RegexpParser o RegexpChunkRule.fromstring() no admiten todos los RegexpChunkRule classes. Entonces, necesitamos crearlos manualmente.
Este artículo se centra en 3 de tales clases:
ExpandRightRule: agrega palabras de resquicio (desbloqueadas) a la derecha de un fragmento.
ExpandLeftRule: agrega palabras con grietas (sin descifrar) a la izquierda de un fragmento.
For ExpandLeftRule y ExpandRightRule toma como parámetro: el patrón de grietas derecha e izquierda, respectivamente, que queremos agregar al principio y al final de la porción, respectivamente.
UnChunkRule: Desbloquea cualquier fragmento coincidente y se convierte en una grieta.
Código #1: Cómo funciona el código
# Loading Libraries
from nltk.chunk.regexp import ChunkRule, ExpandLeftRule
from nltk.chunk.regexp import ExpandRightRule, UnChunkRule
from nltk.chunk import RegexpChunkParser
# Initialising ChunkRule
ur = ChunkRule('<NN>', 'single noun')
# Initialising ExpandLeftRule
el = ExpandLeftRule('<DT>', '<NN>', 'get left determiner')
# Initialising ExpandRightRule
er = ExpandRightRule('<NN>', '<NNS>', 'get right plural noun')
# Initialising UnChunkRule
un = UnChunkRule('<DT><NN.*>*', 'unchunk everything')
chunker = RegexpChunkParser([ur, el, er, un])
sent = [('the', 'DT'), ('sushi', 'NN'), ('rolls', 'NNS')]
chunker.parse(sent)
Producción:
Tree('S', [('the', 'DT'), ('sushi', 'NN'), ('rolls', 'NNS')])
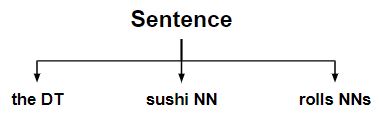
Nota: La salida es una oración plana ya que UnChunkRule deshizo el fragmento creado por las reglas anteriores.
¿Cómo funciona el material?
- Haz un trozo con un sustantivo.

- Expandiendo los determinantes de la izquierda a fragmentos que comienzan con sustantivo.
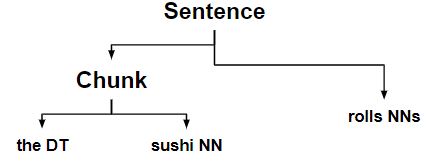
- Expandir los sustantivos plurales correctos a fragmentos que terminan con sustantivo.
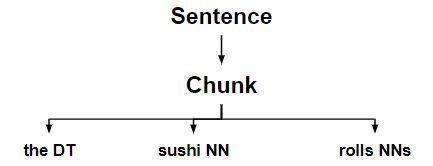
- Finalmente, desarmó cada fragmento que es un determinante + sustantivo + sustantivo plural, lo que da como resultado el árbol de oraciones original.
Código #2: Código paso a paso Explicando el diagrama.
# Loading Libraries
from nltk.chunk.regexp import ChunkRule, ExpandLeftRule
from nltk.chunk.regexp import ExpandRightRule, UnChunkRule
from nltk.chunk import RegexpChunkParser
from nltk.chunk.regexp import ChunkString
from nltk.tree import Tree
chunk_string = ChunkString(Tree('S', sent))
print ("Chunk String : ", chunk_string)
# Initialising ChunkRule
ur = ChunkRule('<NN>', 'single noun')
ur.apply(chunk_string)
print ("\nstep 1 : ", chunk_string)
# Initialising ExpandLeftRule
el = ExpandLeftRule('<DT>', '<NN>', 'get left determiner')
el.apply(chunk_string)
print ("step 2 : ", chunk_string)
# Initialising ExpandRightRule
er = ExpandRightRule('<NN>', '<NNS>', 'get right plural noun')
er.apply(chunk_string)
print ("step 3 : ", chunk_string)
# Initialising UnChunkRule
un = UnChunkRule('<DT><NN.*>*', 'unchunk everything')
un.apply(chunk_string)
print ("step 4 : ", chunk_string)
Producción :
Chunk String : <DT> <NN> <NNS>
step 1 : <DT> {<NN>} <NNS>
step 2 : {<DT> <NN>} <NNS>
step 3 : {<DT> <NN> <NNS>}
step 4 : <DT> <NN> <NNS>
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA