Si bien la distancia de edición mínima discutida en este artículo proporciona una buena lista de palabras posiblemente correctas, hay demasiadas palabras en el diccionario de inglés para considerar encontrar la distancia de edición entre todos los pares. Para simplificar la lista de palabras candidatas, la superposición de k-gramas se utiliza en los sistemas típicos de IR y NLP.
K-Gramos Los
K-gramas son subsecuencias de longitud k de una string. Aquí, k puede ser 1, 2, 3 y así sucesivamente. Para k=1, cada subsecuencia resultante se denomina “unigrama”; para k=2, un “bigrama”; y para k=3, un “trigrama”. Estos son los k-gramas más utilizados para la corrección ortográfica, pero el valor de k realmente depende de la situación y el contexto.
Como ejemplo, considere la string «catastrófica». En este caso,
- Unigramas: [“c”, “a”, “t”, “a”, “s”, “t”, “r”, “o”, “p”, “h”, “i”, “c” ]
- Bigramas: [“ca”, “at”, “ta”, “as”, “st”, “tr”, “ro”, “op”, “ph”, “hi”, “ic”]
- Trigramas: [“cat”, “ata”, “tas”, “ast”, “str”, “tro”, “rop”, “oph”, “phi”, “hic”]
Índice K-Gram
Un índice k-gram asigna un k-gram a una lista de publicaciones de todos los términos de vocabulario posibles que lo contienen. La siguiente figura muestra la lista de publicaciones de k-gramas correspondientes al bigrama “ur”.

Cabe destacar que la lista de publicaciones está ordenada alfabéticamente.
Corrección ortográfica
Mientras creamos la lista de candidatos de posibles palabras corregidas, podemos usar la «superposición de k-gramas» para encontrar las correcciones más probables.
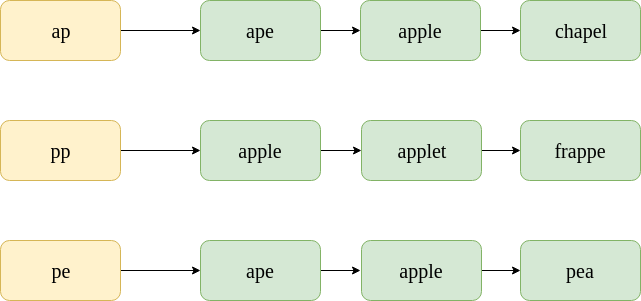
Considere la palabra mal escrita: «appe». Las listas de publicaciones para los bigramas que contiene se muestran a continuación. Tenga en cuenta que estos son solo subconjuntos de muestra de las listas de publicaciones; la lista de publicaciones reales, por supuesto, contendría miles de palabras.
Para encontrar la superposición de k-gram entre dos listas de publicaciones, usamos el coeficiente de Jaccard. Aquí, A y B son dos conjuntos (listas de publicaciones), A para la palabra mal escrita y B para la palabra corregida.
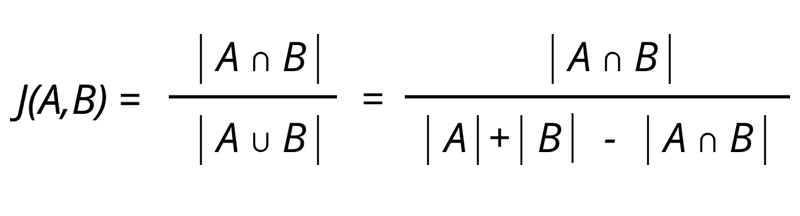
Ahora, considere algunos términos candidatos para la corrección ortográfica, a saber, «mono» y «manzana».
“simio”
Para encontrar el coeficiente de Jaccard , simplemente busque en las listas de publicaciones de todos los bigramas de “simio” y cuente las instancias en las que aparece “simio”.
En la primera lista de publicaciones, «ape» aparece 1 vez. En la segunda lista de publicaciones, “ape” aparece 0 veces. En la tercera lista de publicaciones, «simio» aparece 1 vez. Por lo tanto,  . Ahora, el núm. de bigramas en “appe” es 3, y el no. de bigramas en “ape” es 2. Por lo tanto,
. Ahora, el núm. de bigramas en “appe” es 3, y el no. de bigramas en “ape” es 2. Por lo tanto,  .
.
J(A,B) = 2/3 = 0,67.
«manzana» . Ahora, el núm. de bigramas en “appe” es 3, y el no. de bigramas en “manzana” es 4. Por lo tanto,
. Ahora, el núm. de bigramas en “appe” es 3, y el no. de bigramas en “manzana” es 4. Por lo tanto,  .
.
J(A, B) = 3/4 = 0,75.
Esto sugiere que «manzana» es una corrección más plausible. En la práctica, este método se utiliza para filtrar correcciones improbables.
Los pasos a seguir para la corrección ortográfica son:
- Encuentra los k-gramos de la palabra mal escrita.
- Para cada k-grama, explore linealmente la lista de publicaciones en el índice de k-gramas.
- Encuentre superposiciones de k-gramas después de haber escaneado linealmente las listas (sin complejidad de tiempo adicional porque estamos encontrando el coeficiente de Jaccard).
- Devuelve los términos con el máximo de superposiciones de k-gramo.
Publicación traducida automáticamente
Artículo escrito por Anannya Uberoi 1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA