Pandas es una biblioteca de código abierto que se basa en la biblioteca numpy. Un marco de datos es una estructura de datos bidimensional, como si los datos estuvieran alineados de forma tabular en filas y columnas. El método DataFrame.sample() se puede utilizar para dividir el marco de datos.
Sintaxis: DataFrame.sample(n=Ninguno, frac=Ninguno, replace=False, weights=Ninguno, random_state=Ninguno, axis=Ninguno)
El atributo frac es el que define la fracción de Dataframe a utilizar. Por ejemplo, frac = 0.25 indica que se usará el 25% del marco de datos.
Ahora, vamos a crear un marco de datos:
Python3
# importing pandas as pd
import pandas as pd
# dictionary
cars = {
'Brand': ['Honda Civic', 'Toyota Corolla',
'Ford Focus', 'Audi A4', 'Maruti 800',
'Toyota Innova', 'Tata Safari', 'Maruti Zen',
'Maruti Omni', 'Honda Jezz'],
'Price': [22000, 25000, 27000, 35000,
20000, 25000, 31000, 23000,
26000, 25500]
}
# create the dataframe
df = pd.DataFrame(cars,
columns = ['Brand',
'Price'])
# show the dataframe
df
Producción:
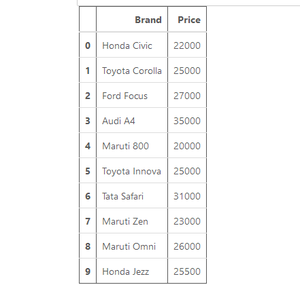
Ejemplo 1: Dividir un Dataframe dado en 60% y 40%.
Python3
# importing pandas as pd
import pandas as pd
# dictionary
cars = {
'Brand': ['Honda Civic', 'Toyota Corolla',
'Ford Focus', 'Audi A4', 'Maruti 800',
'Toyota Innova', 'Tata Safari', 'Maruti Zen',
'Maruti Omni', 'Honda Jezz'],
'Price': [22000, 25000, 27000, 35000,
20000, 25000, 31000, 23000,
26000, 25500]
}
# create the dataframe
df = pd.DataFrame(cars,
columns = ['Brand',
'Price'])
# Print the 60% of the dataframe
part_60 = df.sample(frac = 0.6)
print("\n 60% DataFrame:")
print(part_60)
# Print the 40% of the dataframe
part_40 = df.drop(part_60.index)
print("\n 40% DataFrame:")
print(part_40)
Producción:
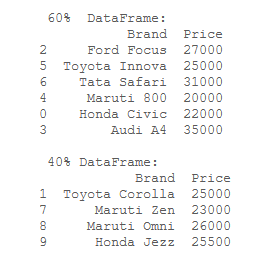
Ejemplo 2: Dividir un Dataframe dado en 80% y 20%.
Python3
# importing pandas as pd
import pandas as pd
# dictionary
cars = {
'Brand': ['Honda Civic', 'Toyota Corolla',
'Ford Focus', 'Audi A4', 'Maruti 800',
'Toyota Innova', 'Tata Safari', 'Maruti Zen',
'Maruti Omni', 'Honda Jezz'],
'Price': [22000, 25000, 27000, 35000,
20000, 25000, 31000, 23000,
26000, 25500]
}
# create the dataframe
df = pd.DataFrame(cars,
columns = ['Brand',
'Price'])
# Print the 80% of the dataframe
part_80 = df.sample(frac = 0.8)
print("\n 80% DataFrame:")
print(part_80)
# Print the 20% of the dataframe
part_20 = df.drop(part_80.index)
print("\n 20% DataFrame:")
print(part_20)
Producción:
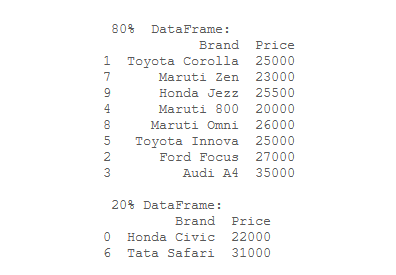
Publicación traducida automáticamente
Artículo escrito por shardul_singh_tomar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA