7388059701492538,
8: 0.7388059701492538, 9: 0.7226277372262774, 10: 0.6923076923076923, 11: 0.7021276595744681,
12: 0.7388059701492538, 13: 0.6923076923076923, 14: 0.7279411764705882, 15: 0.6644295302013423,
16: 0.7333333333333333, 17: 0.7388059701492538, 18: 0.7122302158273381, 19: 0.678082191780822,
20: 0.6923076923076923, 21: 0.717391304347826, 22: 0.6923076923076923, 23: 0.7071428571428572,
24: 0.7333333333333333, 25: 0.717391304347826, 26: 0.7734375, 27: 0.7071428571428572,
28: 0.7557251908396947, 29: 0.7279411764705882, 30: 0.717391304347826, 31: 0.7122302158273381,
32: 0.7122302158273381, 33: 0.7226277372262774, 34: 0.6827586206896552, 35: 0.7021276595744681,
36: 0.7122302158273381, 37: 0.673469387755102, 38: 0.75, 39: 0.7071428571428572,
40: 0.7333333333333333, 41: 0.717391304347826, 42: 0.7071428571428572, 43: 0.6875,
44: 0.7615384615384615, 45: 0.7226277372262774, 46: 0.7857142857142857, 47: 0.7388059701492538,
48: 0.7333333333333333, 49: 0.717391304347826, 50: 0.7021276595744681, 51: 0.7071428571428572,
52: 0.717391304347826, 53: 0.7333333333333333, 54: 0.717391304347826, 55: 0.7388059701492538,
56: 0.7021276595744681, 57: 0.7557251908396947, 58: 0.6971830985915493, 59: 0.7795275590551181,
60: 0.7122302158273381, 61: 0.7388059701492538, 62: 0.717391304347826, 63: 0.6923076923076923,
64: 0.7071428571428572, 65: 0.7021276595744681, 66: 0.7021276595744681, 67: 0.7021276595744681,
68: 0.7388059701492538, 69: 0.7333333333333333, 70: 0.6923076923076923, 71: 0.75,
72: 0.7557251908396947, 73: 0.7443609022556391, 74: 0.7388059701492538, 75: 0.7388059701492538,
76: 0.6346153846153846, 77: 0.7071428571428572, 78: 0.7226277372262774, 79: 0.7674418604651163,
80: 0.7071428571428572, 81: 0.7279411764705882, 82: 0.678082191780822, 83: 0.7333333333333333,
84: 0.7443609022556391, 85: 0.6923076923076923, 86: 0.7122302158273381, 87: 0.7333333333333333,
88: 0.7279411764705882, 89: 0.7122302158273381, 90: 0.7122302158273381, 91: 0.7557251908396947,
92: 0.7388059701492538, 93: 0.7021276595744681, 94: 0.6513157894736842, 95: 0.673469387755102,
96: 0.7122302158273381, 97: 0.717391304347826, 98: 0.7021276595744681, 99: 0.7388059701492538}
El resultado anterior es un diccionario que representa el valor de la centralidad de proximidad de cada Node. Lo anterior es una extensión de mi serie de artículos sobre las medidas de centralidad. Sigan haciendo networking!!!
Referencias
Puede leer más sobre el mismo en
https://en.wikipedia.org/wiki/Closeness_centrality
http://networkx.readthedocs.io/en/networkx-1.10/index.html
Publicación traducida automáticamente
Artículo escrito por Jayant Bisht y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA