Requisito previo: Números aleatorios en Python
El siguiente artículo muestra cómo se puede usar Python para detectar una hebra de ADN mutada.
Funciones utilizadas
- generateDNASequence(): este método genera una hebra de ADN aleatoria de 40 caracteres de longitud utilizando la lista de bases de ADN A,C,G,T. Este método devuelve la string de ADN generada.
- applyGammaRadiation(): este método toma la hebra de ADN generada por el método anterior como parámetro de entrada y luego altera la hebra en una posición aleatoria solo si la probabilidad de mutación, que también se genera aleatoriamente, es superior al 50 %. La base de ADN en la posición elegida debe ser diferente de la base de ADN con la que se reemplaza. Este método devuelve la string de ADN alterada.
- detectMutation(): este método toma como entrada la hebra de ADN original y alterada y comprueba si las dos strings están alteradas. Si se alteran las strings, devuelve la posición de la base de ADN alterada.
Empezando
Se siguen los siguientes pasos para lograr nuestra funcionalidad requerida:
- Importar biblioteca aleatoria
- La función generateDNASequence() se utiliza para generar hebras de ADN. La hebra de ADN se genera eligiendo al azar caracteres de la lista de opciones disponibles. Cuando la longitud de la string llega a 40, el bucle se completa y se devuelve la hebra de ADN.
- La función applyGammaRadiation() para alterar strings de ADN. La posibilidad de mutación se genera aleatoriamente. Si la posibilidad de mutación generada aleatoriamente es mayor que 50, entonces se produce la mutación, de lo contrario, no se produce la mutación. Si ocurriera una mutación, la posición de la mutación se elige al azar.
- A continuación, los caracteres de la string de ADN se convierten en una lista.
- Se obtiene el carácter en la posición de mutación. Dado que el carácter obtenido debe ser diferente del que lo reemplaza, eliminamos el carácter obtenido de la lista de opciones disponibles para elegir otro carácter en su lugar. El nuevo carácter o base de ADN se elige de la lista.
- Los caracteres originales de la string de ADN se agregan nuevamente a una nueva lista. La nueva base/personaje se establece en la posición mutada.
- Los caracteres en la lista cl se convierten nuevamente en strings usando join(). Esta es la nueva string de ADN mutado.
- Si no se produce ninguna mutación, el ADN original es el mismo que el ADN mutado.
- Finalmente se devuelve el ADN mutado/no mutado.
- Luego, la función detectMutation() se usa para detectar la mutación. En esta función, x e y toman cada carácter en dna y cdna para comparar carácter por carácter. Si el carácter en el mismo índice coincide, entonces el conteo aumenta. En caso de desajuste, el bucle se rompe.
- El valor de conteo apunta al índice antes de la posición de mutación. Si el recuento = 40, significa que todos los caracteres de las 2 hebras coinciden, por lo tanto, no hay mutación. Si el recuento es inferior a 40, significa que se ha producido una mutación.
A continuación se muestra la implementación.
Python3
# import random library
import random
# function to generate dna strands
def generateDNASequence():
# list of available DNA bases
l = ['C', 'A', 'G', 'T']
res = ""
for i in range(0, 40):
# creating the DNA strand by appending
# random characters from the list
res = res + random.choice(l)
return res
# function to alter dna strands
def applyGammaRadiation(dna):
# possibility of mutation is generated randomly
pos = random.randint(1, 100)
cdna = ''
# list of available DNA bases
l = ['C', 'A', 'G', 'T']
# if the possibility of mutation generated randomly
# is >50 then mutation happens
if(pos > 50):
# the position where mutation will take place
# is chosen randomly
changepos = random.randint(0, 39)
dl = []
# the characters in DNA strand is converted to list
dl[:0] = dna
# the character at the determined mutation position
# is fetched.
ch = "" + dl[changepos]
# since the fetched character should be different from
# the one replacing it we remove the fetched character
# from the list of available choices for choosing another
# character in its place
l.remove(ch)
# the new character or DNA base is chosen from the list
ms = random.choice(l)
cl = []
# DNA strand characters are again appended to a new list
cl[:0] = dna
# the new base in the mutated position is set
cl[changepos] = ms
# the characters in the cl list is converted to string again
# this is the new mutated DNA string
cdna = ''.join([str(e) for e in cl])
# if possibility of mutation is less than 50% then no
# mutation happens
else:
# if no mutation occurs original dna is same as mutated dna
cdna = dna
return cdna
# function to detect mutation
def detectMutation(dna, cdna):
count = 0
# x and y take each character in dna and cdna
# for character by character comparison
for x, y in zip(dna, cdna):
# if the character at the same index match
# then the count is increased
if x == y:
count = count + 1
# incase of mismatch the loop is broken
else:
break
# the count value points to the index before the
# position of mutation
return count
dna = generateDNASequence()
print(dna+" (Original DNA)")
cdna = applyGammaRadiation(dna)
print(cdna+" (DNA after radiation)")
count = detectMutation(dna, cdna)
# if count=40 it means all the characters of the 2 strands match
# hence no mutation
if count == 40:
print("No Mutation detected")
# if count is less than 40
# it means mutation has occurred
else:
# ^ denotes the position of mutation
pos = "^"
print(pos.rjust(count+1))
print("Mutation detected at pos = ", (count+1))
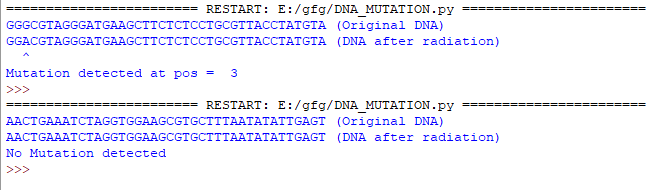
Producción
Publicación traducida automáticamente
Artículo escrito por Shreyasi_Chakraborty y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA