Supongamos que está creando una cuenta en Geekbook, desea ingresar un nombre de usuario genial, lo ingresó y recibió un mensaje, «El nombre de usuario ya está en uso». Agregaste tu fecha de nacimiento junto con el nombre de usuario, aún no hubo suerte. Ahora que también ha agregado su número de registro universitario, todavía tiene «El nombre de usuario ya está en uso». Es realmente frustrante, ¿no?
Pero, ¿ha pensado alguna vez en la rapidez con la que Geekbook verifica la disponibilidad del nombre de usuario al buscar millones de nombres de usuario registrados con él? Hay muchas maneras de hacer este trabajo:
- Búsqueda lineal : ¡Mala idea!
- Búsqueda binaria : almacene todos los nombres de usuario alfabéticamente y compare el nombre de usuario ingresado con el del medio en la lista. Si coincide, se toma el nombre de usuario; de lo contrario, averigüe si el nombre de usuario ingresado vendrá antes o después del medio y si vendrá después, descuide todos los nombres de usuario. antes del medio (inclusive). Ahora busque después del medio y repita este proceso hasta que obtenga una coincidencia o finalice la búsqueda sin ninguna coincidencia. Esta técnica es mejor y prometedora, pero aun así requiere varios pasos.
Pero debe haber algo mejor!!
Bloom Filter es una estructura de datos que puede hacer este trabajo.
Para comprender los filtros de floración, debe saber qué es hash . Una función hash toma entrada y genera un identificador único de longitud fija que se utiliza para identificar la entrada.
¿Qué es el filtro Bloom?
Un filtro Bloom es una estructura de datos probabilísticos eficiente en el espacio que se utiliza para probar si un elemento es miembro de un conjunto. Por ejemplo, verificar la disponibilidad del nombre de usuario es un problema de membresía establecido, donde el conjunto es la lista de todos los nombres de usuario registrados. El precio que pagamos por la eficiencia es que es de naturaleza probabilística, lo que significa que puede haber algunos resultados falsos positivos. Falso positivo significa que podría indicar que el nombre de usuario dado ya está en uso, pero en realidad no lo está.
Propiedades interesantes de los filtros Bloom
- A diferencia de una tabla hash estándar, un filtro Bloom de tamaño fijo puede representar un conjunto con un número arbitrariamente grande de elementos.
- Agregar un elemento nunca falla. Sin embargo, la tasa de falsos positivos aumenta constantemente a medida que se agregan elementos hasta que todos los bits del filtro se establecen en 1, momento en el que todas las consultas arrojan un resultado positivo.
- Los filtros Bloom nunca generan resultados falsos negativos , es decir, que le dicen que un nombre de usuario no existe cuando realmente existe.
- No es posible eliminar elementos del filtro porque, si eliminamos un solo elemento borrando bits en los índices generados por k funciones hash, podría provocar la eliminación de algunos otros elementos. Ejemplo: si eliminamos «geeks» (en el ejemplo que se muestra a continuación) borrando los bits 1, 4 y 7, podríamos terminar eliminando «nerd» también porque el bit en el índice 4 se convierte en 0 y el filtro Bloom afirma que «nerd» no es presente.
Funcionamiento del filtro Bloom
Un filtro de floración vacío es una array de bits de m bits, todos configurados en cero, como este:

Necesitamos k número de funciones hash para calcular los hash para una entrada dada. Cuando queremos agregar un elemento en el filtro, se establecen los bits en k índices h1(x), h2(x), … hk(x), donde los índices se calculan usando funciones hash.
Ejemplo: supongamos que queremos ingresar «geeks» en el filtro, estamos usando 3 funciones hash y una array de bits de longitud 10, todo configurado en 0 inicialmente. Primero calcularemos los hashes de la siguiente manera:
h1(“geeks”) % 10 = 1 h2(“geeks”) % 10 = 4 h3(“geeks”) % 10 = 7
Nota: Estas salidas son aleatorias solo como explicación.
Ahora pondremos los bits en los índices 1, 4 y 7 a 1
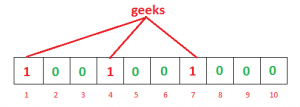
Nuevamente queremos ingresar «nerd», de manera similar, calcularemos hashes
h1(“nerd”) % 10 = 3 h2(“nerd”) % 10 = 5 h3(“nerd”) % 10 = 4
Establecer los bits en los índices 3, 5 y 4 a 1
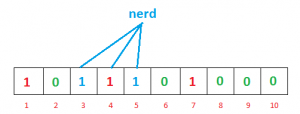
Ahora, si queremos comprobar si «geeks» está presente en el filtro o no. Haremos el mismo proceso pero esta vez en orden inverso. Calculamos los hashes respectivos usando h1, h2 y h3 y verificamos si todos estos índices están establecidos en 1 en la array de bits. Si todos los bits están configurados, podemos decir que «geeks» probablemente esté presente . Si alguno de los bits en estos índices es 0, entonces «geeks» definitivamente no está presente .
Falso positivo en filtros Bloom
La pregunta es por qué dijimos “probablemente presente” , por qué esta incertidumbre. Entendamos esto con un ejemplo. Supongamos que queremos comprobar si «gato» está presente o no. Calcularemos hashes usando h1, h2 y h3
h1(“cat”) % 10 = 1 h2(“cat”) % 10 = 3 h3(“cat”) % 10 = 7
Si verificamos la array de bits, los bits en estos índices se establecen en 1, pero sabemos que «gato» nunca se agregó al filtro. El bit en el índice 1 y 7 se configuró cuando agregamos «geeks» y el bit 3 se configuró cuando agregamos «nerd».
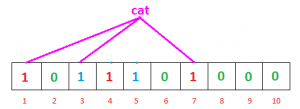
Por lo tanto, debido a que los bits en los índices calculados ya están establecidos por algún otro elemento, el filtro de floración afirma erróneamente que «gato» está presente y genera un resultado falso positivo. Dependiendo de la aplicación, podría ser una gran desventaja o estar relativamente bien.
Podemos controlar la probabilidad de obtener un falso positivo controlando el tamaño del filtro Bloom. Más espacio significa menos falsos positivos. Si queremos disminuir la probabilidad de un resultado falso positivo, tenemos que usar más funciones hash y una array de bits más grande. Esto agregaría latencia además del elemento y la verificación de membresía.
Operaciones que admite un filtro Bloom
- insert(x) : Para insertar un elemento en el filtro Bloom.
- lookup(x) : para verificar si un elemento ya está presente en Bloom Filter con una probabilidad falsa positiva.
NOTA: No podemos eliminar un elemento en Bloom Filter.
Probabilidad de falso positivo: sea m el tamaño de la array de bits, k el número de funciones hash y n el número de elementos esperados que se insertarán en el filtro, entonces la probabilidad de falso positivo p se puede calcular como:
![P=\left ( 1-\left [ 1- \frac {1}{m} \right ]^{kn} \right )^k](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-80f3fa1eb1567a5887d08c7cbddf639d_l3.png "Rendered by QuickLaTeX.com")
Tamaño de la array de bits: si se conoce el número esperado de elementos n y la probabilidad de falso positivo deseada es p , entonces el tamaño de la array de bits m se puede calcular como:

Número óptimo de funciones hash: El número de funciones hash k debe ser un número entero positivo. Si m es el tamaño de la array de bits y n es el número de elementos que se insertarán, entonces k se puede calcular como:

Eficiencia espacial
Si queremos almacenar una gran lista de elementos en un conjunto con el propósito de pertenecer al conjunto, podemos almacenarlo en hashmap , intentos o array simple o lista enlazada . Todos estos métodos requieren almacenar el elemento en sí, lo cual no es muy eficiente en memoria. Por ejemplo, si queremos almacenar «geeks» en hashmap, tenemos que almacenar la string real «geeks» como un par de valores clave {some_key: «geeks»}.
Los filtros Bloom no almacenan el elemento de datos en absoluto. Como hemos visto, utilizan una array de bits que permite la colisión hash. Sin la colisión hash, no sería compacto.
Elección de la función hash
La función hash utilizada en los filtros bloom debe ser independiente y distribuida uniformemente. Deben ser lo más rápido posible. Los hashes rápidos, simples y no criptográficos que son lo suficientemente independientes incluyen murmur , la serie FNV de funciones hash y los hashes de Jenkins .
La generación de hash es una operación importante en los filtros de floración. Las funciones hash criptográficas brindan estabilidad y garantía, pero son costosas en el cálculo. Con el aumento en el número de funciones hash k, el filtro de floración se vuelve lento. Aunque las funciones hash no criptográficas no brindan garantía, pero brindan una importante mejora del rendimiento.
Implementación básica de la clase Bloom Filter en Python3. Guárdelo como bloomfilter.py
Python
# Python 3 program to build Bloom Filter # Install mmh3 and bitarray 3rd party module first # pip install mmh3 # pip install bitarray import math import mmh3 from bitarray import bitarray class BloomFilter(object): ''' Class for Bloom filter, using murmur3 hash function ''' def __init__(self, items_count, fp_prob): ''' items_count : int Number of items expected to be stored in bloom filter fp_prob : float False Positive probability in decimal ''' # False possible probability in decimal self.fp_prob = fp_prob # Size of bit array to use self.size = self.get_size(items_count, fp_prob) # number of hash functions to use self.hash_count = self.get_hash_count(self.size, items_count) # Bit array of given size self.bit_array = bitarray(self.size) # initialize all bits as 0 self.bit_array.setall(0) def add(self, item): ''' Add an item in the filter ''' digests = [] for i in range(self.hash_count): # create digest for given item. # i work as seed to mmh3.hash() function # With different seed, digest created is different digest = mmh3.hash(item, i) % self.size digests.append(digest) # set the bit True in bit_array self.bit_array[digest] = True def check(self, item): ''' Check for existence of an item in filter ''' for i in range(self.hash_count): digest = mmh3.hash(item, i) % self.size if self.bit_array[digest] == False: # if any of bit is False then,its not present # in filter # else there is probability that it exist return False return True @classmethod def get_size(self, n, p): ''' Return the size of bit array(m) to used using following formula m = -(n * lg(p)) / (lg(2)^2) n : int number of items expected to be stored in filter p : float False Positive probability in decimal ''' m = -(n * math.log(p))/(math.log(2)**2) return int(m) @classmethod def get_hash_count(self, m, n): ''' Return the hash function(k) to be used using following formula k = (m/n) * lg(2) m : int size of bit array n : int number of items expected to be stored in filter ''' k = (m/n) * math.log(2) return int(k)
Probemos el filtro de floración. Guarde este archivo como bloom_test.py
Python
from bloomfilter import BloomFilter
from random import shuffle
n = 20 #no of items to add
p = 0.05 #false positive probability
bloomf = BloomFilter(n,p)
print("Size of bit array:{}".format(bloomf.size))
print("False positive Probability:{}".format(bloomf.fp_prob))
print("Number of hash functions:{}".format(bloomf.hash_count))
# words to be added
word_present = ['abound','abounds','abundance','abundant','accessible',
'bloom','blossom','bolster','bonny','bonus','bonuses',
'coherent','cohesive','colorful','comely','comfort',
'gems','generosity','generous','generously','genial']
# word not added
word_absent = ['bluff','cheater','hate','war','humanity',
'racism','hurt','nuke','gloomy','facebook',
'geeksforgeeks','twitter']
for item in word_present:
bloomf.add(item)
shuffle(word_present)
shuffle(word_absent)
test_words = word_present[:10] + word_absent
shuffle(test_words)
for word in test_words:
if bloomf.check(word):
if word in word_absent:
print("'{}' is a false positive!".format(word))
else:
print("'{}' is probably present!".format(word))
else:
print("'{}' is definitely not present!".format(word))
Producción
Size of bit array:124 False positive Probability:0.05 Number of hash functions:4 'war' is definitely not present! 'gloomy' is definitely not present! 'humanity' is definitely not present! 'abundant' is probably present! 'bloom' is probably present! 'coherent' is probably present! 'cohesive' is probably present! 'bluff' is definitely not present! 'bolster' is probably present! 'hate' is definitely not present! 'racism' is definitely not present! 'bonus' is probably present! 'abounds' is probably present! 'genial' is probably present! 'geeksforgeeks' is definitely not present! 'nuke' is definitely not present! 'hurt' is definitely not present! 'twitter' is a false positive! 'cheater' is definitely not present! 'generosity' is probably present! 'facebook' is definitely not present! 'abundance' is probably present!
Implementación de C++
Aquí está la implementación de una muestra de filtros Bloom con 4 funciones hash de muestra (k = 4) y el tamaño de la array de bits es 100.
C++
#include <bits/stdc++.h>
#define ll long long
using namespace std;
// hash 1
int h1(string s, int arrSize)
{
ll int hash = 0;
for (int i = 0; i < s.size(); i++)
{
hash = (hash + ((int)s[i]));
hash = hash % arrSize;
}
return hash;
}
// hash 2
int h2(string s, int arrSize)
{
ll int hash = 1;
for (int i = 0; i < s.size(); i++)
{
hash = hash + pow(19, i) * s[i];
hash = hash % arrSize;
}
return hash % arrSize;
}
// hash 3
int h3(string s, int arrSize)
{
ll int hash = 7;
for (int i = 0; i < s.size(); i++)
{
hash = (hash * 31 + s[i]) % arrSize;
}
return hash % arrSize;
}
// hash 4
int h4(string s, int arrSize)
{
ll int hash = 3;
int p = 7;
for (int i = 0; i < s.size(); i++) {
hash += hash * 7 + s[0] * pow(p, i);
hash = hash % arrSize;
}
return hash;
}
// lookup operation
bool lookup(bool* bitarray, int arrSize, string s)
{
int a = h1(s, arrSize);
int b = h2(s, arrSize);
int c = h3(s, arrSize);
int d = h4(s, arrSize);
if (bitarray[a] && bitarray[b] && bitarray
&& bitarray[d])
return true;
else
return false;
}
// insert operation
void insert(bool* bitarray, int arrSize, string s)
{
// check if the element in already present or not
if (lookup(bitarray, arrSize, s))
cout << s << " is Probably already present" << endl;
else
{
int a = h1(s, arrSize);
int b = h2(s, arrSize);
int c = h3(s, arrSize);
int d = h4(s, arrSize);
bitarray[a] = true;
bitarray[b] = true;
bitarray = true;
bitarray[d] = true;
cout << s << " inserted" << endl;
}
}
// Driver Code
int main()
{
bool bitarray[100] = { false };
int arrSize = 100;
string sarray[33]
= { "abound", "abounds", "abundance",
"abundant", "accessible", "bloom",
"blossom", "bolster", "bonny",
"bonus", "bonuses", "coherent",
"cohesive", "colorful", "comely",
"comfort", "gems", "generosity",
"generous", "generously", "genial",
"bluff", "cheater", "hate",
"war", "humanity", "racism",
"hurt", "nuke", "gloomy",
"facebook", "geeksforgeeks", "twitter" };
for (int i = 0; i < 33; i++) {
insert(bitarray, arrSize, sarray[i]);
}
return 0;
}
abound inserted abounds inserted abundance inserted abundant inserted accessible inserted bloom inserted blossom inserted bolster inserted bonny inserted bonus inserted bonuses inserted coherent inserted cohesive inserted colorful inserted comely inserted comfort inserted gems inserted generosity inserted generous inserted generously inserted genial inserted bluff is Probably already present cheater inserted hate inserted war is Probably already present humanity inserted racism inserted hurt inserted nuke is Probably already present gloomy is Probably already present facebook inserted geeksforgeeks inserted twitter inserted
Aplicaciones de los filtros Bloom
- Medium utiliza filtros de floración para recomendar publicaciones a los usuarios al filtrar las publicaciones que el usuario ha visto.
- Quora implementó un filtro de floración compartido en el backend de feed para filtrar las historias que la gente ha visto antes.
- El navegador web Google Chrome solía usar un filtro Bloom para identificar URL maliciosas
- Google BigTable, Apache HBase y Apache Cassandra, y Postgresql usan filtros Bloom para reducir las búsquedas en el disco de filas o columnas inexistentes
Referencias
- https://en.wikipedia.org/wiki/Bloom_filter
- https://blog.medium.com/que-son-los-filtros-de-floracion-1ec2a50c68ff
- https://www.quora.com/Cuáles-son-las-mejores-aplicaciones-de-los-filtros-Bloom
Este artículo es aportado por Atul Kumar y mejorado por Manoj Kumar . Si te gusta GeeksforGeeks y te gustaría contribuir, también puedes escribir un artículo usando write.geeksforgeeks.org o enviar tu artículo por correo a review-team@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA