La clasificación es una de las operaciones realizadas en el marco de datos en función de requisitos condicionales. Podemos ordenar el marco de datos alfabéticamente y también en orden numérico. En este artículo, veremos cómo ordenar Pandas Dataframe por varias columnas.
Método 1: Usar el método sort_values()
Sintaxis: df_name.sort_values(por column_name, axis=0, ascendente=True, inplace=False, kind=’quicksort’, na_position=’last’, ignore_index=False, key=Ninguno)
Parámetros:
por: nombre de la lista o columna por la que debe ordenarse
eje: eje a ordenar. (0 o ‘eje’ 1 o ‘columna’) por defecto es 0. (número de columna)
ascendente: Clasificación ascendente o descendente. Especifique listas de valores booleanos para varios órdenes de clasificación. La lista de valores booleanos debe coincidir con el no. de valores de ‘por’, es decir, column_names. Por defecto es verdadero.
inplace: Por defecto es falso. pero si su valor es verdadero, realiza la operación en el lugar, es decir, en el lugar adecuado.
tipo: Elección del algoritmo de clasificación como clasificación rápida. ordenar por combinación, ordenar por montón. por defecto es ordenación rápida.
Ordenar un marco de datos:
- Módulo de importación.
- Crear un marco de datos.
- Ahora, ordene un DataFrame usando la sintaxis anterior.
Creación de un marco de datos:
Python3
#import libraries
import numpy as np
import pandas as pd
# creating a dataframe
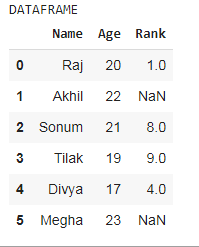
df = pd.DataFrame({'Name': ['Raj', 'Akhil', 'Sonum', 'Tilak', 'Divya', 'Megha'],
'Age': [20, 22, 21, 19, 17, 23],
'Rank': [1, np.nan, 8, 9, 4, np.nan]})
# printing the dataframe
print('DATAFRAME')
df
Producción:
Ejemplo 1:
Python3
# using the sorting function
print('SORTED DATAFRAME')
df.sort_values(by=['Age'], ascending=False)
Producción:
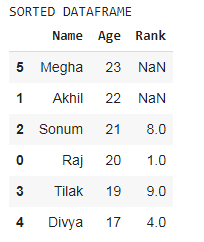
En el ejemplo anterior, el valor ascendente es falso, por lo que DataFrame se clasifica en orden descendente.
Ejemplo 2:
Python3
print('SORTED DATAFRAME')
df.sort_values(by = ['Rank', 'Age'], ascending = [True, False], na_position = 'first')
Producción:
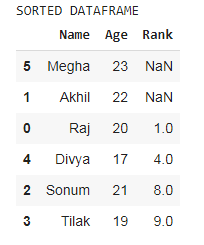
En el ejemplo anterior, el marco de datos se ordena de acuerdo con la columna ‘Clasificación’ y los valores nan se colocan en primer lugar.
Ejemplo 3:
Python3
print('SORTED DATAFRAME')
df.sort_values(by = ['Name', 'Rank'], axis=0, ascending=[False, True], inplace=False,
kind='quicksort', na_position='first', ignore_index=True, key=None)
Producción:
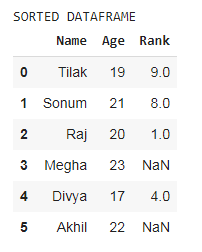
En el ejemplo anterior, el marco de datos se ordena según la columna ‘Clasificación’, pero el número de índice comienza con 0 porque le hemos dado el parámetro ‘ignore_index = True’. En otros ejemplos, el índice está desordenado porque no hemos proporcionado el parámetro ‘ignore_index’.
Método 2: Usar el método sort_index()
Sintaxis:
df_name.sort_index(axis=0, level=Ninguno, ascendente=True, inplace=False, kind=’quicksort’, na_position=’last’, sort_remaining=True, ignore_index=False, key=Ninguna)
Ejemplo 1: uso del marco de datos creado anteriormente
Python3
print('SORTED DATAFRAME')
df.sort_index(ascending=False)
Producción:
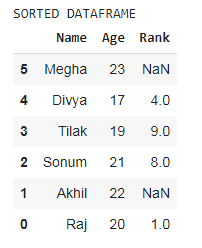
El índice del DataFrame está en orden descendente porque el valor del parámetro ascendente es False. El DataFrame se ordena por orden de índice.
Ejemplo 2:
Python3
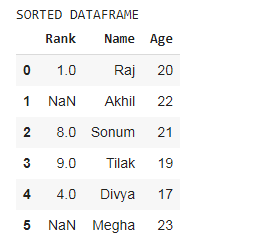
print('SORTED DATAFRAME')
df.sort_index(axis=1, ascending=False)
Producción:
Publicación traducida automáticamente
Artículo escrito por neelutiwari y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA