Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
Pandas dataframe.clip_upper()se utiliza para recortar valores en el umbral de entrada especificado. Usamos esta función para recortar todos los valores por encima del umbral del valor de entrada al valor de entrada especificado.
Sintaxis: DataFrame.clip_upper(umbral, eje=Ninguno, en el lugar=Falso)
Parámetros:
umbral: float o array_likefloat: cada valor se compara con el umbral.array-like: La forma del umbral debe coincidir con el objeto con el que se compara. Cuando self es una serie, el umbral debe ser la longitud. Cuando self es un DataFrame, el umbral debe ser 2-D y tener la misma forma que self para axis=None, o 1-D y la misma longitud que el eje que se compara.
eje : Alinee el objeto con el umbral a lo largo del eje dado.
inplace : si realizar la operación en el lugar en los datos.Devuelve: recortado: mismo tipo que la entrada
Ejemplo n.º 1: use clip_upper()la función para recortar los valores de un marco de datos por encima de un valor de umbral determinado.
# importing pandas as pd
import pandas as pd
# Creating a dataframe using dictionary
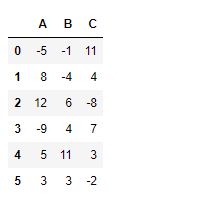
df = pd.DataFrame({"A":[-5, 8, 12, -9, 5, 3],
"B":[-1, -4, 6, 4, 11, 3],
"C":[11, 4, -8, 7, 3, -2]})
# Printing the data frame for visualization
df
Ahora recorte todos los valores por encima de 8 a 8.
# Clip all values below 2 df.clip_upper(8)
Producción :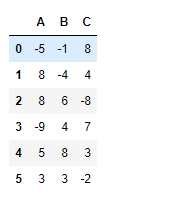
Ejemplo #2: use clip_upper()la función para recortar valores en un marco de datos con un valor específico para cada celda del marco de datos.
Para este propósito, podemos usar una array numpy, pero la forma de la array debe ser la misma que la del marco de datos.
# importing pandas as pd
import pandas as pd
# Creating a dataframe using dictionary
df = pd.DataFrame({"A":[-5, 8, 12, -9, 5, 3],
"B":[-1, -4, 6, 4, 11, 3],
"C":[11, 4, -8, 7, 3, -2]})
# upper limit for each individual column element.
limit = np.array([[10, 2, 8], [3, 5, 3], [2, 4, 6],
[11, 2, 3], [5, 2, 3], [4, 5, 3]])
# Print upper_limit
limit

Ahora aplique estos límites en el marco de datos.
# applying different limit value # for each cell in the dataframe df.clip_upper(limit)
Producción :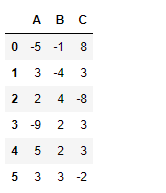
Cada valor de celda se ha recortado en función del límite superior correspondiente aplicado.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA