Un cuadro de información es una plantilla que se utiliza para recopilar y presentar un subconjunto de información sobre su tema. Puede describirse como un documento estructurado que contiene un conjunto de pares atributo-valor y, en Wikipedia , representa un resumen de información sobre el tema de un artículo.
Entonces, un cuadro de información de Wikipedia es una tabla de formato fijo que generalmente se agrega a la esquina superior derecha de los artículos para representar un artículo de resumen de esa página wiki y, a veces, para mejorar la navegación a otros artículos interrelacionados.
[Para saber más sobre infobox, haga clic aquí ]
Web Scrapinges un mecanismo que ayuda a extraer grandes cantidades de datos de sitios web mediante el cual los datos se extraen y guardan en un archivo local en su computadora o en una base de datos en formato de tabla (hoja de cálculo).
Hay varias formas de extraer información de la web. El uso de API es una de las mejores formas de extraer datos de un sitio web. Casi todos los sitios web grandes como Youtube, Facebook, Google, Twitter, StackOverflow proporcionan API para acceder a sus datos de una manera más estructurada. Si puede obtener lo que necesita a través de una API, casi siempre se prefiere el enfoque rojo sobre el web scraping.
A veces, existe la necesidad de raspar el contenido de una página de Wikipedia, mientras estamos desarrollando cualquier proyecto o usándolo en otro lugar. En este artículo, te diré cómo extraer contenido del Infobox de Wikipedia.
Básicamente, podemos usar dos módulos de Python para raspar datos:
Urllib2 : es un módulo de Python que se puede usar para obtener URL. urllib2 es un módulo de Python para obtener URL. Ofrece una interfaz muy simple, en forma de función urlopen. Esto es capaz de obtener URL utilizando una variedad de protocolos diferentes. Para obtener más detalles, consulte la página de documentación .
BeautifulSoup : Es una herramienta increíble para extraer información de una página web. Puedes usarlo para extraer tablas, listas, párrafos y también puedes poner filtros para extraer información de páginas web. Mire la página de documentación de BeautifulSoup
BeautifulSoup no obtiene la página web para nosotros. Podemos usar urllib2 con la biblioteca BeautifulSoup.
Ahora les voy a decir otra manera fácil de raspar
Pasos para lo siguiente:
Los módulos que usaremos son:
He usado Python 2.7 aquí,
asegúrese de que estos módulos estén instalados en su máquina.
Si no es así, en la consola o en el indicador, puede instalarlo usando pip
Python
# importing modules
import requests
from lxml import etree
# manually storing desired URL
url='https://en.wikipedia.org/wiki/Delhi_Public_School_Society'
# fetching its url through requests module
req = requests.get(url)
store = etree.fromstring(req.text)
# this will give Motto portion of above
# URL's info box of Wikipedia's page
output = store.xpath('//table[@class="infobox vcard"]/tr[th/text()="Motto"]/td/i')
# printing the text portion
print output[0].text
# Run this program on your installed Python or
# on your local system using cmd or any IDE.
Vea este enlace, mostrará la ‘Sección de lema’ de este cuadro de información de la página de Wikipedia (como se muestra en esta captura de pantalla)
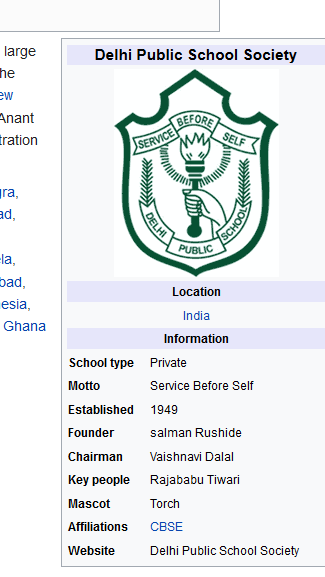

Primero escribe tu código
Ahora, finalmente, después de ejecutar el programa obtienes,
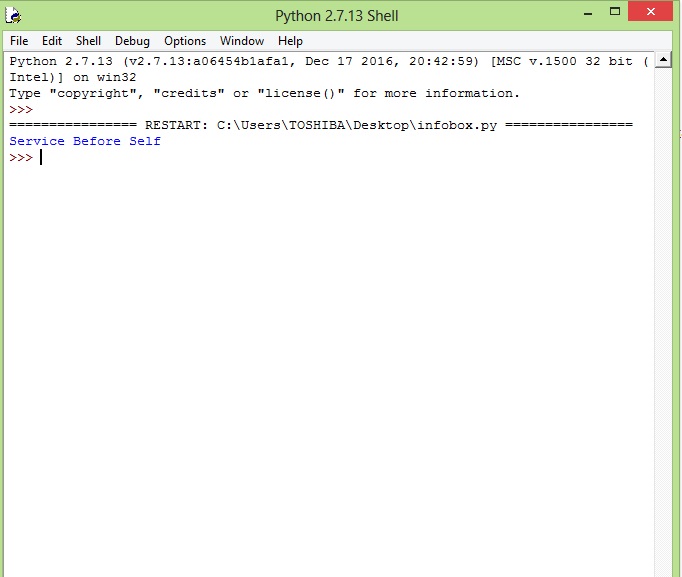
También puede modificar la URL.XPath para obtener diferentes secciones del cuadro de información.
Si desea obtener más información sobre el web scraping, vaya a estos enlaces:
1) Web Scraping 1
2) Web Scraping 2
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA