Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
La función Pandas dataframe.reindex_like()devuelve un objeto con índices coincidentes para mí. Los índices que no coinciden se rellenan con NaNvalores.
Sintaxis:
Sintaxis: DataFrame.reindex_like(otro, método=Ninguno, copia=Verdadero, límite=Ninguno, tolerancia=Ninguno)Parámetros:
otro:
método de objeto : string o
copia de ninguno: booleano, predeterminado
Límite verdadero: número máximo de etiquetas consecutivas para completar las coincidencias inexactas.
tolerancia : Distancia máxima entre las etiquetas del otro objeto y este objeto para coincidencias inexactas. Puede ser como una lista.Devoluciones: reindexado: igual que la entrada
Ejemplo #1: Use reindex_like()la función para encontrar los índices coincidentes entre los dos marcos de datos dados.
Nota: podemos completar los valores que faltan utilizando cualquiera de los métodos de relleno (p. ej., ‘ffill’, ‘bfill’).
# importing pandas as pd
import pandas as pd
# Creating the first dataframe
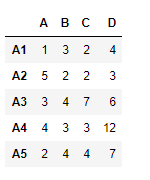
df1 = pd.DataFrame({"A":[1, 5, 3, 4, 2],
"B":[3, 2, 4, 3, 4],
"C":[2, 2, 7, 3, 4],
"D":[4, 3, 6, 12, 7]},
index =["A1", "A2", "A3", "A4", "A5"])
# Creating the second dataframe
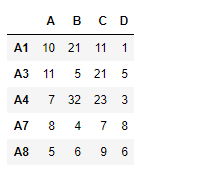
df2 = pd.DataFrame({"A":[10, 11, 7, 8, 5],
"B":[21, 5, 32, 4, 6],
"C":[11, 21, 23, 7, 9],
"D":[1, 5, 3, 8, 6]},
index =["A1", "A3", "A4", "A7", "A8"])
# Print the first dataframe
df1
# Print the second dataframe
df2
Usemos la dataframe.reindex_like()función para encontrar los índices coincidentes.
# find matching indexes df1.reindex_like(df2)
Producción :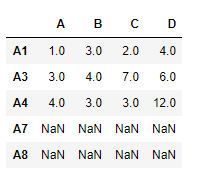
Observe la salida, los índices no coincidentes se rellenan con NaNvalores, podemos completar los valores faltantes usando el método ‘rellenar’.
# filling the missing values using ffill method df1.reindex_like(df2, method ='ffill')
Salida: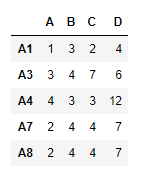
observe en la salida, los nuevos índices se han rellenado utilizando la fila «A5».
Ejemplo n.º 2: use reindex_like()la función para hacer coincidir los índices de dos marcos de datos con límite para completar los valores faltantes.
# importing pandas as pd
import pandas as pd
# Creating the first dataframe
df1 = pd.DataFrame({"A":[1, 5, 3, 4, 2],
"B":[3, 2, 4, 3, 4],
"C":[2, 2, 7, 3, 4],
"D":[4, 3, 6, 12, 7]},
index =["A1", "A2", "A3", "A4", "A5"])
# Creating the second dataframe
df2 = pd.DataFrame({"A":[10, 11, 7, 8, 5],
"B":[21, 5, 32, 4, 6],
"F":[11, 21, 23, 7, 9],
"K":[1, 5, 3, 8, 6]},
index =["A1", "A2", "A3", "A4", "A7"])
# matching the indexes
df1.reindex_like(df2)
Salida: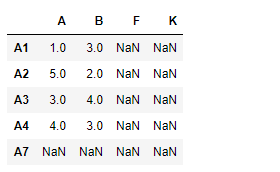
observe la salida, los índices no coincidentes se rellenan con NaNvalores, podemos completar los valores faltantes usando el método ‘rellenar’. también limitamos la cantidad de índices consecutivos no coincidentes que se pueden completar con el parámetro de límite.
# match the indexes # fill the unmatched index using 'ffill' method # maximum consecutive unmatched indexes to be filled is 1 df.reindex_like(df1, method ='ffill', limit = 1)
Producción :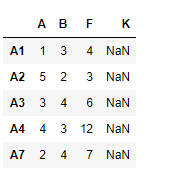
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA