Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
Pandas dataframe.corr()se utiliza para encontrar la correlación por pares de todas las columnas en el marco de datos. Todos nalos valores se excluyen automáticamente. Para cualquier columna de tipo de datos no numérico en el marco de datos, se ignora.
Sintaxis: DataFrame.corr(self, method=’pearson’, min_periods=1)
Parámetros:
método:pearsoncoeficiente de correlación estándarkendall: coeficiente de correlación de Kendall Tauspearman: correlación de rango de Spearman
min_periods: número mínimo de observaciones requeridas por par de columnas para tener un resultado válido. Actualmente solo disponible para la correlación de Pearson y SpearmanDevoluciones: contar :y : DataFrame
Nota: La correlación de una variable consigo misma es 1.
Para obtener un enlace al archivo CSV utilizado en el código, haga clic aquí
Ejemplo #1: Use corr()la función para encontrar la correlación entre las columnas en el marco de datos usando el método ‘Pearson’.
# importing pandas as pd
import pandas as pd
# Making data frame from the csv file
df = pd.read_csv("nba.csv")
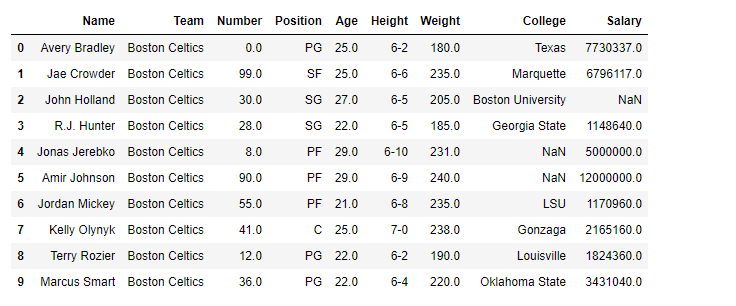
# Printing the first 10 rows of the data frame for visualization
df[:10]
Ahora use corr()la función para encontrar la correlación entre las columnas. Solo tenemos cuatro columnas numéricas en el marco de datos.
# To find the correlation among # the columns using pearson method df.corr(method ='pearson')
Producción :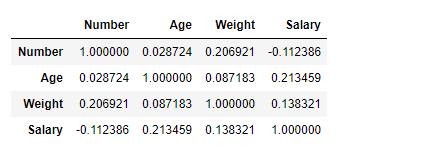
El marco de datos de salida se puede interpretar como para cualquier celda, la correlación de la variable de fila con la variable de columna es el valor de la celda. Como se mencionó anteriormente, la correlación de una variable consigo misma es 1. Por esa razón, todos los valores diagonales son 1.00
. Ejemplo n.º 2: Use corr()la función para encontrar la correlación entre las columnas en el marco de datos usando el método ‘kendall’.
# importing pandas as pd
import pandas as pd
# Making data frame from the csv file
df = pd.read_csv("nba.csv")
# To find the correlation among
# the columns using kendall method
df.corr(method ='kendall')
Producción :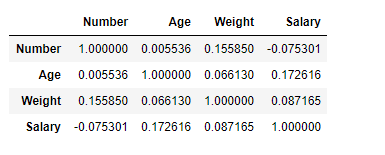
El marco de datos de salida se puede interpretar como para cualquier celda, la correlación de la variable de fila con la variable de columna es el valor de la celda. Como se mencionó anteriormente, que la correlación de una variable consigo misma es 1. Por esa razón todos los valores de la diagonal son 1.00.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA