Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
Usemos un conjunto de datos reales de TRAI para analizar las velocidades de datos móviles e intentemos ver las velocidades promedio para un operador o estado en particular en ese mes. Esto también mostrará la facilidad con la que se pueden usar Pandas en cualquier dato del mundo real para obtener resultados interesantes.
Acerca del conjunto de datos:
la Autoridad Reguladora de Telecomunicaciones de la India (TRAI) publica un conjunto de datos mensual de las velocidades de Internet que mide a través de la aplicación MySpeed (TRAI) . Esto incluye pruebas de velocidad iniciadas por el propio usuario o pruebas periódicas en segundo plano realizadas por la aplicación. Intentaremos analizar este conjunto de datos y ver las velocidades promedio para un operador o estado en particular en ese mes.
Inspeccionar la estructura sin procesar de los datos:
- Vaya al portal TRAI MySpeed y descargue el archivo csv del último mes en la sección Descargar . También puede descargar el archivo csv utilizado en este artículo: sept18_publish.csv o sept18_publish_drive.csv

- Abra este archivo de hoja de cálculo.
NOTA : Como el conjunto de datos es enorme, el software puede advertirle que no se pudieron cargar todas las filas. Esto esta bien. Además, si está utilizando Microsoft Excel, puede haber una advertencia sobre la apertura de un archivo SYLK. Este error podría ignorarse ya que es un error común en Excel.
Ahora, echemos un vistazo a la disposición de los datos.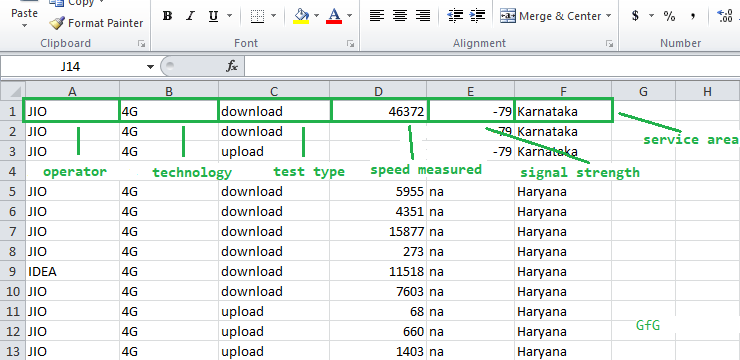
Nombres de columna en el conjunto de datos
La primera columna es del operador de red : JIO, Airtel, etc. La
segunda columna es de la tecnología de red : 3G o 4G .
La tercera columna es el tipo de prueba iniciada: carga o descarga .
La cuarta columna es la velocidad medida en kilobytes por segundo.
La quinta columna es la intensidad de la señal durante la medición.
La sexta columna es el Área de servicio local (LSA) , o el círculo donde se realizó la prueba: Delhi, Orissa, etc. Nos referiremos a esto simplemente como «estados».
NOTA: La intensidad de la señal puede tener na (Not Available)valores debido a que algunos dispositivos no pueden capturar la señal. Ignoraremos el uso de este parámetro en nuestros cálculos para simplificar las cosas. Sin embargo, podría agregarse fácilmente como una condición durante el filtrado.
Paquetes requeridos –
Pandas : un popular conjunto de herramientas de análisis de datos. Muy potente para procesar grandes conjuntos de datos.
Numpy : proporciona operaciones rápidas y eficientes en arrays de datos homogéneos. Usaremos esto junto con pandas y matplotlib.
Matplotlib : es una biblioteca de gráficos. Usaremos su función de trazado de barras para hacer gráficos de barras.
Vamos a empezar a analizar los datos.
Paso #1: Importe los paquetes y defina algunas constantes.
import pandas as pdimport numpy as npimport matplotlib.pyplot as plt # we will define some constants # name of the csv datasetDATASET_FILENAME = 'sept18_publish.csv' # define the operator to be filtered upon.CONST_OPERATOR = 'JIO' # define the state to be filtered upon.CONST_STATE = 'Delhi' # define the the technology to be filtered uponCONST_TECHNOLOGY = '4G' |
Paso #2: Defina algunas listas que almacenarán los resultados finales calculados, para que puedan pasarse fácilmente a la función de trazado de barras. El estado (u operador), la velocidad de descarga y la velocidad de carga se almacenarán en serie para que, para un índice, se pueda acceder al estado (u operador), sus correspondientes velocidades de descarga y carga.
Por ejemplo, final_states[2], final_download_speeds[2]y final_upload_speeds[2]dará los valores correspondientes para el 3er estado.
# define listsfinal_download_speeds = []final_upload_speeds = []final_states = []final_operators = [] |
Paso #3: Importe el archivo usando la read_csv()función Pandas y guárdelo en ‘df’. Esto creará un DataFrame del contenido csv sobre el que trabajaremos.
df = pd.read_csv(DATASET_FILENAME) # assign headers for each of the columns based on the data# this allows us to access columns easily df.columns = ['Service Provider', 'Technology', 'Test Type', 'Data Speed', 'Signal Strength', 'State'] |
Paso #4: Primero busquemos todos los estados y operadores únicos en este conjunto de datos y almacenémoslos en la lista de estados y operadores correspondientes.
Usaremos el unique()método del dataframe de Pandas.
# find and display the unique statesstates = df['State'].unique()print('STATES Found: ', states) # find and display the unique operatorsoperators = df['Service Provider'].unique()print('OPERATORS Found: ', operators) |
Producción:
STATES Found: ['Kerala' 'Rajasthan' 'Maharashtra' 'UP East' 'Karnataka' nan 'Madhya Pradesh' 'Kolkata' 'Bihar' 'Gujarat' 'UP West' 'Orissa' 'Tamil Nadu' 'Delhi' 'Assam' 'Andhra Pradesh' 'Haryana' 'Punjab' 'North East' 'Mumbai' 'Chennai' 'Himachal Pradesh' 'Jammu & Kashmir' 'West Bengal'] OPERATORS Found: ['IDEA' 'JIO' 'AIRTEL' 'VODAFONE' 'CELLONE']
Paso #5: Defina la función fixed_operator, que mantendrá el operador constante e iterará a través de todos los estados disponibles para ese operador. Podemos construir una función similar para un estado fijo.
# filter out the operator and technology
# first as this will be common for all
filtered = df[(df['Service Provider'] == CONST_OPERATOR)
& (df['Technology'] == CONST_TECHNOLOGY)]
# iterate through each of the states
for state in states:
# create new dataframe which contains
# only the data of the current state
base = filtered[filtered['State'] == state]
# filter only download speeds based on test type
down = base[base['Test Type'] == 'download']
# filter only upload speeds based on test type
up = base[base['Test Type'] == 'upload']
# calculate mean of speeds in Data Speed
# column using the Pandas.mean() method
avg_down = down['Data Speed'].mean()
# calculate mean of speeds
# in Data Speed column
avg_up = up['Data Speed'].mean()
# discard values if mean is not a number(nan)
# and append only the valid ones
if (pd.isnull(avg_down) or pd.isnull(avg_up)):
down, up = 0, 0
else:
final_states.append(state)
final_download_speeds.append(avg_down)
final_upload_speeds.append(avg_up)
# print output upto 2 decimal places
print(str(state) + ' -- Avg. Download: ' +
str('%.2f' % avg_down) +
' Avg. Upload: ' + str('%.2f' % avg_up))
Producción:
Kerala -- Avg. Download: 26129.27 Avg. Upload: 5193.46 Rajasthan -- Avg. Download: 27784.86 Avg. Upload: 5736.18 Maharashtra -- Avg. Download: 20707.88 Avg. Upload: 4130.46 UP East -- Avg. Download: 22451.35 Avg. Upload: 5727.95 Karnataka -- Avg. Download: 16950.36 Avg. Upload: 4720.68 Madhya Pradesh -- Avg. Download: 23594.85 Avg. Upload: 4802.89 Kolkata -- Avg. Download: 26747.80 Avg. Upload: 5655.55 Bihar -- Avg. Download: 31730.54 Avg. Upload: 6599.45 Gujarat -- Avg. Download: 16377.43 Avg. Upload: 3642.89 UP West -- Avg. Download: 23720.82 Avg. Upload: 5280.46 Orissa -- Avg. Download: 31502.05 Avg. Upload: 6895.46 Tamil Nadu -- Avg. Download: 16689.28 Avg. Upload: 4107.44 Delhi -- Avg. Download: 20308.30 Avg. Upload: 4877.40 Assam -- Avg. Download: 5653.49 Avg. Upload: 2864.47 Andhra Pradesh -- Avg. Download: 32444.07 Avg. Upload: 5755.95 Haryana -- Avg. Download: 7170.63 Avg. Upload: 2680.02 Punjab -- Avg. Download: 14454.45 Avg. Upload: 4981.15 North East -- Avg. Download: 6702.29 Avg. Upload: 2966.84 Mumbai -- Avg. Download: 14070.97 Avg. Upload: 4118.21 Chennai -- Avg. Download: 20054.47 Avg. Upload: 4602.35 Himachal Pradesh -- Avg. Download: 7436.99 Avg. Upload: 4020.09 Jammu & Kashmir -- Avg. Download: 8759.20 Avg. Upload: 4418.21 West Bengal -- Avg. Download: 16821.17 Avg. Upload: 3628.78
Graficando los datos –
Use el arange()método de Numpy que devuelve valores espaciados uniformemente dentro de un intervalo determinado. Aquí, pasando la longitud de la final_stateslista, obtenemos valores desde 0 hasta el número de estados en la lista como [0, 1, 2, 3…]
Luego podemos usar estos índices para trazar una barra en esa ubicación. La segunda barra se traza compensando la ubicación de la primera barra por el ancho de la barra.
fig, ax = plt.subplots()
# the width of each bar
bar_width = 0.25
# opacity of each bar
opacity = 0.8
# store the positions
index = np.arange(len(final_states))
# the plt.bar() takes in the position
# of the bars, data to be plotted,
# width of each bar and some other
# optional parameters, like the opacity and colour
# plot the download bars
bar_download = plt.bar(index, final_download_speeds,
bar_width, alpha=opacity,
color='b', label='Download')
# plot the upload bars
bar_upload = plt.bar(index + bar_width, final_upload_speeds,
bar_width, alpha=opacity, color='g',
label='Upload')
# title of the graph
plt.title('Avg. Download/Upload speed for '
+ str(CONST_OPERATOR))
# the x-axis label
plt.xlabel('States')
# the y-axis label
plt.ylabel('Average Speeds in Kbps')
# the label below each of the bars,
# corresponding to the states
plt.xticks(index + bar_width, final_states, rotation=90)
# draw the legend
plt.legend()
# make the graph layout tight
plt.tight_layout()
# show the graph
plt.show()
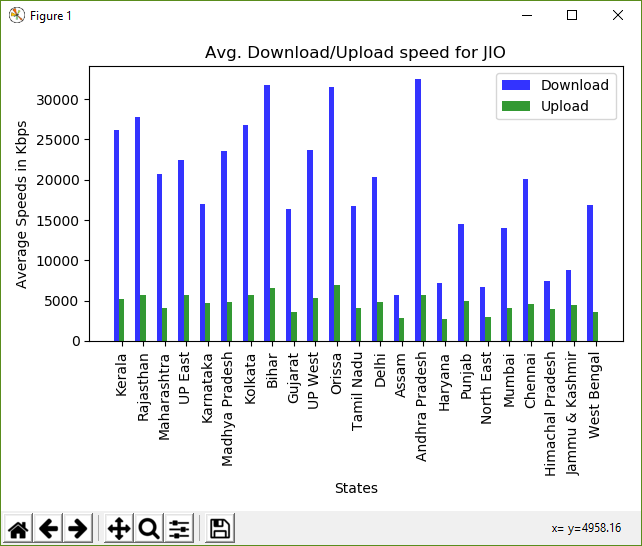
Diagrama de barras de las velocidades calculadas
Comparando datos de dos meses –
Tomemos también algunos datos de otro mes y grafiquémoslos juntos para observar la diferencia en las velocidades de datos.
Para este ejemplo, el conjunto de datos del mes anterior será el mismo sept18_publish.csv y el conjunto de datos del próximo mes será oct18_publish.csv .
Sólo tenemos que ejecutar los mismos pasos de nuevo. Leer los datos de otro mes. Fíltrelo en marcos de datos posteriores y luego trácelo usando un método ligeramente diferente. Durante el trazado de las barras, incrementaremos las barras 3 y 4 (correspondientes a la carga y descarga del segundo archivo) en 2 y 3 veces el ancho de la barra, para que estén en sus posiciones correctas.
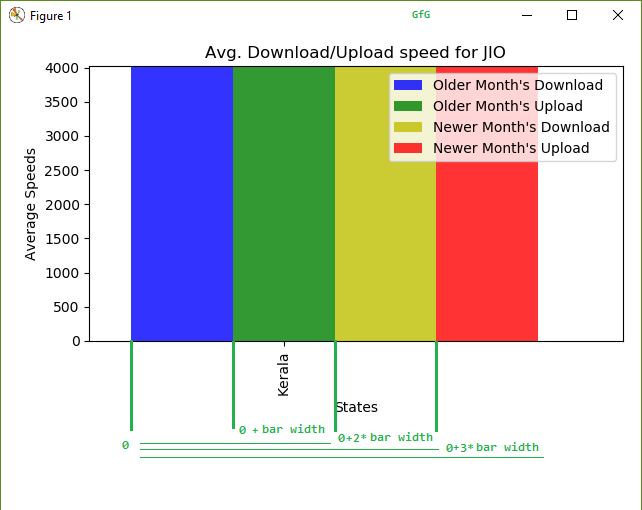
Lógica de compensación al trazar 4 barras
A continuación se muestra la implementación para comparar 2 meses de datos:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import time
# older month
DATASET_FILENAME = 'https://myspeed.trai.gov.in/download/sept18_publish.csv'
# newer month
DATASET_FILENAME2 = 'https://myspeed.trai.gov.in/download/oct18_publish.csv'
CONST_OPERATOR = 'JIO'
CONST_STATE = 'Delhi'
CONST_TECHNOLOGY = '4G'
# read file with Pandas and store as Dataframe
df = pd.read_csv(DATASET_FILENAME)
df2 = pd.read_csv(DATASET_FILENAME2)
# assign column names
df.columns = ['Service Provider', 'Technology', 'Test Type',
'Data Speed', 'Signal Strength', 'State']
df2.columns = ['Service Provider', 'Technology', 'Test Type',
'Data Speed', 'Signal Strength', 'State']
# find and display the unique states
states = df['State'].unique()
print('STATES Found: ', states)
# find and display the unique operators
operators = df['Service Provider'].unique()
print('OPERATORS Found: ', operators)
# define lists
final_download_speeds = []
final_upload_speeds = []
final_download_speeds_second =[]
final_upload_speeds_second = []
final_states = []
final_operators = []
# assign column names to the data
df.columns = ['Service Provider', 'Technology', 'Test Type',
'Data Speed', 'Signal Strength', 'State']
df2.columns = ['Service Provider', 'Technology', 'Test Type',
'Data Speed', 'Signal Strength', 'State']
print('\n\nComparing data for' + str(CONST_OPERATOR))
filtered = df[(df['Service Provider'] == CONST_OPERATOR)
& (df['Technology'] == CONST_TECHNOLOGY)]
filtered2 = df2[(df2['Service Provider'] == CONST_OPERATOR)
& (df2['Technology'] == CONST_TECHNOLOGY)]
for state in states:
base = filtered[filtered['State'] == state]
# calculate mean of download speeds
avg_down = base[base['Test Type'] ==
'download']['Data Speed'].mean()
# calculate mean of upload speeds
avg_up = base[base['Test Type'] ==
'upload']['Data Speed'].mean()
base2 = filtered2[filtered2['State'] == state]
# calculate mean of download speeds
avg_down2 = base2[base2['Test Type'] ==
'download']['Data Speed'].mean()
# calculate mean of upload speeds
avg_up2 = base2[base2['Test Type'] ==
'upload']['Data Speed'].mean()
# discard values if mean is not a number(nan)
# and append only the needed speeds
if (pd.isnull(avg_down) or pd.isnull(avg_up) or
pd.isnull(avg_down2) or pd.isnull(avg_up2)):
avg_down = 0
avg_up = 0
avg_down2 = 0
avg_up2 = 0
else:
final_states.append(state)
final_download_speeds.append(avg_down)
final_upload_speeds.append(avg_up)
final_download_speeds_second.append(avg_down2)
final_upload_speeds_second.append(avg_up2)
print('Older: ' + str(state) + ' -- Download: ' +
str('%.2f' % avg_down) + ' Upload: ' +
str('%.2f' % avg_up))
print('Newer: ' + str(state) + ' -- Download: ' +
str('%.2f' % avg_down2) + ' Upload: ' +
str('%.2f' % avg_up2))
# plot bargraph
fig, ax = plt.subplots()
index = np.arange(len(final_states))
bar_width = 0.2
opacity = 0.8
rects1 = plt.bar(index, final_download_speeds,
bar_width, alpha=opacity, color='b',
label='Older Month\'s Download')
rects2 = plt.bar(index + bar_width, final_upload_speeds,
bar_width, alpha=opacity, color='g',
label='Older Month\'s Upload')
rects3 = plt.bar(index + 2 * bar_width, final_download_speeds_second,
bar_width, alpha=opacity, color='y',
label='Newer Month\'s Download')
rects4 = plt.bar(index + 3 * bar_width, final_upload_speeds_second,
bar_width, alpha=opacity, color='r',
label='Newer Month\'s Upload')
plt.xlabel('States')
plt.ylabel('Average Speeds')
plt.title('Avg. Download/Upload speed for '
+ str(CONST_OPERATOR))
plt.xticks(index + bar_width, final_states, rotation=90)
plt.legend()
plt.tight_layout()
plt.show()
Producción:
STATES Found: ['Kerala' 'Rajasthan' 'Maharashtra' 'UP East' 'Karnataka' nan 'Madhya Pradesh' 'Kolkata' 'Bihar' 'Gujarat' 'UP West' 'Orissa' 'Tamil Nadu' 'Delhi' 'Assam' 'Andhra Pradesh' 'Haryana' 'Punjab' 'North East' 'Mumbai' 'Chennai' 'Himachal Pradesh' 'Jammu & Kashmir' 'West Bengal'] OPERATORS Found: ['IDEA' 'JIO' 'AIRTEL' 'VODAFONE' 'CELLONE']
Comparing data forJIO Older: Kerala -- Download: 26129.27 Upload: 5193.46 Newer: Kerala -- Download: 18917.46 Upload: 4290.13 Older: Rajasthan -- Download: 27784.86 Upload: 5736.18 Newer: Rajasthan -- Download: 13973.66 Upload: 4721.17 Older: Maharashtra -- Download: 20707.88 Upload: 4130.46 Newer: Maharashtra -- Download: 26285.47 Upload: 5848.77 Older: UP East -- Download: 22451.35 Upload: 5727.95 Newer: UP East -- Download: 24368.81 Upload: 6101.20 Older: Karnataka -- Download: 16950.36 Upload: 4720.68 Newer: Karnataka -- Download: 33521.31 Upload: 5871.38 Older: Madhya Pradesh -- Download: 23594.85 Upload: 4802.89 Newer: Madhya Pradesh -- Download: 16614.49 Upload: 4135.70 Older: Kolkata -- Download: 26747.80 Upload: 5655.55 Newer: Kolkata -- Download: 23761.85 Upload: 5153.29 Older: Bihar -- Download: 31730.54 Upload: 6599.45 Newer: Bihar -- Download: 34196.09 Upload: 5215.58 Older: Gujarat -- Download: 16377.43 Upload: 3642.89 Newer: Gujarat -- Download: 9557.90 Upload: 2684.55 Older: UP West -- Download: 23720.82 Upload: 5280.46 Newer: UP West -- Download: 35035.84 Upload: 5797.93 Older: Orissa -- Download: 31502.05 Upload: 6895.46 Newer: Orissa -- Download: 31826.96 Upload: 6968.59 Older: Tamil Nadu -- Download: 16689.28 Upload: 4107.44 Newer: Tamil Nadu -- Download: 27306.54 Upload: 5537.58 Older: Delhi -- Download: 20308.30 Upload: 4877.40 Newer: Delhi -- Download: 25198.16 Upload: 6228.81 Older: Assam -- Download: 5653.49 Upload: 2864.47 Newer: Assam -- Download: 5243.34 Upload: 2676.69 Older: Andhra Pradesh -- Download: 32444.07 Upload: 5755.95 Newer: Andhra Pradesh -- Download: 19898.16 Upload: 4002.25 Older: Haryana -- Download: 7170.63 Upload: 2680.02 Newer: Haryana -- Download: 8496.27 Upload: 2862.61 Older: Punjab -- Download: 14454.45 Upload: 4981.15 Newer: Punjab -- Download: 17960.28 Upload: 4885.83 Older: North East -- Download: 6702.29 Upload: 2966.84 Newer: North East -- Download: 6008.06 Upload: 3052.87 Older: Mumbai -- Download: 14070.97 Upload: 4118.21 Newer: Mumbai -- Download: 26898.04 Upload: 5539.71 Older: Chennai -- Download: 20054.47 Upload: 4602.35 Newer: Chennai -- Download: 36086.70 Upload: 6675.70 Older: Himachal Pradesh -- Download: 7436.99 Upload: 4020.09 Newer: Himachal Pradesh -- Download: 9277.45 Upload: 4622.25 Older: Jammu & Kashmir -- Download: 8759.20 Upload: 4418.21 Newer: Jammu & Kashmir -- Download: 9290.38 Upload: 4533.08 Older: West Bengal -- Download: 16821.17 Upload: 3628.78 Newer: West Bengal -- Download: 9763.05 Upload: 2627.28
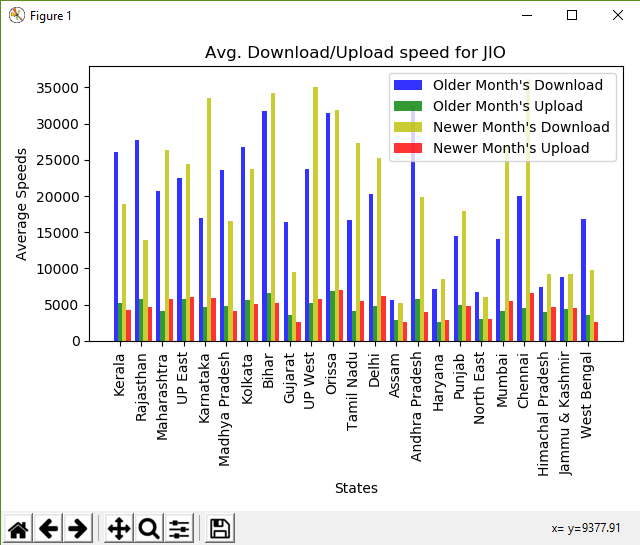
Diagrama de barras de la salida
Acabamos de aprender a analizar algunos datos del mundo real y sacar algunas observaciones interesantes de ellos. Pero tenga en cuenta que no todos los datos estarán tan bien formateados y tan fáciles de manejar, Pandas hace que sea increíblemente fácil trabajar con tales conjuntos de datos.
Publicación traducida automáticamente
Artículo escrito por sayantanm19 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA