En primer lugar, tenemos que entender qué son las variables categóricas en pandas. Los categóricos son los tipos de datos disponibles en la biblioteca pandas de python. Una variable categórica toma solo una categoría fija (generalmente un número fijo) de valores. Algunos ejemplos de variables categóricas son el género, el grupo sanguíneo, el idioma, etc. Un contraste principal con estas variables es que no se pueden realizar operaciones matemáticas con estas variables.
Se puede crear un marco de datos en pandas que consta de valores categóricos utilizando el constructor de marcos de datos y especificando dtype = ”category” .
Python3
# importing pandas as pd
import pandas as pd
# Create the dataframe
# with categorical variable
df = pd.DataFrame({'A': ['a', 'b', 'c',
'c', 'a', 'b'],
'B': [0, 1, 1, 0, 1, 0]},
dtype = "category")
# show the data types
df.dtypes
Producción:

Aquí una cosa importante es que las categorías generadas en cada columna no son las mismas, la conversión se realiza columna por columna como podemos ver aquí:
Producción:


Ahora, en algunos trabajos, necesitamos agrupar nuestros datos categóricos. Esto se hace usando el método groupby() dado en pandas. Devuelve todas las combinaciones de columnas groupby. Junto con groupyby, tenemos que pasar una función agregada para asegurarnos de qué base vamos a agrupar nuestras variables. Algunas funciones agregadas son mean(), sum(), count(), etc.
Ahora aplicando nuestro groupby() junto con la función count().
Python3
# initial state print(df) # counting number of each category print(df.groupby(['A']).count().reset_index())
Producción:
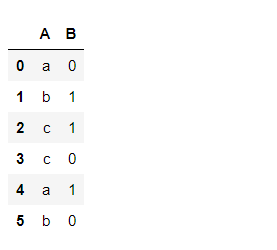
marco de datos

Agrupar por columna ‘A’
Ahora, un ejemplo más con la función mean(). Aquí la columna A se convierte en categórica y todas las demás son numéricas y la media se calcula de acuerdo con las categorías de la columna A y la columna B.
Python3
# importing pandas as pd
import pandas as pd
# Create the dataframe
df = pd.DataFrame({'A': ['a', 'b', 'c',
'c', 'a', 'b'],
'B': [0, 1, 1,
0, 1, 0],
'C':[7, 8, 9,
5, 3, 6]})
# change tha datatype of
# column 'A' into category
# data type
df['A'] = df['A'].astype('category')
# initial state
print(df)
# calculating mean with
# all combinations of A and B
print(df.groupby(['A','B']).mean().reset_index())
Producción:

Marco de datos

Agrupar por ambas columnas ‘A’ y ‘B’
Otras funciones agregadas también se implementan de la misma manera usando groupby() .