La tarea Dividir un marco de datos de Pandas es muy útil en el caso de dividir un conjunto de datos determinado en datos de entrenamiento y prueba con fines de capacitación y prueba en el campo del aprendizaje automático, la inteligencia artificial, etc. Veamos cómo dividir el marco de datos de pandas aleatoriamente en proporciones dadas. Para esta tarea, usaremos los métodos Dataframe.sample() y Dataframe.drop() del marco de datos de pandas juntos.
La sintaxis de estas funciones es la siguiente:
- Marco de datos.muestra()
Sintaxis: DataFrame.sample(n=Ninguno, frac=Ninguno, replace=False, weights=Ninguno, random_state=Ninguno, axis=Ninguno)
Tipo de devolución: un nuevo objeto del mismo tipo que el autor de la llamada que contiene n elementos muestreados aleatoriamente del objeto del autor de la llamada.
- Marco de datos.drop()
Sintaxis: DataFrame.drop(etiquetas=Ninguno, eje=0, índice=Ninguno, columnas=Ninguno, nivel=Ninguno, en el lugar=Falso, errores=’subir’)
Retorno: marco de datos con valores descartados.
Ejemplo: ahora, vamos a crear un marco de datos:
Python3
# Importing required libraries
import pandas as pd
record = {
'course_name': ['Data Structures', 'Python',
'Machine Learning', 'Web Development'],
'student_name': ['Ankit', 'Shivangi',
'Priya', 'Shaurya'],
'student_city': ['Chennai', 'Pune',
'Delhi', 'Mumbai'],
'student_gender': ['M', 'F',
'F', 'M'] }
# Creating a dataframe
df = pd.DataFrame(record)
# show the dataframe
df
Producción:
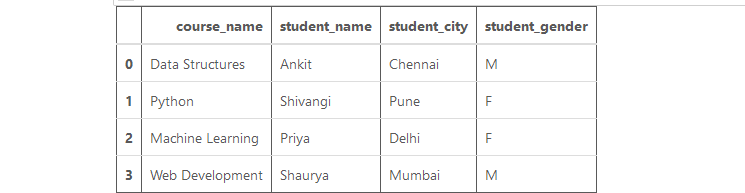
Marco de datos
Ejemplo 1: dividir un marco de datos al azar en una proporción de 1:1.
Python3
# Importing required libraries
import pandas as pd
record = {
'course_name': ['Data Structures', 'Python',
'Machine Learning', 'Web Development'],
'student_name': ['Ankit', 'Shivangi',
'Priya', 'Shaurya'],
'student_city': ['Chennai', 'Pune',
'Delhi', 'Mumbai'],
'student_gender': ['M', 'F',
'F', 'M'] }
# Creating a dataframe
df = pd.DataFrame(record)
# Creating a dataframe with 50%
# values of original dataframe
part_50 = df.sample(frac = 0.5)
# Creating dataframe with
# rest of the 50% values
rest_part_50 = df.drop(part_50.index)
print("\n50% of the given DataFrame:")
print(part_50)
print("\nrest 50% of the given DataFrame:")
print(rest_part_50)
Producción:

Dividir marco de datos
Ejemplo 2: dividir un marco de datos al azar en una proporción de 3:1.
Python3
# Importing required libraries
import pandas as pd
record = {
'course_name': ['Data Structures', 'Python',
'Machine Learning', 'Web Development'],
'student_name': ['Ankit', 'Shivangi',
'Priya', 'Shaurya'],
'student_city': ['Chennai', 'Pune',
'Delhi', 'Mumbai'],
'student_gender': ['M', 'F',
'F', 'M'] }
# Creating a dataframe
df = pd.DataFrame(record)
# Creating a dataframe with 75%
# values of original dataframe
part_75 = df.sample(frac = 0.75)
# Creating dataframe with
# rest of the 25% values
rest_part_25 = df.drop(part_75.index)
print("\n75% of the given DataFrame:")
print(part_75)
print("\nrest 25% of the given DataFrame:")
print(rest_part_25)
Producción:

Dividir marco de datos