La eliminación es una de las operaciones principales cuando se trata de análisis de datos. Muy a menudo vemos que un atributo particular en el marco de datos no es útil para nosotros mientras trabajamos en un análisis específico, sino que tenerlo puede generar problemas y cambios innecesarios en la predicción. Por ejemplo, si queremos analizar el IMC de los estudiantes de una escuela en particular, entonces no es necesario tener la columna/atributo de religión para los estudiantes, por lo que preferimos eliminar la columna. Veamos ahora la sintaxis de eliminar una columna de un marco de datos.
Sintaxis:
del df['column_name']
Veamos ahora algunos ejemplos:
Ejemplo 1:
Python3
# importing the module
import pandas as pd
# creating a DataFrame
my_df = {'Name': ['Rutuja', 'Anuja'],
'ID': [1, 2], 'Age': [20, 19]}
df = pd.DataFrame(my_df)
display("Original DataFrame")
display(df)
# deleting a column
del df['Age']
display("DataFrame after deletion")
display(df)
Producción :
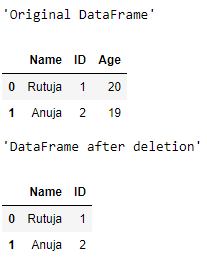
Tenga en cuenta que la columna «Edad» se ha eliminado.
Ejemplo 2:
Python3
# importing the module
import pandas as pd
# creating a DataFrame
my_df = {'Students': ['A', 'B', 'C', 'D'],
'BMI': [22.7, 18.0, 21.4, 24.1],
'Religion': ['Hindu', 'Islam',
'Christian', 'Sikh']}
df = pd.DataFrame(my_df)
display("Original DataFrame")
display(df)
# deleting a column
del df['Religion']
display("DataFrame after deletion")
display(df)
Producción :
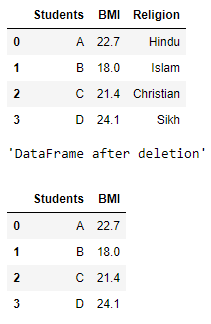
Tenga en cuenta que la columna innecesaria, ‘Religión’, se ha eliminado correctamente.
Publicación traducida automáticamente
Artículo escrito por rutujakawade24 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA