Dado un archivo de entrada, con las columnas Departamento y Nombre, realice una operación para convertir los valores de columna en filas. El nombre contiene valores separados por tubería que pertenecen a un departamento en particular identificado por la columna Dept.
Conjunto de datos adjunto: emp_data
Ejemplos:
Input: dept, name 10, Vivek|John 20, Ritika|Shubham|Nitin 30, Vishakha|Ankit Output: dept, name 10, Vivek 10, John 20, Ritika 20, Shubham 20, Nitin 30, Vishakha 30, Ankit
Método 1: vía pythonica
Python
# Reading Data From the text
# file
data = pd.read_csv(r'GFG.txt')
# create new data frame with
# split value columns separates
# data into three columns as per
# separator mentioned
new = data["name"].str.split("|",expand = True)
# making separate first name column
# from new data frame assign columnn
# values to dataframe new columns
# named as name*
data["Name1"] = new[0]
data["Name2"] = new[1]
data["Name3"] = new[2]
# Dropping old Name columns
data.drop(columns =["name"], inplace = True)
# create separate dataframes with two
# columns id,name
d_name1 = data[['dept','Name1']]
d_name2 = data[['dept','Name2']]
d_name3 = data[['dept','Name3']]
# perform concat/unions operation for
# vertical merging of dataframes
union_df=pd.concat([d_name1,d_name2,d_name3],ignore_index=True)
union_df.fillna('',inplace=True)
# concatenate values of series into one
# series "name"
union_df['name'] = union_df['Name1'].astype(str)+union_df['Name2'].astype(str)+union_df['Name3'].astype(str)
# drop column names
union_df.drop(['Name1','Name2','Name3'],axis=1,inplace=True)
# drop rows having empty values
final_df=union_df[union_df['name']!='']
# sort the dataframe data by dept values
final_df.sort_values('dept')
Producción: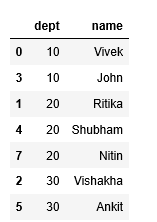
Nota: La deficiencia del método anterior es cuando hay más de 3 nombres separados por |
Método 2: Explorando Pandas
Python
emp_df = pd.read_csv(r'GFG.txt')
# split column data on basis of separator
# convert it into list using to_list
# stack method performs transpose operation
# to the data
emp_df1 = pd.DataFrame(emp_df.name.str.split('|').to_list(),
index = emp_df.dept).stack()
emp_df1 = emp_df1.reset_index([0, 'dept'])
emp_df1.columns =['Dept', 'Name']
emp_df1
Producción:
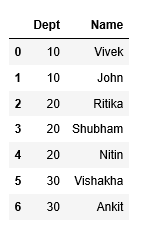
Método 3: al estilo de los pandas: explotar()
Python
df = pd.read_csv(r'GFG.txt')
# separate values using split()
# transpose is performed by explode
# function explode function overcomes
# the method1 shortcomings incase we
# have many columns we explode will do
# the task in no time and with no hassle
df1 = df.assign(name = df['name'].str.split('|')).explode('name')
df1
Producción: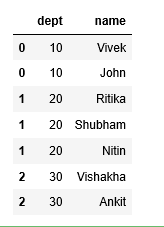
Publicación traducida automáticamente
Artículo escrito por vivekchaudhary90 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA