La serie Pandas es un ndarray unidimensional con etiquetas de eje. No es necesario que las etiquetas sean únicas, pero deben ser de tipo hashable. El objeto admite la indexación basada en enteros y etiquetas y proporciona una gran cantidad de métodos para realizar operaciones relacionadas con el índice.
La función Pandas Series.rank()calcula rangos de datos numéricos (1 a n) a lo largo del eje. A los valores iguales se les asigna un rango que es el promedio de los rangos de esos valores.
Sintaxis: Series.rank(axis=0, method=’average’, numeric_only=Ninguno, na_option=’keep’, ascendente=True, pct=False)
Parámetro:
eje: índice para
método de clasificación directo : {‘promedio’, ‘mín.’, ‘máx.’, ‘primero’, ‘denso’}
numeric_only: incluye solo datos flotantes, int, booleanos. Válido solo para objetos DataFrame o Panel
na_option : {‘keep’, ‘top’, ‘bottom’}
ascendente : Falso para rangos por alto (1) a bajo (N)
pct : Calcula el rango porcentual de los datosDevoluciones: rangos: mismo tipo que la persona que llama
Ejemplo #1: Use Series.rank()la función para clasificar los datos subyacentes del objeto Serie dado.
# importing pandas as pd import pandas as pd # Creating the Series sr = pd.Series([10, 25, 3, 11, 24, 6]) # Create the Index index_ = ['Coca Cola', 'Sprite', 'Coke', 'Fanta', 'Dew', 'ThumbsUp'] # set the index sr.index = index_ # Print the series print(sr)
Producción :

Ahora usaremos Series.rank()la función para devolver el rango de los datos subyacentes del objeto Serie dado.
# assign rank result = sr.rank() # Print the result print(result)
Producción :
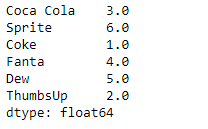
Como podemos ver en la salida, la Series.rank()función ha asignado un rango a cada elemento del objeto Serie dado.
Ejemplo #2: Use Series.rank()la función para clasificar los datos subyacentes del objeto Serie dado. Los datos dados también contienen algunos valores iguales.
# importing pandas as pd import pandas as pd # Creating the Series sr = pd.Series([10, 25, 3, 11, 24, 6, 25]) # Create the Index index_ = ['Coca Cola', 'Sprite', 'Coke', 'Fanta', 'Dew', 'ThumbsUp', 'Appy'] # set the index sr.index = index_ # Print the series print(sr)
Producción :
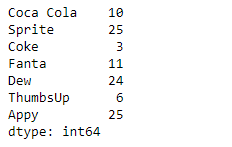
Ahora usaremos Series.rank()la función para devolver el rango de los datos subyacentes del objeto Serie dado.
# assign rank result = sr.rank() # Print the result print(result)
Producción :
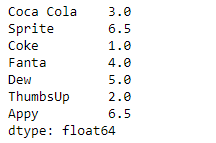
Como podemos ver en la salida, la Series.rank()función ha asignado un rango a cada elemento del objeto Serie dado. Observe que a los valores iguales se les ha asignado un rango que es el promedio de sus rangos.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA